 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-Aware Global Attention Network for Person Re-Identification
Paper and Code
Sep 11, 2022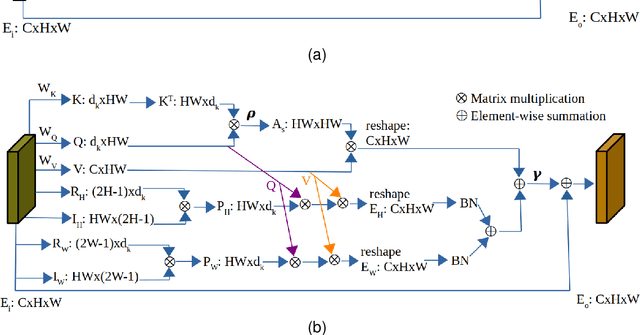
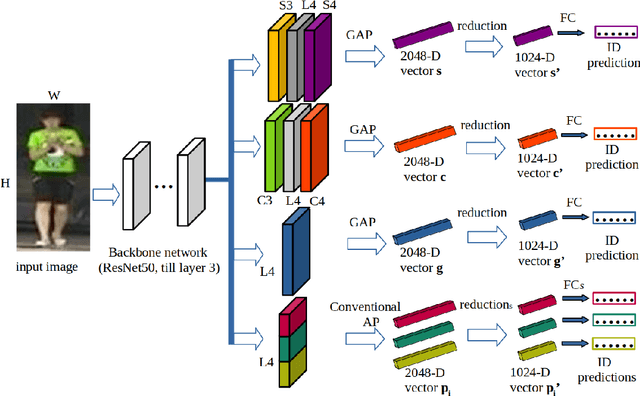


Learning representative, robust and discriminative information from images is essential for effective person re-identification (Re-Id). In this paper, we propose a compound approach for end-to-end discriminative deep feature learning for person Re-Id based on both body and hand images. We carefully design the Local-Aware Global Attention Network (LAGA-Net), a multi-branch deep network architecture consisting of one branch for spatial attention, one branch for channel attention, one branch for global feature representations and another branch for local feature representations. The attention branches focus on the relevant features of the image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. The global branch intends to preserve the global context or structural information. For the the local branch, which intends to capture the fine-grained information, we perform uniform partitioning to generate stripes on the conv-layer horizontally. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. A set of ablation study shows that each component contributes to the increased performance of the LAGA-Net. Extensive evaluations on four popular body-based person Re-Id benchmarks and two publicly available hand datasets demonstrate that our proposed method consistently outperforms existing state-of-the-art methods.