 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-HandID: Vision-Language Model for Hand-Based Person Identification
Jun 14, 2025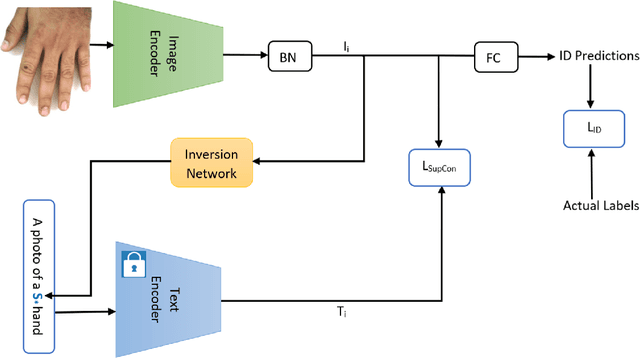


This paper introduces a new approach to person identification based on hand images, designed specifically for criminal investigations. The method is particularly valuable in serious crimes like sexual abuse, where hand images are often the sole identifiable evidence available. Our proposed method, CLIP-HandID, leverages pre-trained foundational vision-language model, particularly CLIP, to efficiently learn discriminative deep feature representations from hand images given as input to the image encoder of CLIP using textual prompts as semantic guidance. We propose to learn pseudo-tokens that represent specific visual contexts or appearance attributes using textual inversion network since labels of hand images are indexes instead text descriptions. The learned pseudo-tokens are incorporated into textual prompts which are given as input to the text encoder of the CLIP to leverage its multi-modal reasoning to enhance its generalization for identification. Through extensive evaluations on two large, publicly available hand datasets with multi-ethnic representation, we show that our method substantially surpasses existing approaches.
FusionSORT: Fusion Methods for Online Multi-object Visual Tracking
Jan 01, 2025



In this work, we investigate four different fusion methods for associating detections to tracklets in multi-object visual tracking. In addition to considering strong cues such as motion and appearance information, we also consider weak cues such as height intersection-over-union (height-IoU) and tracklet confidence information in the data association using different fusion methods. These fusion methods include minimum, weighted sum based on IoU, Kalman filter (KF) gating, and hadamard product of costs due to the different cues. We conduct extensive evaluations on validation sets of MOT17, MOT20 and DanceTrack datasets, and find out that the choice of a fusion method is key for data association in multi-object visual tracking. We hope that this investigative work helps the computer vision research community to use the right fusion method for data association in multi-object visual tracking.
Joint Person Identity, Gender and Age Estimation from Hand Images using Deep Multi-Task Representation Learning
Apr 04, 2023In this paper, we propose a multi-task representation learning framework to jointly estimate the identity, gender and age of individuals from their hand images for the purpose of criminal investigations since the hand images are often the only available information in cases of serious crime such as sexual abuse. We investigate different up-to-date deep learning architectures and compare their performance for joint estimation of identity, gender and age from hand images of perpetrators of serious crime. To overcome the data imbalance and simplify the age prediction, we create age groups for the age estimation. We make extensive evaluations and comparisons of both convolution-based and transformer-based deep learning architectures on a publicly available 11k hands dataset. Our experimental analysis shows that it is possible to efficiently estimate not only identity but also other attributes such as gender and age of suspects jointly from hand images for criminal investigations, which is crucial in assisting international police forces in the court to identify and convict abusers.
Local-Aware Global Attention Network for Person Re-Identification
Sep 11, 2022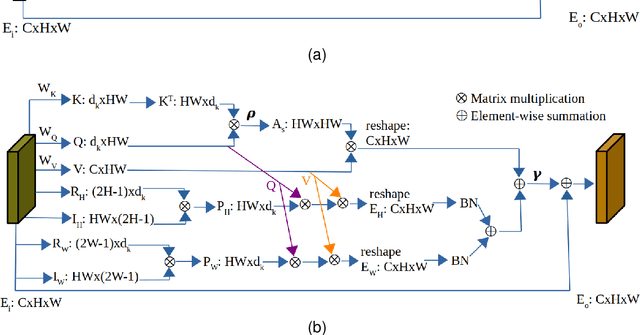
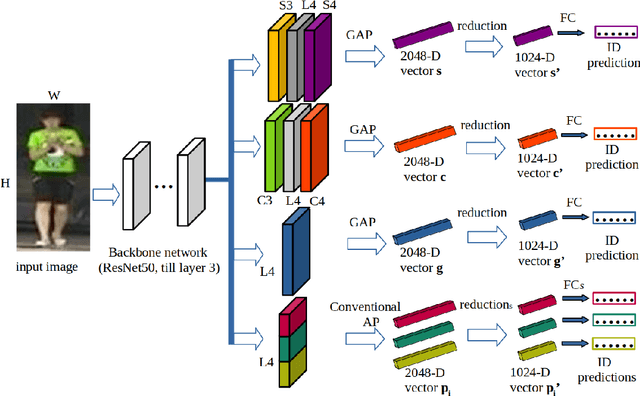


Learning representative, robust and discriminative information from images is essential for effective person re-identification (Re-Id). In this paper, we propose a compound approach for end-to-end discriminative deep feature learning for person Re-Id based on both body and hand images. We carefully design the Local-Aware Global Attention Network (LAGA-Net), a multi-branch deep network architecture consisting of one branch for spatial attention, one branch for channel attention, one branch for global feature representations and another branch for local feature representations. The attention branches focus on the relevant features of the image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. The global branch intends to preserve the global context or structural information. For the the local branch, which intends to capture the fine-grained information, we perform uniform partitioning to generate stripes on the conv-layer horizontally. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. A set of ablation study shows that each component contributes to the increased performance of the LAGA-Net. Extensive evaluations on four popular body-based person Re-Id benchmarks and two publicly available hand datasets demonstrate that our proposed method consistently outperforms existing state-of-the-art methods.
Mushrooms Detection, Localization and 3D Pose Estimation using RGB-D Sensor for Robotic-picking Applications
Jan 08, 2022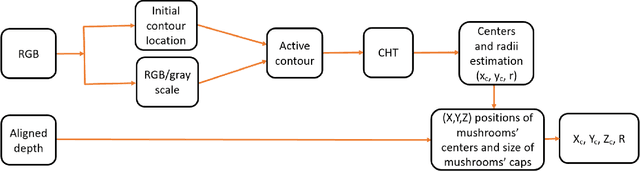
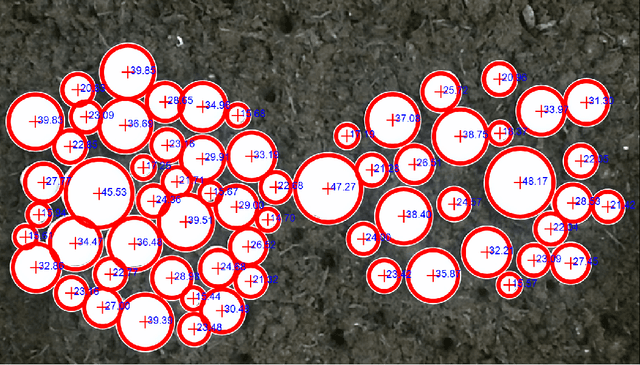
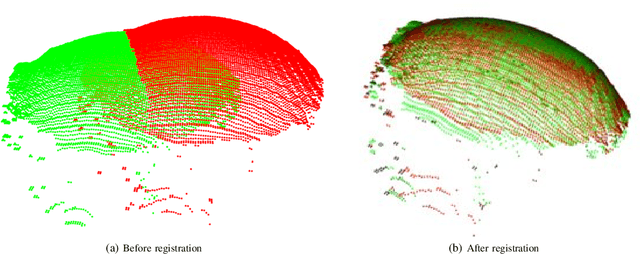

In this paper, we propose mushrooms detection, localization and 3D pose estimation algorithm using RGB-D data acquired from a low-cost consumer RGB-D sensor. We use the RGB and depth information for different purposes. From RGB color, we first extract initial contour locations of the mushrooms and then provide both the initial contour locations and the original image to active contour for mushrooms segmentation. These segmented mushrooms are then used as input to a circular Hough transform for each mushroom detection including its center and radius. Once each mushroom's center position in the RGB image is known, we then use the depth information to locate it in 3D space i.e. in world coordinate system. In case of missing depth information at the detected center of each mushroom, we estimate from the nearest available depth information within the radius of each mushroom. We also estimate the 3D pose of each mushroom using a pre-prepared upright mushroom model. We use a global registration followed by local refine registration approach for this 3D pose estimation. From the estimated 3D pose, we use only the rotation part expressed in quaternion as an orientation of each mushroom. These estimated (X,Y,Z) positions, diameters and orientations of the mushrooms are used for robotic-picking applications. We carry out extensive experiments on both 3D printed and real mushrooms which show that our method has an interesting performance.
Multi-Branch with Attention Network for Hand-Based Person Recognition
Aug 04, 2021

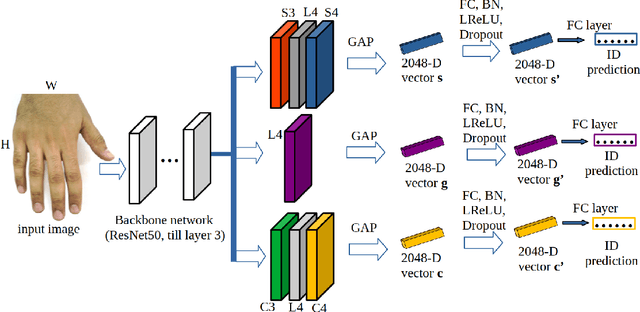

In this paper, we propose a novel hand-based person recognition method for the purpose of criminal investigations since the hand image is often the only available information in cases of serious crime such as sexual abuse. Our proposed method, Multi-Branch with Attention Network (MBA-Net), incorporates both channel and spatial attention modules in branches in addition to a global (without attention) branch to capture global structural information for discriminative feature learning. The attention modules focus on the relevant features of the hand image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. Extensive evaluations on two large multi-ethnic and publicly available hand datasets demonstrate that our proposed method achieves state-of-the-art performance, surpassing the existing hand-based identification methods.
Hand-Based Person Identification using Global and Part-Aware Deep Feature Representation Learning
Jan 19, 2021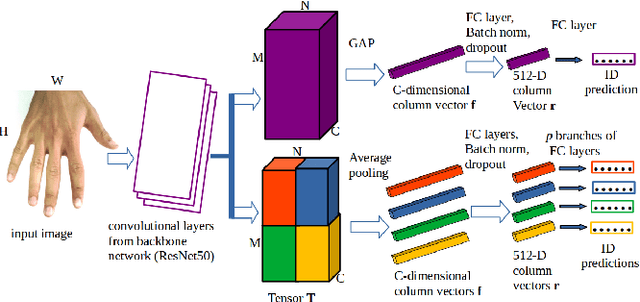

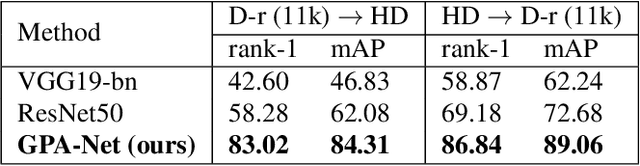

In cases of serious crime, including sexual abuse, often the only available information with demonstrated potential for identification is images of the hands. Since this evidence is captured in uncontrolled situations, it is difficult to analyse. As global approaches to feature comparison are limited in this case, it is important to extend to consider local information. In this work, we propose hand-based person identification by learning both global and local deep feature representation. Our proposed method, Global and Part-Aware Network (GPA-Net), creates global and local branches on the conv-layer for learning robust discriminative global and part-level features. For learning the local (part-level) features, we perform uniform partitioning on the conv-layer in both horizontal and vertical directions. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. We make extensive evaluations on two large multi-ethnic and publicly available hand datasets, demonstrating that our proposed method significantly outperforms competing approaches.
Derivation of a Constant Velocity Motion Model for Visual Tracking
May 18, 2020Motion models play a great role in visual tracking applications for predicting the possible locations of objects in the next frame. Unlike target tracking in radar or aerospace domain which considers only points, object tracking in computer vision involves sizes of objects. Constant velocity motion model is the most widely used motion model for visual tracking, however, there is no clear and understandable derivation involving sizes of objects specially for new researchers joining this research field. In this document, we derive the constant velocity motion model that incorporates sizes of objects that, we think, can help the new researchers to adapt to it very quickly.
Occlusion-robust Online Multi-object Visual Tracking using a GM-PHD Filter with a CNN-based Re-identification
Dec 10, 2019



We propose a novel online multi-object visual tracking algorithm via a tracking-by-detection paradigm using a Gaussian mixture Probability Hypothesis Density (GM-PHD) filter and deep Convolutional Neural Network (CNN) appearance representations learning. The GM-PHD filter has a linear complexity with the number of objects and observations while estimating the states and cardinality of unknown and time-varying number of objects in the scene. Though it handles object birth, death and clutter in a unified framework, it is susceptible to miss-detections and does not include the identity of objects. We use visual-spatio-temporal information obtained from object bounding boxes and deeply learned appearance representations to perform estimates-to-tracks data association for labelling of each target. We learn the deep CNN appearance representations by training an identification network (IdNet) on large-scale person re-identification data sets. We also employ additional unassigned tracks prediction after the update step to overcome the susceptibility of the GM-PHD filter towards miss-detections caused by occlusion. Our tracker which runs in real-time is applied to track multiple objects in video sequences acquired under varying environmental conditions and objects density. Lastly, we make extensive evaluations on Multiple Object Tracking 2016 (MOT16) and 2017 (MOT17) benchmark data sets and find out that our online tracker significantly outperforms several state-of-the-art trackers in terms of tracking accuracy and identification.
Robust Online Multi-target Visual Tracking using a HISP Filter with Discriminative Deep Appearance Learning
Aug 18, 2019
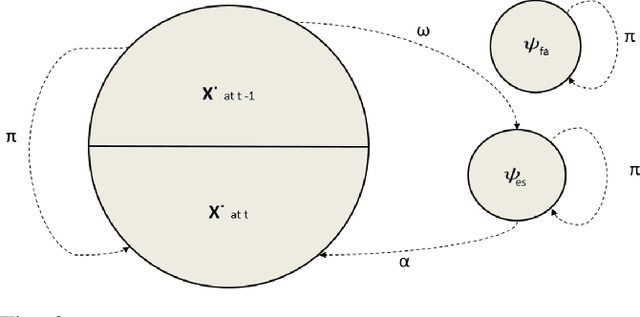
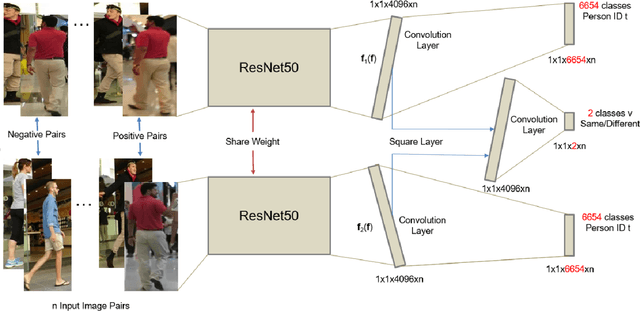

We propose a novel online multi-target visual tracker based on the recently developed Hypothesized and Independent Stochastic Population (HISP) filter. The HISP filter combines advantages of traditional tracking approaches like multiple hypothesis tracking (MHT) and point-process-based approaches like probability hypothesis density (PHD) filter, and has a linear complexity while maintaining track identities. We apply this filter for tracking multiple targets in video sequences acquired under varying environmental conditions and targets density using a tracking-by-detection approach. We also adopt deep convolutional neural networks (CNN) appearance representation by training a verification-identification network (VerIdNet) on large-scale person re-identification data sets. We construct an augmented likelihood in a principled manner using this deep CNN appearance features and spatio-temporal (motion) information that can improve the tracker's performance. In addition, we solve the problem of two or more targets having identical label taking into account the weight propagated with each confirmed hypothesis. Finally, we carry out extensive experiments on Multiple Object Tracking 2016 (MOT16) and 2017 (MOT17) benchmark data sets and find out that our tracker significantly outperforms several state-of-the-art trackers in terms of tracking accuracy.