 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentational Ethical Model Calibration
Jul 25, 2022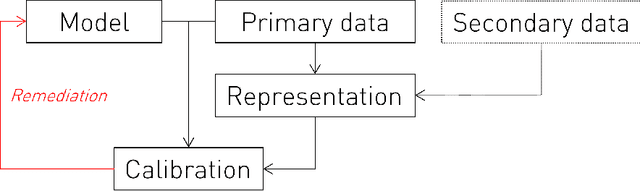


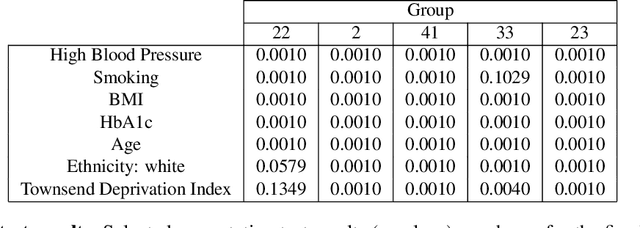
Equity is widely held to be fundamental to the ethics of healthcare. In the context of clinical decision-making, it rests on the comparative fidelity of the intelligence -- evidence-based or intuitive -- guiding the management of each individual patient. Though brought to recent attention by the individuating power of contemporary machine learning, such epistemic equity arises in the context of any decision guidance, whether traditional or innovative. Yet no general framework for its quantification, let alone assurance, currently exists. Here we formulate epistemic equity in terms of model fidelity evaluated over learnt multi-dimensional representations of identity crafted to maximise the captured diversity of the population, introducing a comprehensive framework for Representational Ethical Model Calibration. We demonstrate use of the framework on large-scale multimodal data from UK Biobank to derive diverse representations of the population, quantify model performance, and institute responsive remediation. We offer our approach as a principled solution to quantifying and assuring epistemic equity in healthcare, with applications across the research, clinical, and regulatory domains.
Deep forecasting of translational impact in medical research
Oct 17, 2021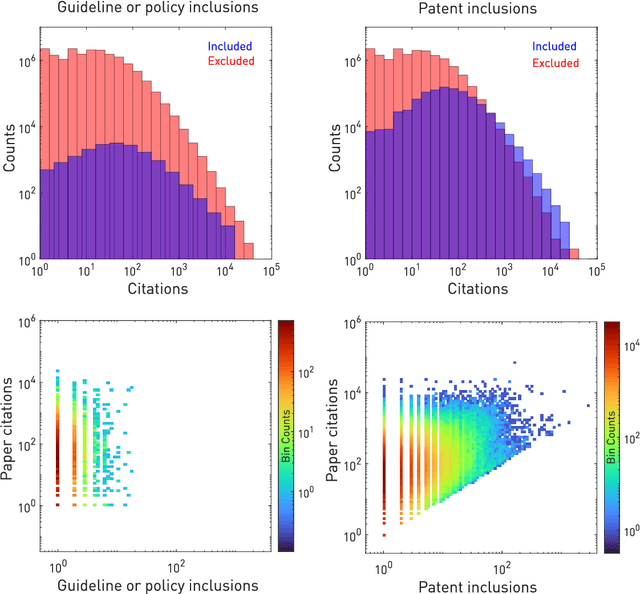
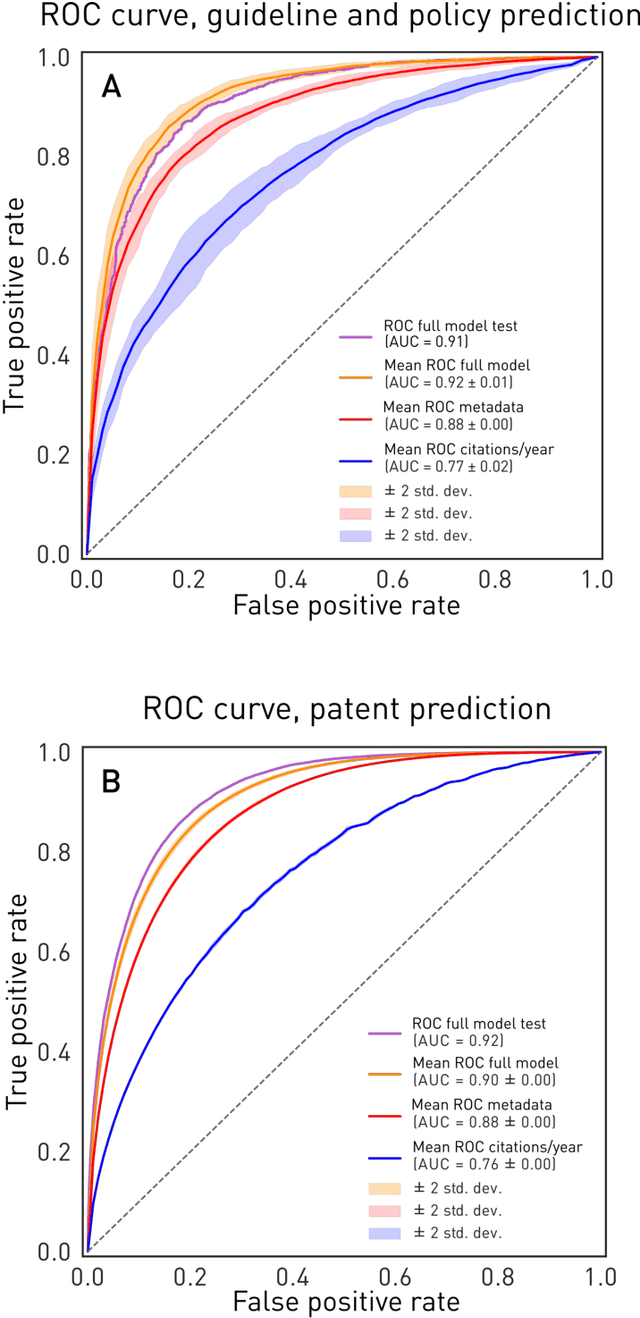
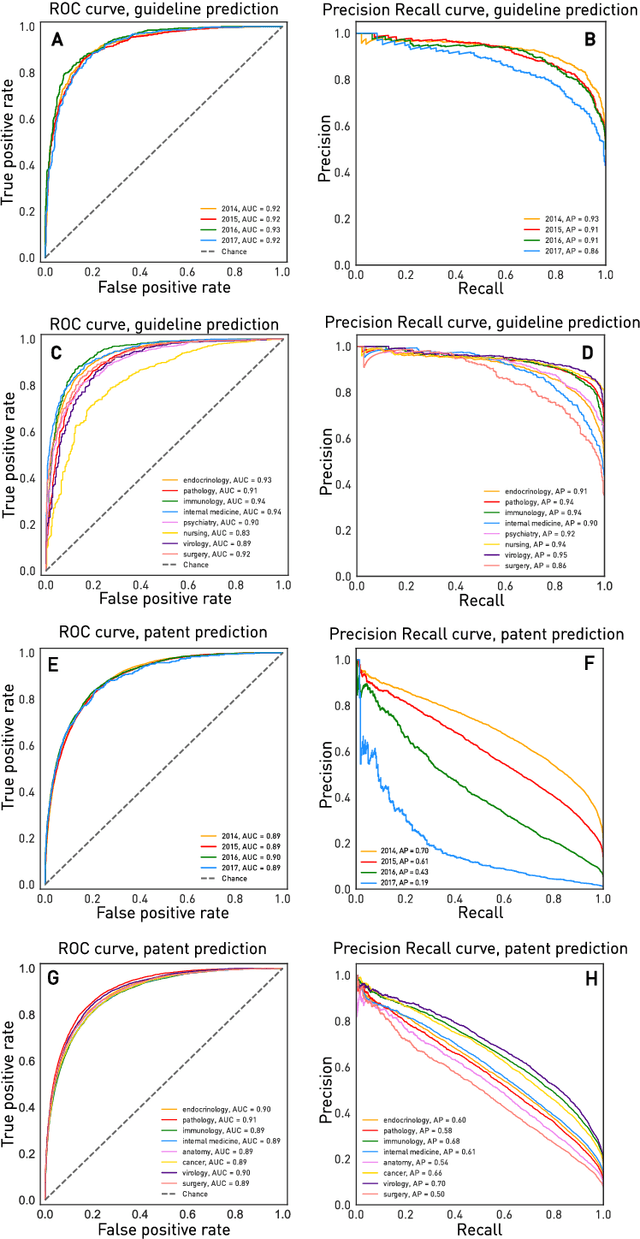
The value of biomedical research--a $1.7 trillion annual investment--is ultimately determined by its downstream, real-world impact. Current objective predictors of impact rest on proxy, reductive metrics of dissemination, such as paper citation rates, whose relation to real-world translation remains unquantified. Here we sought to determine the comparative predictability of future real-world translation--as indexed by inclusion in patents, guidelines or policy documents--from complex models of the abstract-level content of biomedical publications versus citations and publication meta-data alone. We develop a suite of representational and discriminative mathematical models of multi-scale publication data, quantifying predictive performance out-of-sample, ahead-of-time, across major biomedical domains, using the entire corpus of biomedical research captured by Microsoft Academic Graph from 1990 to 2019, encompassing 43.3 million papers across all domains. We show that citations are only moderately predictive of translational impact as judged by inclusion in patents, guidelines, or policy documents. By contrast, high-dimensional models of publication titles, abstracts and metadata exhibit high fidelity (AUROC > 0.9), generalise across time and thematic domain, and transfer to the task of recognising papers of Nobel Laureates. The translational impact of a paper indexed by inclusion in patents, guidelines, or policy documents can be predicted--out-of-sample and ahead-of-time--with substantially higher fidelity from complex models of its abstract-level content than from models of publication meta-data or citation metrics. We argue that content-based models of impact are superior in performance to conventional, citation-based measures, and sustain a stronger evidence-based claim to the objective measurement of translational potential.