 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Multi-Domain Network: Multi-Type and Multi-Scenario Conversion Rate Prediction with a Single Model
Mar 26, 2024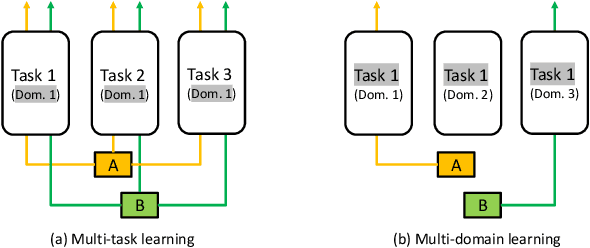

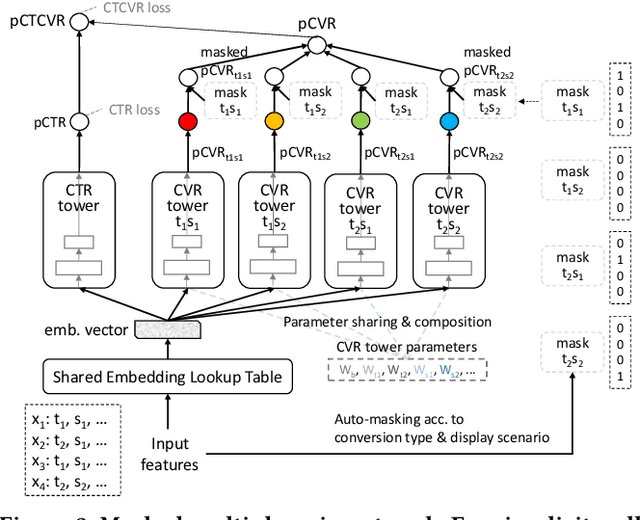
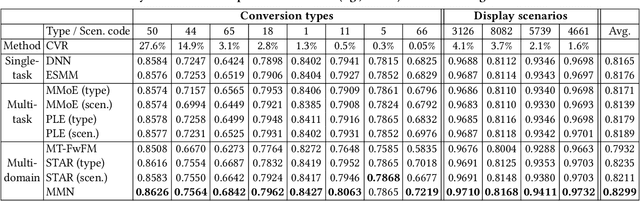
In real-world advertising systems, conversions have different types in nature and ads can be shown in different display scenarios, both of which highly impact the actual conversion rate (CVR). This results in the multi-type and multi-scenario CVR prediction problem. A desired model for this problem should satisfy the following requirements: 1) Accuracy: the model should achieve fine-grained accuracy with respect to any conversion type in any display scenario. 2) Scalability: the model parameter size should be affordable. 3) Convenience: the model should not require a large amount of effort in data partitioning, subset processing and separate storage. Existing approaches cannot simultaneously satisfy these requirements. For example, building a separate model for each (conversion type, display scenario) pair is neither scalable nor convenient. Building a unified model trained on all the data with conversion type and display scenario included as two features is not accurate enough. In this paper, we propose the Masked Multi-domain Network (MMN) to solve this problem. To achieve the accuracy requirement, we model domain-specific parameters and propose a dynamically weighted loss to account for the loss scale imbalance issue within each mini-batch. To achieve the scalability requirement, we propose a parameter sharing and composition strategy to reduce model parameters from a product space to a sum space. To achieve the convenience requirement, we propose an auto-masking strategy which can take mixed data from all the domains as input. It avoids the overhead caused by data partitioning, individual processing and separate storage. Both offline and online experimental results validate the superiority of MMN for multi-type and multi-scenario CVR prediction. MMN is now the serving model for real-time CVR prediction in UC Toutiao.
Contrastive Learning for Conversion Rate Prediction
Jul 12, 2023



Conversion rate (CVR) prediction plays an important role in advertising systems. Recently, supervised deep neural network-based models have shown promising performance in CVR prediction. However, they are data hungry and require an enormous amount of training data. In online advertising systems, although there are millions to billions of ads, users tend to click only a small set of them and to convert on an even smaller set. This data sparsity issue restricts the power of these deep models. In this paper, we propose the Contrastive Learning for CVR prediction (CL4CVR) framework. It associates the supervised CVR prediction task with a contrastive learning task, which can learn better data representations exploiting abundant unlabeled data and improve the CVR prediction performance. To tailor the contrastive learning task to the CVR prediction problem, we propose embedding masking (EM), rather than feature masking, to create two views of augmented samples. We also propose a false negative elimination (FNE) component to eliminate samples with the same feature as the anchor sample, to account for the natural property in user behavior data. We further propose a supervised positive inclusion (SPI) component to include additional positive samples for each anchor sample, in order to make full use of sparse but precious user conversion events. Experimental results on two real-world conversion datasets demonstrate the superior performance of CL4CVR. The source code is available at https://github.com/DongRuiHust/CL4CVR.