 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMC-NCA: Semantic-guided Multi-level Contrast for Semi-supervised Action Segmentation
Paper and Code
Dec 19, 2023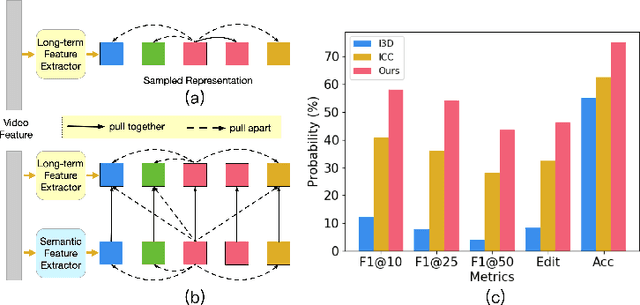

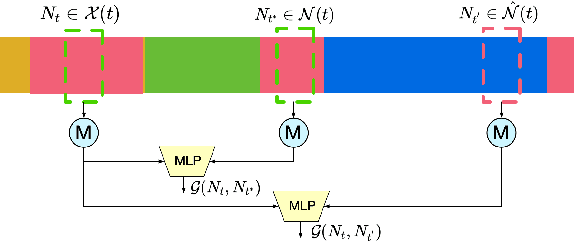

Semi-supervised action segmentation aims to perform frame-wise classification in long untrimmed videos, where only a fraction of videos in the training set have labels. Recent studies have shown the potential of contrastive learning in unsupervised representation learning using unlabelled data. However, learning the representation of each frame by unsupervised contrastive learning for action segmentation remains an open and challenging problem. In this paper, we propose a novel Semantic-guided Multi-level Contrast scheme with a Neighbourhood-Consistency-Aware unit (SMC-NCA) to extract strong frame-wise representations for semi-supervised action segmentation. Specifically, for representation learning, SMC is firstly used to explore intra- and inter-information variations in a unified and contrastive way, based on dynamic clustering process of the original input, encoded semantic and temporal features. Then, the NCA module, which is responsible for enforcing spatial consistency between neighbourhoods centered at different frames to alleviate over-segmentation issues, works alongside SMC for semi-supervised learning. Our SMC outperforms the other state-of-the-art methods on three benchmarks, offering improvements of up to 17.8% and 12.6% in terms of edit distance and accuracy, respectively. Additionally, the NCA unit results in significant better segmentation performance against the others in the presence of only 5% labelled videos. We also demonstrate the effectiveness of the proposed method on our Parkinson's Disease Mouse Behaviour (PDMB) dataset. The code and datasets will be made publicly available.