 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Perturbation Consistency Learning for Robust Language Models
Paper and Code
Feb 24, 2024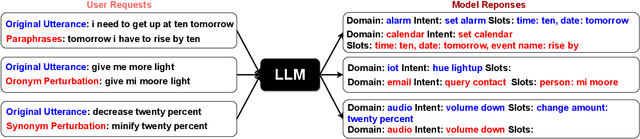

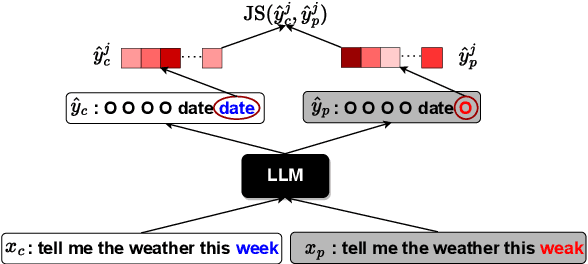

Large language models (LLMs) have demonstrated impressive performance on a number of natural language processing tasks, such as question answering and text summarization. However, their performance on sequence labeling tasks such as intent classification and slot filling (IC-SF), which is a central component in personal assistant systems, lags significantly behind discriminative models. Furthermore, there is a lack of substantive research on the robustness of LLMs to various perturbations in the input prompts. The contributions of this paper are three-fold. First, we show that fine-tuning sufficiently large LLMs can produce IC-SF performance comparable to discriminative models. Next, we systematically analyze the performance deterioration of those fine-tuned models due to three distinct yet relevant types of input perturbations - oronyms, synonyms, and paraphrasing. Finally, we propose an efficient mitigation approach, Prompt Perturbation Consistency Learning (PPCL), which works by regularizing the divergence between losses from clean and perturbed samples. Our experiments demonstrate that PPCL can recover on average 59% and 69% of the performance drop for IC and SF tasks, respectively. Furthermore, PPCL beats the data augmentation approach while using ten times fewer augmented data samples.