 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Co-training with Swapping Assignments for Semantic Segmentation
Feb 27, 2024Class activation maps (CAMs) are commonly employed in weakly supervised semantic segmentation (WSSS) to produce pseudo-labels. Due to incomplete or excessive class activation, existing studies often resort to offline CAM refinement, introducing additional stages or proposing offline modules. This can cause optimization difficulties for single-stage methods and limit generalizability. In this study, we aim to reduce the observed CAM inconsistency and error to mitigate reliance on refinement processes. We propose an end-to-end WSSS model incorporating guided CAMs, wherein our segmentation model is trained while concurrently optimizing CAMs online. Our method, Co-training with Swapping Assignments (CoSA), leverages a dual-stream framework, where one sub-network learns from the swapped assignments generated by the other. We introduce three techniques: i) soft perplexity-based regularization to penalize uncertain regions; ii) a threshold-searching approach to dynamically revise the confidence threshold; and iii) contrastive separation to address the coexistence problem. CoSA demonstrates exceptional performance, achieving mIoU of 76.2\% and 51.0\% on VOC and COCO validation datasets, respectively, surpassing existing baselines by a substantial margin. Notably, CoSA is the first single-stage approach to outperform all existing multi-stage methods including those with additional supervision. Code is avilable at \url{https://github.com/youshyee/CoSA}.
3D Points Splatting for Real-Time Dynamic Hand Reconstruction
Dec 21, 2023We present 3D Points Splatting Hand Reconstruction (3D-PSHR), a real-time and photo-realistic hand reconstruction approach. We propose a self-adaptive canonical points upsampling strategy to achieve high-resolution hand geometry representation. This is followed by a self-adaptive deformation that deforms the hand from the canonical space to the target pose, adapting to the dynamic changing of canonical points which, in contrast to the common practice of subdividing the MANO model, offers greater flexibility and results in improved geometry fitting. To model texture, we disentangle the appearance color into the intrinsic albedo and pose-aware shading, which are learned through a Context-Attention module. Moreover, our approach allows the geometric and the appearance models to be trained simultaneously in an end-to-end manner. We demonstrate that our method is capable of producing animatable, photorealistic and relightable hand reconstructions using multiple datasets, including monocular videos captured with handheld smartphones and large-scale multi-view videos featuring various hand poses. We also demonstrate that our approach achieves real-time rendering speeds while simultaneously maintaining superior performance compared to existing state-of-the-art methods.
A Probabilistic Attention Model with Occlusion-aware Texture Regression for 3D Hand Reconstruction from a Single RGB Image
Apr 27, 2023Recently, deep learning based approaches have shown promising results in 3D hand reconstruction from a single RGB image. These approaches can be roughly divided into model-based approaches, which are heavily dependent on the model's parameter space, and model-free approaches, which require large numbers of 3D ground truths to reduce depth ambiguity and struggle in weakly-supervised scenarios. To overcome these issues, we propose a novel probabilistic model to achieve the robustness of model-based approaches and reduced dependence on the model's parameter space of model-free approaches. The proposed probabilistic model incorporates a model-based network as a prior-net to estimate the prior probability distribution of joints and vertices. An Attention-based Mesh Vertices Uncertainty Regression (AMVUR) model is proposed to capture dependencies among vertices and the correlation between joints and mesh vertices to improve their feature representation. We further propose a learning based occlusion-aware Hand Texture Regression model to achieve high-fidelity texture reconstruction. We demonstrate the flexibility of the proposed probabilistic model to be trained in both supervised and weakly-supervised scenarios. The experimental results demonstrate our probabilistic model's state-of-the-art accuracy in 3D hand and texture reconstruction from a single image in both training schemes, including in the presence of severe occlusions.
Multi-Branch with Attention Network for Hand-Based Person Recognition
Aug 04, 2021

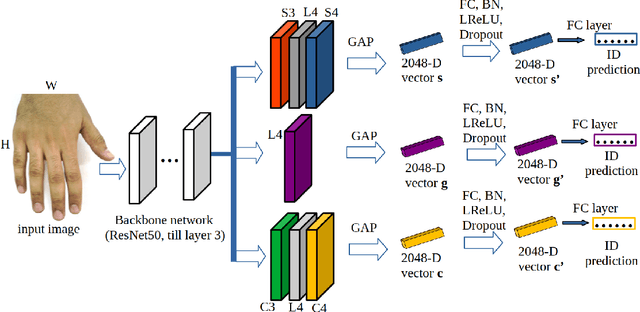

In this paper, we propose a novel hand-based person recognition method for the purpose of criminal investigations since the hand image is often the only available information in cases of serious crime such as sexual abuse. Our proposed method, Multi-Branch with Attention Network (MBA-Net), incorporates both channel and spatial attention modules in branches in addition to a global (without attention) branch to capture global structural information for discriminative feature learning. The attention modules focus on the relevant features of the hand image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. Extensive evaluations on two large multi-ethnic and publicly available hand datasets demonstrate that our proposed method achieves state-of-the-art performance, surpassing the existing hand-based identification methods.
Hand-Based Person Identification using Global and Part-Aware Deep Feature Representation Learning
Jan 19, 2021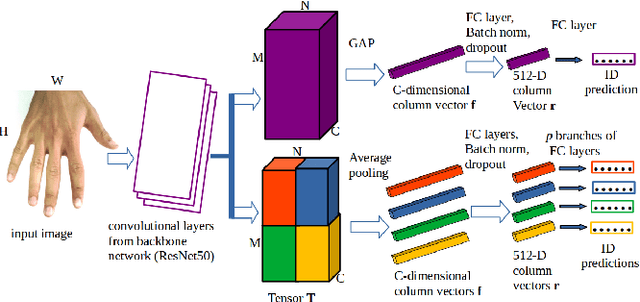

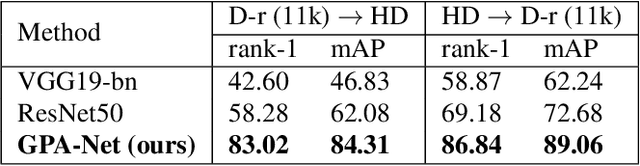

In cases of serious crime, including sexual abuse, often the only available information with demonstrated potential for identification is images of the hands. Since this evidence is captured in uncontrolled situations, it is difficult to analyse. As global approaches to feature comparison are limited in this case, it is important to extend to consider local information. In this work, we propose hand-based person identification by learning both global and local deep feature representation. Our proposed method, Global and Part-Aware Network (GPA-Net), creates global and local branches on the conv-layer for learning robust discriminative global and part-level features. For learning the local (part-level) features, we perform uniform partitioning on the conv-layer in both horizontal and vertical directions. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. We make extensive evaluations on two large multi-ethnic and publicly available hand datasets, demonstrating that our proposed method significantly outperforms competing approaches.