 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adaptive Pseudo-label Learning for Semi-Supervised Temporal Action Localization
Jul 10, 2024Alleviating noisy pseudo labels remains a key challenge in Semi-Supervised Temporal Action Localization (SS-TAL). Existing methods often filter pseudo labels based on strict conditions, but they typically assess classification and localization quality separately, leading to suboptimal pseudo-label ranking and selection. In particular, there might be inaccurate pseudo labels within selected positives, alongside reliable counterparts erroneously assigned to negatives. To tackle these problems, we propose a novel Adaptive Pseudo-label Learning (APL) framework to facilitate better pseudo-label selection. Specifically, to improve the ranking quality, Adaptive Label Quality Assessment (ALQA) is proposed to jointly learn classification confidence and localization reliability, followed by dynamically selecting pseudo labels based on the joint score. Additionally, we propose an Instance-level Consistency Discriminator (ICD) for eliminating ambiguous positives and mining potential positives simultaneously based on inter-instance intrinsic consistency, thereby leading to a more precise selection. We further introduce a general unsupervised Action-aware Contrastive Pre-training (ACP) to enhance the discrimination both within actions and between actions and backgrounds, which benefits SS-TAL. Extensive experiments on THUMOS14 and ActivityNet v1.3 demonstrate that our method achieves state-of-the-art performance under various semi-supervised settings.
Automatic detection of glaucoma via fundus imaging and artificial intelligence: A review
Apr 12, 2022



Glaucoma is a leading cause of irreversible vision impairment globally and cases are continuously rising worldwide. Early detection is crucial, allowing timely intervention which can prevent further visual field loss. To detect glaucoma, examination of the optic nerve head via fundus imaging can be performed, at the centre of which is the assessment of the optic cup and disc boundaries. Fundus imaging is non-invasive and low-cost; however, the image examination relies on subjective, time-consuming, and costly expert assessments. A timely question to ask is can artificial intelligence mimic glaucoma assessments made by experts. Namely, can artificial intelligence automatically find the boundaries of the optic cup and disc (providing a so-called segmented fundus image) and then use the segmented image to identify glaucoma with high accuracy. We conducted a comprehensive review on artificial intelligence-enabled glaucoma detection frameworks that produce and use segmented fundus images. We found 28 papers and identified two main approaches: 1) logical rule-based frameworks, based on a set of simplistic decision rules; and 2) machine learning/statistical modelling based frameworks. We summarise the state-of-art of the two approaches and highlight the key hurdles to overcome for artificial intelligence-enabled glaucoma detection frameworks to be translated into clinical practice.
Deep forecasting of translational impact in medical research
Oct 17, 2021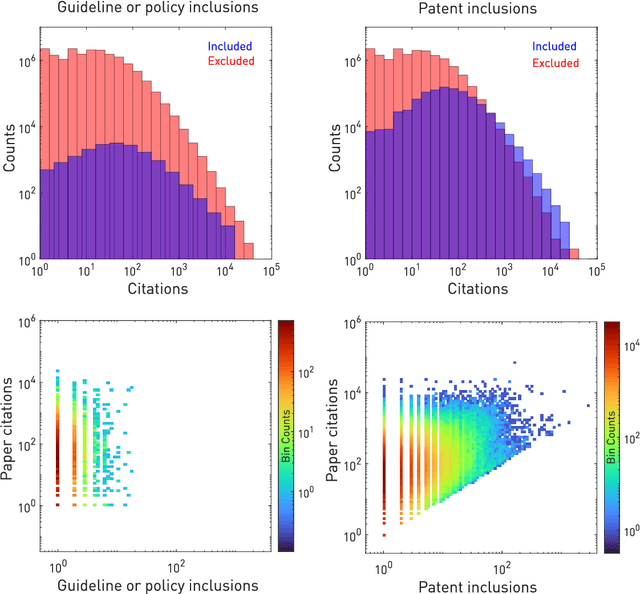
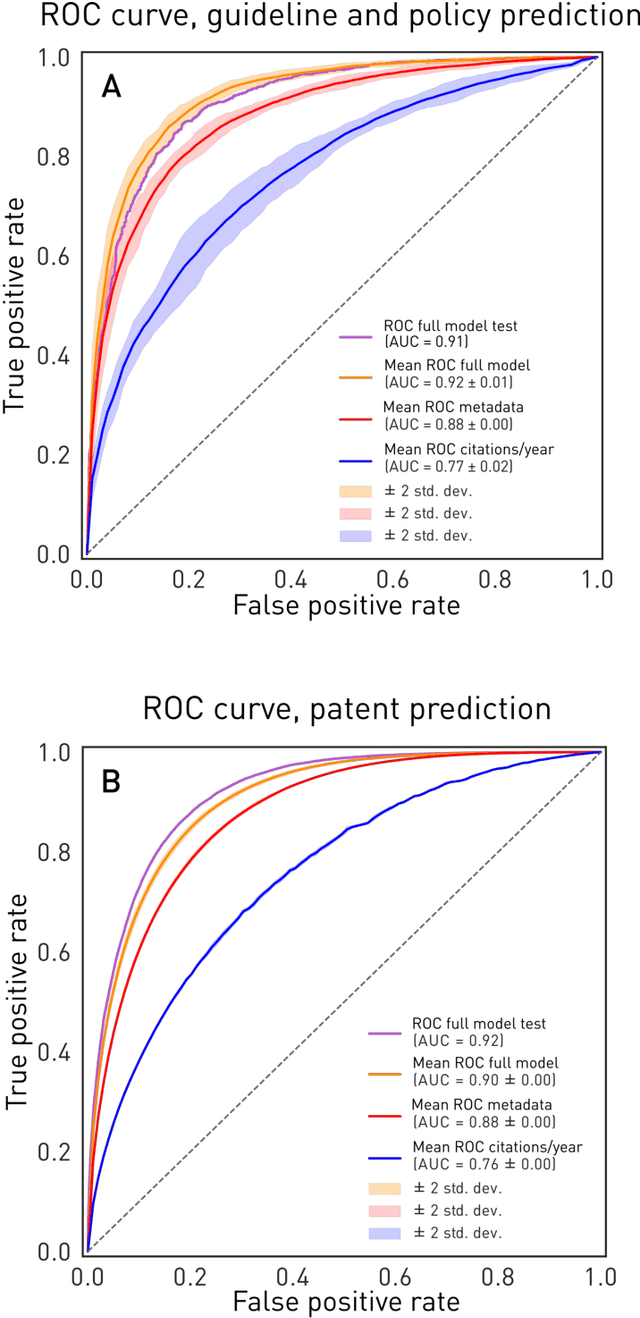
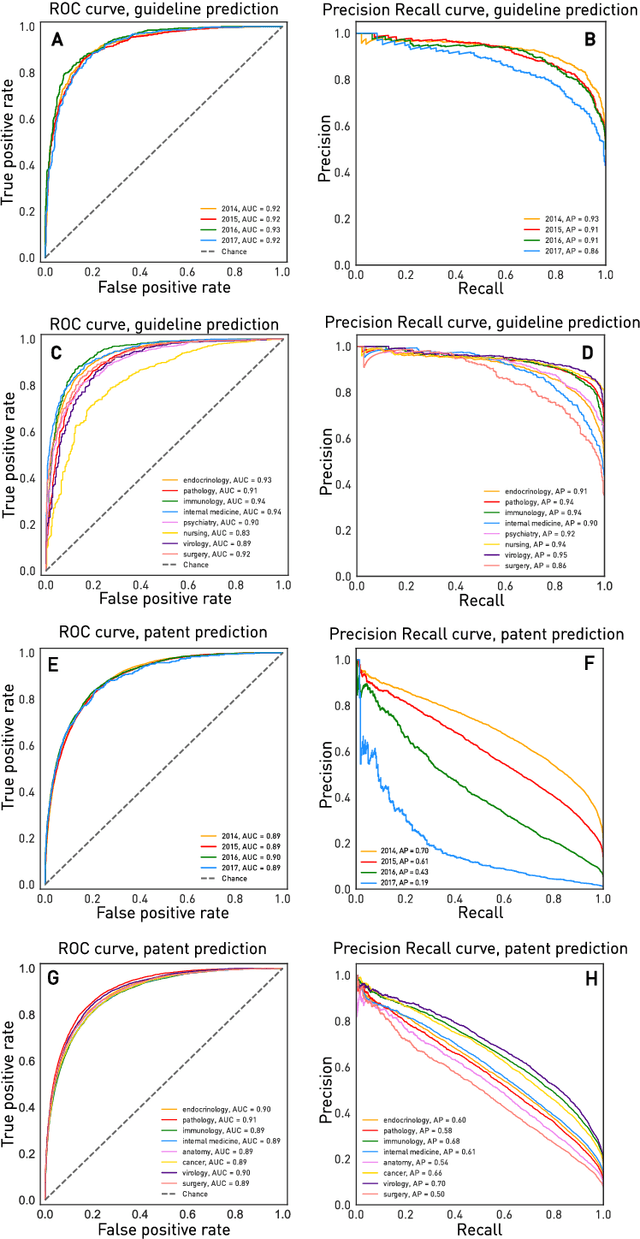
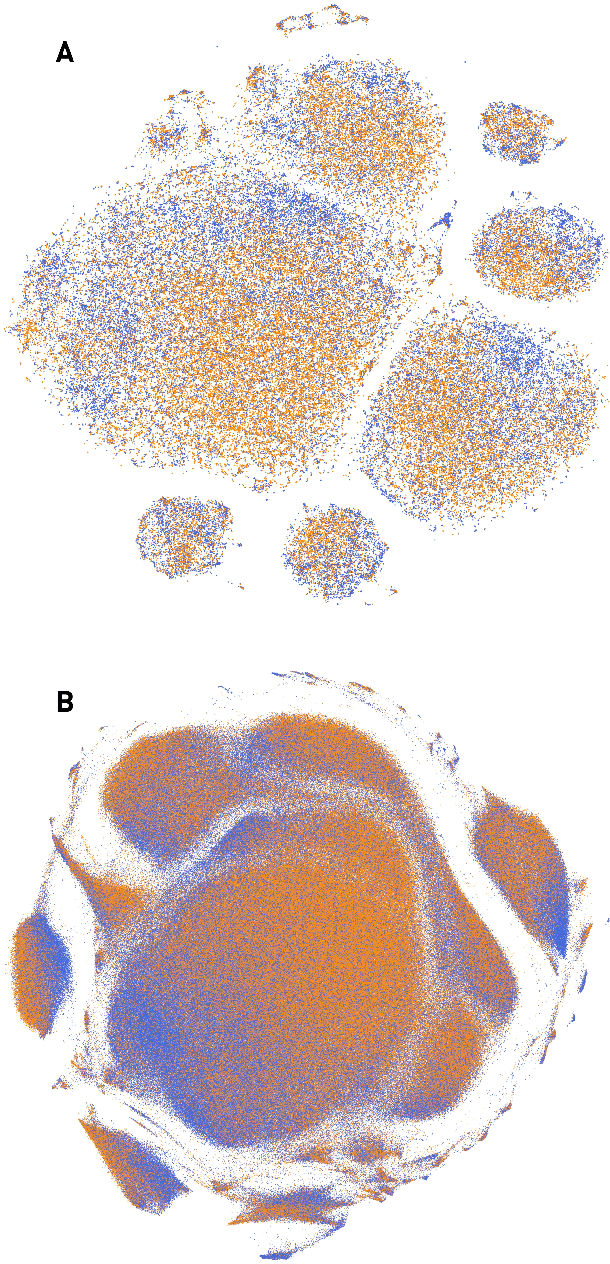
The value of biomedical research--a $1.7 trillion annual investment--is ultimately determined by its downstream, real-world impact. Current objective predictors of impact rest on proxy, reductive metrics of dissemination, such as paper citation rates, whose relation to real-world translation remains unquantified. Here we sought to determine the comparative predictability of future real-world translation--as indexed by inclusion in patents, guidelines or policy documents--from complex models of the abstract-level content of biomedical publications versus citations and publication meta-data alone. We develop a suite of representational and discriminative mathematical models of multi-scale publication data, quantifying predictive performance out-of-sample, ahead-of-time, across major biomedical domains, using the entire corpus of biomedical research captured by Microsoft Academic Graph from 1990 to 2019, encompassing 43.3 million papers across all domains. We show that citations are only moderately predictive of translational impact as judged by inclusion in patents, guidelines, or policy documents. By contrast, high-dimensional models of publication titles, abstracts and metadata exhibit high fidelity (AUROC > 0.9), generalise across time and thematic domain, and transfer to the task of recognising papers of Nobel Laureates. The translational impact of a paper indexed by inclusion in patents, guidelines, or policy documents can be predicted--out-of-sample and ahead-of-time--with substantially higher fidelity from complex models of its abstract-level content than from models of publication meta-data or citation metrics. We argue that content-based models of impact are superior in performance to conventional, citation-based measures, and sustain a stronger evidence-based claim to the objective measurement of translational potential.
Recent Advances of Continual Learning in Computer Vision: An Overview
Sep 24, 2021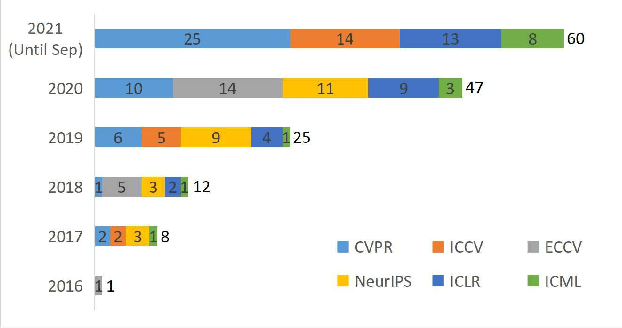
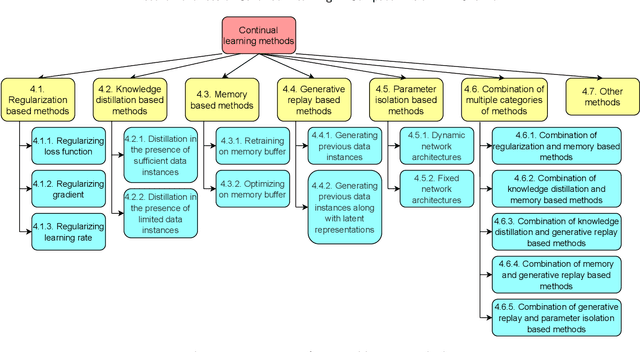
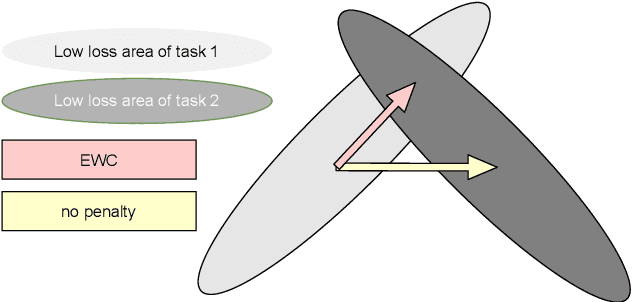
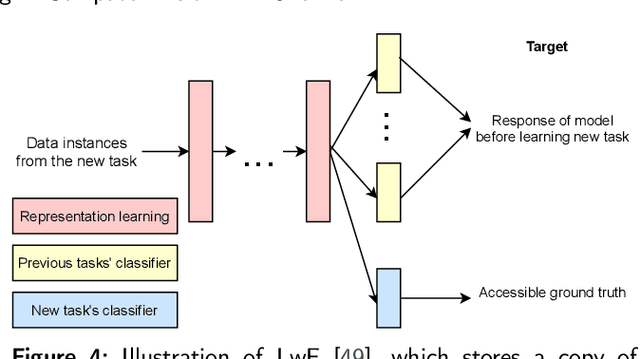
In contrast to batch learning where all training data is available at once, continual learning represents a family of methods that accumulate knowledge and learn continuously with data available in sequential order. Similar to the human learning process with the ability of learning, fusing, and accumulating new knowledge coming at different time steps, continual learning is considered to have high practical significance. Hence, continual learning has been studied in various artificial intelligence tasks. In this paper, we present a comprehensive review of the recent progress of continual learning in computer vision. In particular, the works are grouped by their representative techniques, including regularization, knowledge distillation, memory, generative replay, parameter isolation, and a combination of the above techniques. For each category of these techniques, both its characteristics and applications in computer vision are presented. At the end of this overview, several subareas, where continuous knowledge accumulation is potentially helpful while continual learning has not been well studied, are discussed.
Multi-Branch with Attention Network for Hand-Based Person Recognition
Aug 04, 2021

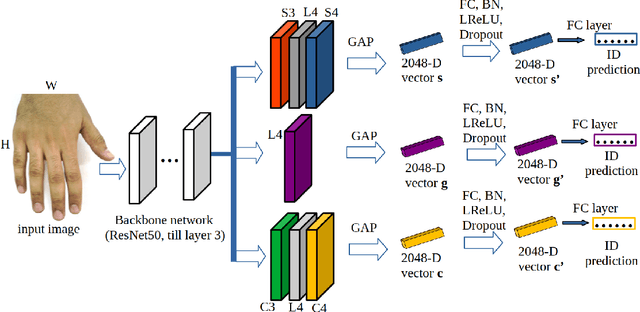

In this paper, we propose a novel hand-based person recognition method for the purpose of criminal investigations since the hand image is often the only available information in cases of serious crime such as sexual abuse. Our proposed method, Multi-Branch with Attention Network (MBA-Net), incorporates both channel and spatial attention modules in branches in addition to a global (without attention) branch to capture global structural information for discriminative feature learning. The attention modules focus on the relevant features of the hand image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. Extensive evaluations on two large multi-ethnic and publicly available hand datasets demonstrate that our proposed method achieves state-of-the-art performance, surpassing the existing hand-based identification methods.
Hand-Based Person Identification using Global and Part-Aware Deep Feature Representation Learning
Jan 19, 2021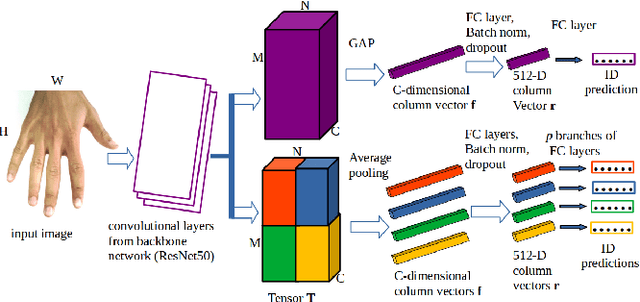

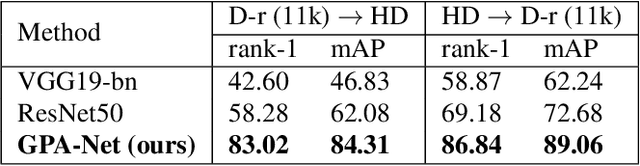

In cases of serious crime, including sexual abuse, often the only available information with demonstrated potential for identification is images of the hands. Since this evidence is captured in uncontrolled situations, it is difficult to analyse. As global approaches to feature comparison are limited in this case, it is important to extend to consider local information. In this work, we propose hand-based person identification by learning both global and local deep feature representation. Our proposed method, Global and Part-Aware Network (GPA-Net), creates global and local branches on the conv-layer for learning robust discriminative global and part-level features. For learning the local (part-level) features, we perform uniform partitioning on the conv-layer in both horizontal and vertical directions. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. We make extensive evaluations on two large multi-ethnic and publicly available hand datasets, demonstrating that our proposed method significantly outperforms competing approaches.