 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially-Private Collaborative Online Personalized Mean Estimation
Nov 11, 2024We consider the problem of collaborative personalized mean estimation under a privacy constraint in an environment of several agents continuously receiving data according to arbitrary unknown agent-specific distributions. In particular, we provide a method based on hypothesis testing coupled with differential privacy and data variance estimation. Two privacy mechanisms and two data variance estimation schemes are proposed, and we provide a theoretical convergence analysis of the proposed algorithm for any bounded unknown distributions on the agents' data, showing that collaboration provides faster convergence than a fully local approach where agents do not share data. Moreover, we provide analytical performance curves for the case with an oracle class estimator, i.e., the class structure of the agents, where agents receiving data from distributions with the same mean are considered to be in the same class, is known. The theoretical faster-than-local convergence guarantee is backed up by extensive numerical results showing that for a considered scenario the proposed approach indeed converges much faster than a fully local approach, and performs comparably to ideal performance where all data is public. This illustrates the benefit of private collaboration in an online setting.
Improved Capacity Outer Bound for Private Quadratic Monomial Computation
Jan 11, 2024
In private computation, a user wishes to retrieve a function evaluation of messages stored on a set of databases without revealing the function's identity to the databases. Obead \emph{et al.} introduced a capacity outer bound for private nonlinear computation, dependent on the order of the candidate functions. Focusing on private \emph{quadratic monomial} computation, we propose three methods for ordering candidate functions: a graph edge-coloring method, a graph-distance method, and an entropy-based greedy method. We confirm, via an exhaustive search, that all three methods yield an optimal ordering for $f < 6$ messages. For $6 \leq f \leq 12$ messages, we numerically evaluate the performance of the proposed methods compared with a directed random search. For almost all scenarios considered, the entropy-based greedy method gives the smallest gap to the best-found ordering.
Straggler-Resilient Differentially-Private Decentralized Learning
Dec 06, 2022

We consider the straggler problem in decentralized learning over a logical ring while preserving user data privacy. Especially, we extend the recently proposed framework of differential privacy (DP) amplification by decentralization by Cyffers and Bellet to include overall training latency--comprising both computation and communication latency. Analytical results on both the convergence speed and the DP level are derived for both a skipping scheme (which ignores the stragglers after a timeout) and a baseline scheme that waits for each node to finish before the training continues. A trade-off between overall training latency, accuracy, and privacy, parameterized by the timeout of the skipping scheme, is identified and empirically validated for logistic regression on a real-world dataset.
CodedPaddedFL and CodedSecAgg: Straggler Mitigation and Secure Aggregation in Federated Learning
Dec 16, 2021



We present two novel coded federated learning (FL) schemes for linear regression that mitigate the effect of straggling devices. The first scheme, CodedPaddedFL, mitigates the effect of straggling devices while retaining the privacy level of conventional FL. Particularly, it combines one-time padding for user data privacy with gradient codes to yield resiliency against straggling devices. To apply one-time padding to real data, our scheme exploits a fixed-point arithmetic representation of the data. For a scenario with 25 devices, CodedPaddedFL achieves a speed-up factor of 6.6 and 9.2 for an accuracy of 95\% and 85\% on the MMIST and Fashion-MNIST datasets, respectively, compared to conventional FL. Furthermore, it yields similar performance in terms of latency compared to a recently proposed scheme by Prakash \emph{et al.} without the shortcoming of additional leakage of private data. The second scheme, CodedSecAgg, provides straggler resiliency and robustness against model inversion attacks and is based on Shamir's secret sharing. CodedSecAgg outperforms state-of-the-art secure aggregation schemes such as LightSecAgg by a speed-up factor of 6.6--14.6, depending on the number of colluding devices, on the MNIST dataset for a scenario with 120 devices, at the expense of a 30\% increase in latency compared to CodedPaddedFL.
Coding for Straggler Mitigation in Federated Learning
Sep 30, 2021


We present a novel coded federated learning (FL) scheme for linear regression that mitigates the effect of straggling devices while retaining the privacy level of conventional FL. The proposed scheme combines one-time padding to preserve privacy and gradient codes to yield resiliency against stragglers and consists of two phases. In the first phase, the devices share a one-time padded version of their local data with a subset of other devices. In the second phase, the devices and the central server collaboratively and iteratively train a global linear model using gradient codes on the one-time padded local data. To apply one-time padding to real data, our scheme exploits a fixed-point arithmetic representation of the data. Unlike the coded FL scheme recently introduced by Prakash et al., the proposed scheme maintains the same level of privacy as conventional FL while achieving a similar training time. Compared to conventional FL, we show that the proposed scheme achieves a training speed-up factor of $6.6$ and $9.2$ on the MNIST and Fashion-MNIST datasets for an accuracy of $95\%$ and $85\%$, respectively.
Generative Adversarial User Privacy in Lossy Single-Server Information Retrieval
Dec 07, 2020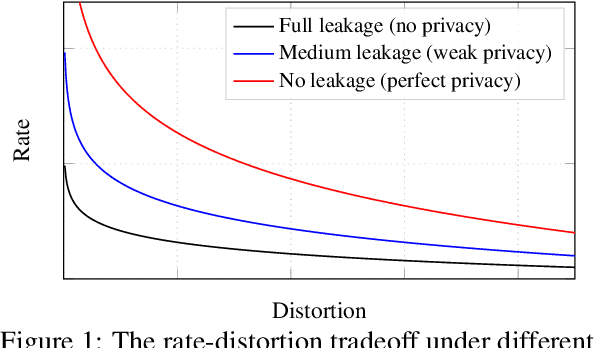
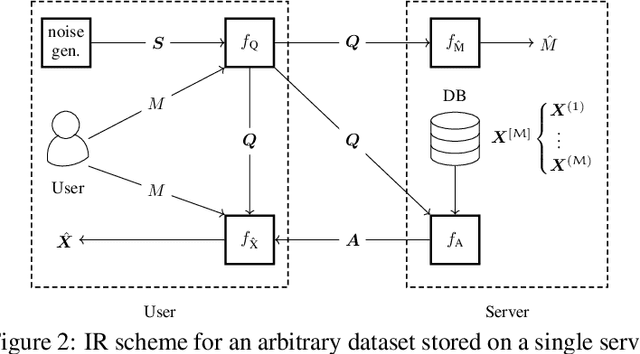

We consider the problem of information retrieval from a dataset of files stored on a single server under both a user distortion and a user privacy constraint. Specifically, a user requesting a file from the dataset should be able to reconstruct the requested file with a prescribed distortion, and in addition, the identity of the requested file should be kept private from the server with a prescribed privacy level. The proposed model can be seen as an extension of the well-known concept of private information retrieval by allowing for distortion in the retrieval process and relaxing the perfect privacy requirement. We initiate the study of the tradeoff between download rate, distortion, and user privacy leakage, and show that the optimal rate-distortion-leakage tradeoff is convex and that in the limit of large file sizes this allows for a concise information-theoretical formulation in terms of mutual information. Moreover, we propose a new data-driven framework by leveraging recent advancements in generative adversarial models which allows a user to learn efficient schemes in terms of download rate from the data itself. Learning the scheme is formulated as a constrained minimax game between a user which desires to keep the identity of the requested file private and an adversary that tries to infer which file the user is interested in under a distortion constraint. In general, guaranteeing a certain privacy level leads to a higher rate-distortion tradeoff curve, and hence a sacrifice in either download rate or distortion. We evaluate the performance of the scheme on a synthetic Gaussian dataset as well as on the MNIST and CIFAR-$10$ datasets. For the MNIST dataset, the data-driven approach significantly outperforms a proposed general achievable scheme combining source coding with the download of multiple files, while for CIFAR-$10$ the performances are comparable.
Coded Distributed Tracking
May 14, 2019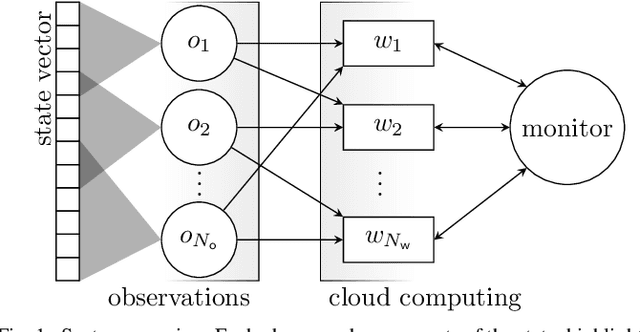
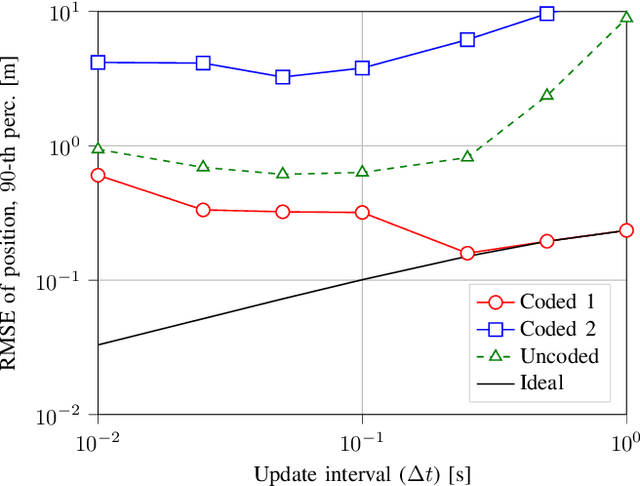
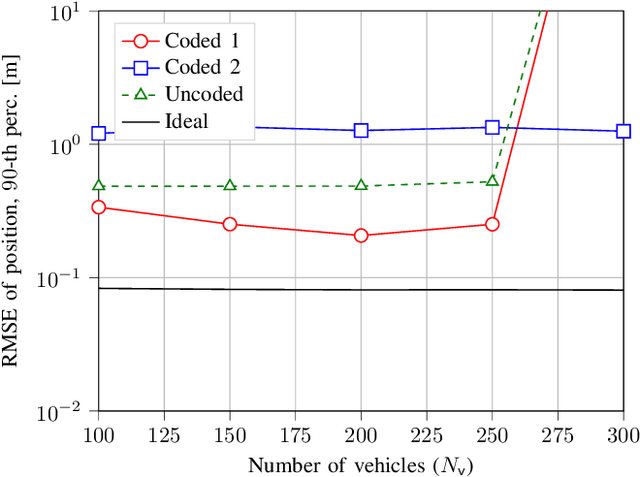
We consider the problem of tracking the state of a process that evolves over time in a distributed setting, with multiple observers each observing parts of the state, which is a fundamental information processing problem with a wide range of applications. We propose a cloud-assisted scheme where the tracking is performed over the cloud. In particular, to provide timely and accurate updates, and alleviate the straggler problem of cloud computing, we propose a coded distributed computing approach where coded observations are distributed over multiple workers. The proposed scheme is based on a coded version of the Kalman filter that operates on data encoded with an erasure correcting code, such that the state can be estimated from partial updates computed by a subset of the workers. We apply the proposed scheme to the problem of tracking multiple vehicles and show that it achieves significantly higher accuracy than that of a corresponding uncoded scheme and approaches the accuracy of an ideal centralized scheme when the update interval is large enough. Finally, we observe a trade-off between age-of-information and estimation accuracy.
Block-Diagonal and LT Codes for Distributed Computing With Straggling Servers
Oct 19, 2018
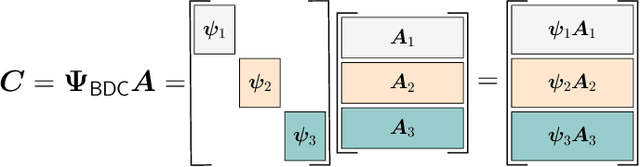
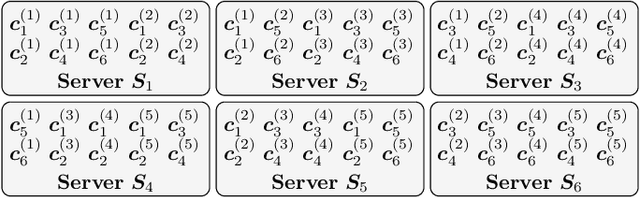
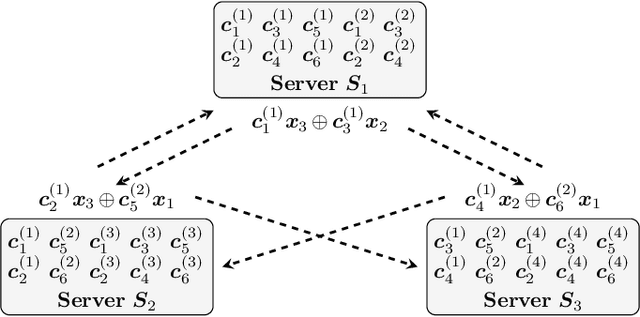
We propose two coded schemes for the distributed computing problem of multiplying a matrix by a set of vectors. The first scheme is based on partitioning the matrix into submatrices and applying maximum distance separable (MDS) codes to each submatrix. For this scheme, we prove that up to a given number of partitions the communication load and the computational delay (not including the encoding and decoding delay) are identical to those of the scheme recently proposed by Li et al., based on a single, long MDS code. However, due to the use of shorter MDS codes, our scheme yields a significantly lower overall computational delay when the delay incurred by encoding and decoding is also considered. We further propose a second coded scheme based on Luby Transform (LT) codes under inactivation decoding. Interestingly, LT codes may reduce the delay over the partitioned scheme at the expense of an increased communication load. We also consider distributed computing under a deadline and show numerically that the proposed schemes outperform other schemes in the literature, with the LT code-based scheme yielding the best performance for the scenarios considered.
A Droplet Approach Based on Raptor Codes for Distributed Computing With Straggling Servers
Oct 08, 2018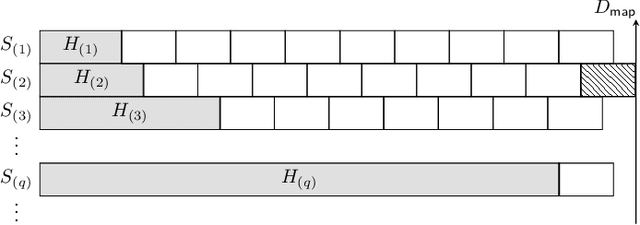
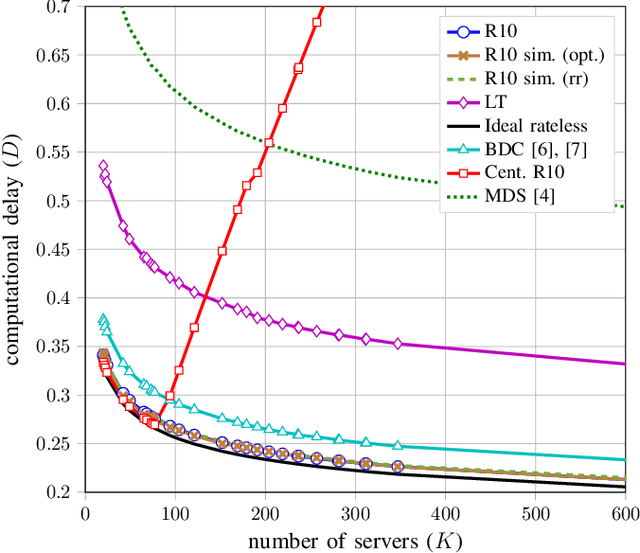
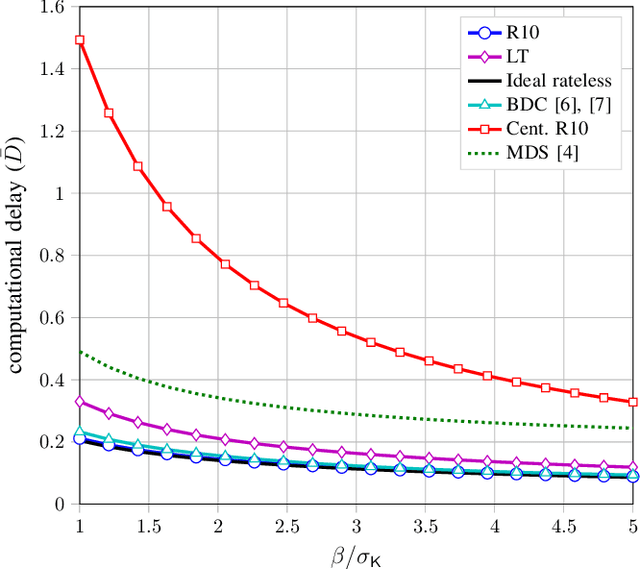
We propose a coded distributed computing scheme based on Raptor codes to address the straggler problem. In particular, we consider a scheme where each server computes intermediate values, referred to as droplets, that are either stored locally or sent over the network. Once enough droplets are collected, the computation can be completed. Compared to previous schemes in the literature, our proposed scheme achieves lower computational delay when the decoding time is taken into account.