 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadBalance: A Plug-and-Play Unified Global Geometric Prior Framework for Generalizable Biomedical Segmentation
Jun 14, 2026Precise biomedical image segmentation is crucial for clinical diagnosis. Geometric cues (e.g., boundary, shape, and topology) can improve structural consistency, yet most are task-specific and lack a unified geometric foundation that generalizes across organs and modalities. We are motivated by the observation that several medical segmentation targets can be approximated as globally near-convex shapes. A convex region is one in which any two interior points can be connected by a line segment entirely contained within the region. In practice, medical targets may exhibit small local concavities or boundary irregularities; we refer to such globally convex-like shapes as near-convex. Motivated by this, we derive Hadwiger Shape Priors from Hadwiger's theorem as an interpretable global regularizer using three 2D measures: area A, perimeter P, and Euler characteristic chi, enabling transfer across organs and modalities. However, because medical datasets are shape-heterogeneous, enforcing near-convex priors uniformly can over-regularize non-convex anatomy with significant concavities, washing out concavities and fine details and degrading segmentation accuracy. To address this challenge, we propose Conflict-Aware Objective Balancing (CAOB), which integrates shape priors with segmentation in a gradient-aware manner. For each prior, CAOB removes only the gradient component that conflicts with segmentation while preserving the remaining aligned component, and adaptively regulates objective influences to prevent prior dominance. This enables stable use of shape priors on shape-heterogeneous data without erasing genuine concavities or fine structural details. We call this plug-and-play framework HadBalance.
Disentangled Fine-Grained Prototype Learning for Incomplete Image-Tabular Classification
Jun 03, 2026The missing-modality problem poses a significant challenge in image-tabular multimodal learning across a wide range of multimedia applications, including product understanding, recommendation systems, and medical diagnosis. This challenge is particularly pronounced when the two modalities are highly heterogeneous, as images and tabular attributes differ substantially in their semantic granularity and data distributions. Existing methods learn modality-invariant representations through disentanglement and alignment over global token-averaged features, capturing only coarse cross-modal consistency and overlooking fine-grained semantic and distributional misalignment, which hampers the exploitation of complementary cues under missing modalities. To address this, we propose DFPL, a novel framework for fine-grained prototype learning. Specifically, Shared-Specific Prototype Modeling (SSPM) extracts compact and diverse shared and modality-specific prototypes, and further performs prototype-level disentanglement to suppress redundant intra-modality correlations. Additionally, we propose a Prototype-guided Fine-grained Alignment (PFA) module that jointly enforces prototype-level distribution matching and prototype-to-class semantic alignment within a unified prototype space, thereby preserving both fine-grained distributional and semantic consistency across modalities. We further introduce a Class-aware Multi-scale Aggregation (CMA) module to adaptively aggregate shared semantics and modality-specific characteristics from global and prototype levels for robust predictions. Extensive experiments on three diverse image-tabular benchmarks demonstrate the superiority of our method compared to the previous approaches under various missing-modality settings. Code will be made publicly available.
Interpreting V1 Population Activity via Image-Neural Latent Representation Alignment
May 05, 2026Understanding the neural mechanisms underlying visual computation has long been a central challenge in neuroscience. Recent alignment based approaches have improved the accuracy of decoding visual stimuli from brain activity, yet they provide limited insight into the neural computations that give rise to these improvements. To address this gap, we propose Dual-Tower Image-Neural Alignment (DINA), an interpretable contrastive framework for analyzing population level visual computations in primary visual cortex (V1). DINA jointly trains a biologically motivated dual-tower architecture that aligns visual stimuli and corresponding V1 population responses in a shared latent space at the level of intermediate feature maps, enabling both accurate decoding and direct access to interpretable feature maps. Evaluated on large-scale two-photon calcium imaging data from mouse V1, DINA achieves accurate neural-based decoding while revealing that decoding performance is primarily supported by coarse, low-level visual structure, rather than semantic category information or fine-grained details. Further analysis reveals that alignable feature maps emerge from multiple spatially distributed image regions, capturing both shape and texture cues, and are predominantly reconstructed by sparse subsets of strongly responsive neurons and their functional interactions. Together, these results confirm that, beyond enabling accurate decoding, DINA provides a principled framework for probing the computational mechanisms underlying visual processing in V1.
Leveraging Persistence Image to Enhance Robustness and Performance in Curvilinear Structure Segmentation
Jan 25, 2026Segmenting curvilinear structures in medical images is essential for analyzing morphological patterns in clinical applications. Integrating topological properties, such as connectivity, improves segmentation accuracy and consistency. However, extracting and embedding such properties - especially from Persistence Diagrams (PD) - is challenging due to their non-differentiability and computational cost. Existing approaches mostly encode topology through handcrafted loss functions, which generalize poorly across tasks. In this paper, we propose PIs-Regressor, a simple yet effective module that learns persistence image (PI) - finite, differentiable representations of topological features - directly from data. Together with Topology SegNet, which fuses these features in both downsampling and upsampling stages, our framework integrates topology into the network architecture itself rather than auxiliary losses. Unlike existing methods that depend heavily on handcrafted loss functions, our approach directly incorporates topological information into the network structure, leading to more robust segmentation. Our design is flexible and can be seamlessly combined with other topology-based methods to further enhance segmentation performance. Experimental results show that integrating topological features enhances model robustness, effectively handling challenges like overexposure and blurring in medical imaging. Our approach on three curvilinear benchmarks demonstrate state-of-the-art performance in both pixel-level accuracy and topological fidelity.
GROK: From Quantitative Biomarkers to Qualitative Diagnosis via a Grounded MLLM with Knowledge-Guided Instruction
Oct 05, 2025
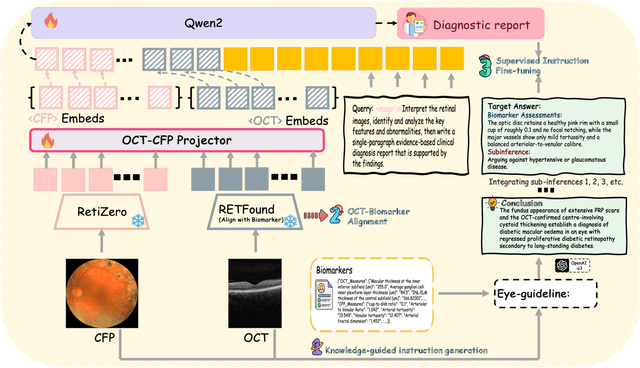


Multimodal large language models (MLLMs) hold promise for integrating diverse data modalities, but current medical adaptations such as LLaVA-Med often fail to fully exploit the synergy between color fundus photography (CFP) and optical coherence tomography (OCT), and offer limited interpretability of quantitative biomarkers. We introduce GROK, a grounded multimodal large language model that jointly processes CFP, OCT, and text to deliver clinician-grade diagnoses of ocular and systemic disease. GROK comprises three core modules: Knowledge-Guided Instruction Generation, CLIP-Style OCT-Biomarker Alignment, and Supervised Instruction Fine-Tuning, which together establish a quantitative-to-qualitative diagnostic chain of thought, mirroring real clinical reasoning when producing detailed lesion annotations. To evaluate our approach, we introduce the Grounded Ophthalmic Understanding benchmark, which covers six disease categories and three tasks: macro-level diagnostic classification, report generation quality, and fine-grained clinical assessment of the generated chain of thought. Experiments show that, with only LoRA (Low-Rank Adaptation) fine-tuning of a 7B-parameter Qwen2 backbone, GROK outperforms comparable 7B and 32B baselines on both report quality and fine-grained clinical metrics, and even exceeds OpenAI o3. Code and data are publicly available in the GROK repository.
Aligning Neuronal Coding of Dynamic Visual Scenes with Foundation Vision Models
Jul 15, 2024



Our brains represent the ever-changing environment with neurons in a highly dynamic fashion. The temporal features of visual pixels in dynamic natural scenes are entrapped in the neuronal responses of the retina. It is crucial to establish the intrinsic temporal relationship between visual pixels and neuronal responses. Recent foundation vision models have paved an advanced way of understanding image pixels. Yet, neuronal coding in the brain largely lacks a deep understanding of its alignment with pixels. Most previous studies employ static images or artificial videos derived from static images for emulating more real and complicated stimuli. Despite these simple scenarios effectively help to separate key factors influencing visual coding, complex temporal relationships receive no consideration. To decompose the temporal features of visual coding in natural scenes, here we propose Vi-ST, a spatiotemporal convolutional neural network fed with a self-supervised Vision Transformer (ViT) prior, aimed at unraveling the temporal-based encoding patterns of retinal neuronal populations. The model demonstrates robust predictive performance in generalization tests. Furthermore, through detailed ablation experiments, we demonstrate the significance of each temporal module. Furthermore, we introduce a visual coding evaluation metric designed to integrate temporal considerations and compare the impact of different numbers of neuronal populations on complementary coding. In conclusion, our proposed Vi-ST demonstrates a novel modeling framework for neuronal coding of dynamic visual scenes in the brain, effectively aligning our brain representation of video with neuronal activity. The code is available at https://github.com/wurining/Vi-ST.
Towards Adaptive Pseudo-label Learning for Semi-Supervised Temporal Action Localization
Jul 10, 2024Alleviating noisy pseudo labels remains a key challenge in Semi-Supervised Temporal Action Localization (SS-TAL). Existing methods often filter pseudo labels based on strict conditions, but they typically assess classification and localization quality separately, leading to suboptimal pseudo-label ranking and selection. In particular, there might be inaccurate pseudo labels within selected positives, alongside reliable counterparts erroneously assigned to negatives. To tackle these problems, we propose a novel Adaptive Pseudo-label Learning (APL) framework to facilitate better pseudo-label selection. Specifically, to improve the ranking quality, Adaptive Label Quality Assessment (ALQA) is proposed to jointly learn classification confidence and localization reliability, followed by dynamically selecting pseudo labels based on the joint score. Additionally, we propose an Instance-level Consistency Discriminator (ICD) for eliminating ambiguous positives and mining potential positives simultaneously based on inter-instance intrinsic consistency, thereby leading to a more precise selection. We further introduce a general unsupervised Action-aware Contrastive Pre-training (ACP) to enhance the discrimination both within actions and between actions and backgrounds, which benefits SS-TAL. Extensive experiments on THUMOS14 and ActivityNet v1.3 demonstrate that our method achieves state-of-the-art performance under various semi-supervised settings.
SMC-NCA: Semantic-guided Multi-level Contrast for Semi-supervised Action Segmentation
Dec 19, 2023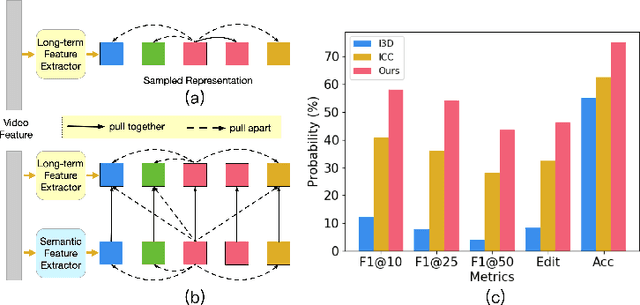

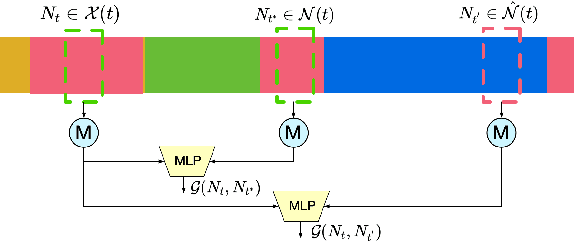

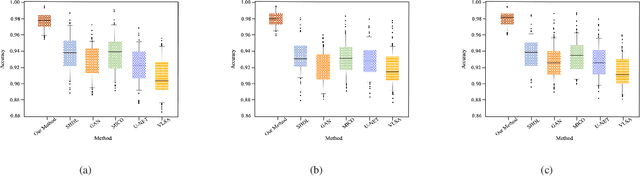
Semi-supervised action segmentation aims to perform frame-wise classification in long untrimmed videos, where only a fraction of videos in the training set have labels. Recent studies have shown the potential of contrastive learning in unsupervised representation learning using unlabelled data. However, learning the representation of each frame by unsupervised contrastive learning for action segmentation remains an open and challenging problem. In this paper, we propose a novel Semantic-guided Multi-level Contrast scheme with a Neighbourhood-Consistency-Aware unit (SMC-NCA) to extract strong frame-wise representations for semi-supervised action segmentation. Specifically, for representation learning, SMC is firstly used to explore intra- and inter-information variations in a unified and contrastive way, based on dynamic clustering process of the original input, encoded semantic and temporal features. Then, the NCA module, which is responsible for enforcing spatial consistency between neighbourhoods centered at different frames to alleviate over-segmentation issues, works alongside SMC for semi-supervised learning. Our SMC outperforms the other state-of-the-art methods on three benchmarks, offering improvements of up to 17.8% and 12.6% in terms of edit distance and accuracy, respectively. Additionally, the NCA unit results in significant better segmentation performance against the others in the presence of only 5% labelled videos. We also demonstrate the effectiveness of the proposed method on our Parkinson's Disease Mouse Behaviour (PDMB) dataset. The code and datasets will be made publicly available.
DGNet: Distribution Guided Efficient Learning for Oil Spill Image Segmentation
Dec 19, 2022


Successful implementation of oil spill segmentation in Synthetic Aperture Radar (SAR) images is vital for marine environmental protection. In this paper, we develop an effective segmentation framework named DGNet, which performs oil spill segmentation by incorporating the intrinsic distribution of backscatter values in SAR images. Specifically, our proposed segmentation network is constructed with two deep neural modules running in an interactive manner, where one is the inference module to achieve latent feature variable inference from SAR images, and the other is the generative module to produce oil spill segmentation maps by drawing the latent feature variables as inputs. Thus, to yield accurate segmentation, we take into account the intrinsic distribution of backscatter values in SAR images and embed it in our segmentation model. The intrinsic distribution originates from SAR imagery, describing the physical characteristics of oil spills. In the training process, the formulated intrinsic distribution guides efficient learning of optimal latent feature variable inference for oil spill segmentation. The efficient learning enables the training of our proposed DGNet with a small amount of image data. This is economically beneficial to oil spill segmentation where the availability of oil spill SAR image data is limited in practice. Additionally, benefiting from optimal latent feature variable inference, our proposed DGNet performs accurate oil spill segmentation. We evaluate the segmentation performance of our proposed DGNet with different metrics, and experimental evaluations demonstrate its effective segmentations.
Cross-Skeleton Interaction Graph Aggregation Network for Representation Learning of Mouse Social Behaviour
Aug 07, 2022



Automated social behaviour analysis of mice has become an increasingly popular research area in behavioural neuroscience. Recently, pose information (i.e., locations of keypoints or skeleton) has been used to interpret social behaviours of mice. Nevertheless, effective encoding and decoding of social interaction information underlying the keypoints of mice has been rarely investigated in the existing methods. In particular, it is challenging to model complex social interactions between mice due to highly deformable body shapes and ambiguous movement patterns. To deal with the interaction modelling problem, we here propose a Cross-Skeleton Interaction Graph Aggregation Network (CS-IGANet) to learn abundant dynamics of freely interacting mice, where a Cross-Skeleton Node-level Interaction module (CS-NLI) is used to model multi-level interactions (i.e., intra-, inter- and cross-skeleton interactions). Furthermore, we design a novel Interaction-Aware Transformer (IAT) to dynamically learn the graph-level representation of social behaviours and update the node-level representation, guided by our proposed interaction-aware self-attention mechanism. Finally, to enhance the representation ability of our model, an auxiliary self-supervised learning task is proposed for measuring the similarity between cross-skeleton nodes. Experimental results on the standard CRMI13-Skeleton and our PDMB-Skeleton datasets show that our proposed model outperforms several other state-of-the-art approaches.