 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOP-Bench: Complex Industrial SOPs for Evaluating LLM Agents
Jun 09, 2025Large Language Models (LLMs) demonstrate impressive general-purpose reasoning and problem-solving abilities. However, they struggle with executing complex, long-horizon workflows that demand strict adherence to Standard Operating Procedures (SOPs), a critical requirement for real-world industrial automation. Despite this need, there is a lack of public benchmarks that reflect the complexity, structure, and domain-specific nuances of SOPs. To address this, we present three main contributions. First, we introduce a synthetic data generation framework to create realistic, industry-grade SOPs that rigorously test the planning, reasoning, and tool-use capabilities of LLM-based agents. Second, using this framework, we develop SOP-Bench, a benchmark of over 1,800 tasks across 10 industrial domains, each with APIs, tool interfaces, and human-validated test cases. Third, we evaluate two prominent agent architectures: Function-Calling and ReAct Agents, on SOP-Bench, observing average success rates of only 27% and 48%, respectively. Remarkably, when the tool registry is much larger than necessary, agents invoke incorrect tools nearly 100% of the time. These findings underscore a substantial gap between current agentic capabilities of LLMs and the demands of automating real-world SOPs. Performance varies significantly by task and domain, highlighting the need for domain-specific benchmarking and architectural choices before deployment. SOP-Bench is publicly available at http://sop-bench.s3-website-us-west-2.amazonaws.com/. We also release the prompts underpinning the data generation framework to support new domain-specific SOP benchmarks. We invite the community to extend SOP-Bench with SOPs from their industrial domains.
Prompt Perturbation Consistency Learning for Robust Language Models
Feb 24, 2024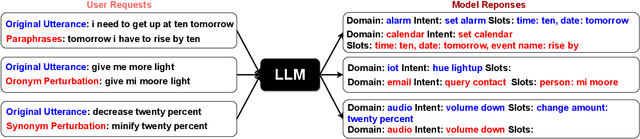

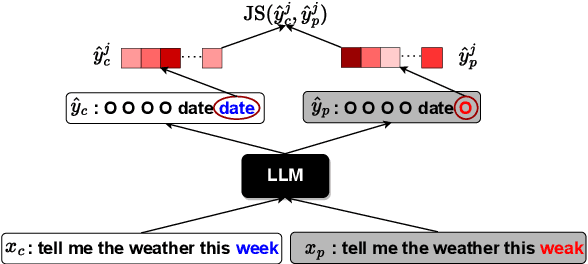

Large language models (LLMs) have demonstrated impressive performance on a number of natural language processing tasks, such as question answering and text summarization. However, their performance on sequence labeling tasks such as intent classification and slot filling (IC-SF), which is a central component in personal assistant systems, lags significantly behind discriminative models. Furthermore, there is a lack of substantive research on the robustness of LLMs to various perturbations in the input prompts. The contributions of this paper are three-fold. First, we show that fine-tuning sufficiently large LLMs can produce IC-SF performance comparable to discriminative models. Next, we systematically analyze the performance deterioration of those fine-tuned models due to three distinct yet relevant types of input perturbations - oronyms, synonyms, and paraphrasing. Finally, we propose an efficient mitigation approach, Prompt Perturbation Consistency Learning (PPCL), which works by regularizing the divergence between losses from clean and perturbed samples. Our experiments demonstrate that PPCL can recover on average 59% and 69% of the performance drop for IC and SF tasks, respectively. Furthermore, PPCL beats the data augmentation approach while using ten times fewer augmented data samples.
Measuring and Mitigating Local Instability in Deep Neural Networks
May 19, 2023



Deep Neural Networks (DNNs) are becoming integral components of real world services relied upon by millions of users. Unfortunately, architects of these systems can find it difficult to ensure reliable performance as irrelevant details like random initialization can unexpectedly change the outputs of a trained system with potentially disastrous consequences. We formulate the model stability problem by studying how the predictions of a model change, even when it is retrained on the same data, as a consequence of stochasticity in the training process. For Natural Language Understanding (NLU) tasks, we find instability in predictions for a significant fraction of queries. We formulate principled metrics, like per-sample ``label entropy'' across training runs or within a single training run, to quantify this phenomenon. Intriguingly, we find that unstable predictions do not appear at random, but rather appear to be clustered in data-specific ways. We study data-agnostic regularization methods to improve stability and propose new data-centric methods that exploit our local stability estimates. We find that our localized data-specific mitigation strategy dramatically outperforms data-agnostic methods, and comes within 90% of the gold standard, achieved by ensembling, at a fraction of the computational cost