 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELEC: Efficient Large Language Model-Empowered Click-Through Rate Prediction
Sep 09, 2025Click-through rate (CTR) prediction plays an important role in online advertising systems. On the one hand, traditional CTR prediction models capture the collaborative signals in tabular data via feature interaction modeling, but they lose semantics in text. On the other hand, Large Language Models (LLMs) excel in understanding the context and meaning behind text, but they face challenges in capturing collaborative signals and they have long inference latency. In this paper, we aim to leverage the benefits of both types of models and pursue collaboration, semantics and efficiency. We present ELEC, which is an Efficient LLM-Empowered CTR prediction framework. We first adapt an LLM for the CTR prediction task. In order to leverage the ability of the LLM but simultaneously keep efficiency, we utilize the pseudo-siamese network which contains a gain network and a vanilla network. We inject the high-level representation vector generated by the LLM into a collaborative CTR model to form the gain network such that it can take advantage of both tabular modeling and textual modeling. However, its reliance on the LLM limits its efficiency. We then distill the knowledge from the gain network to the vanilla network on both the score level and the representation level, such that the vanilla network takes only tabular data as input, but can still generate comparable performance as the gain network. Our approach is model-agnostic. It allows for the integration with various existing LLMs and collaborative CTR models. Experiments on real-world datasets demonstrate the effectiveness and efficiency of ELEC for CTR prediction.
FedUD: Exploiting Unaligned Data for Cross-Platform Federated Click-Through Rate Prediction
Jul 26, 2024



Click-through rate (CTR) prediction plays an important role in online advertising platforms. Most existing methods use data from the advertising platform itself for CTR prediction. As user behaviors also exist on many other platforms, e.g., media platforms, it is beneficial to further exploit such complementary information for better modeling user interest and for improving CTR prediction performance. However, due to privacy concerns, data from different platforms cannot be uploaded to a server for centralized model training. Vertical federated learning (VFL) provides a possible solution which is able to keep the raw data on respective participating parties and learn a collaborative model in a privacy-preserving way. However, traditional VFL methods only utilize aligned data with common keys across parties, which strongly restricts their application scope. In this paper, we propose FedUD, which is able to exploit unaligned data, in addition to aligned data, for more accurate federated CTR prediction. FedUD contains two steps. In the first step, FedUD utilizes aligned data across parties like traditional VFL, but it additionally includes a knowledge distillation module. This module distills useful knowledge from the guest party's high-level representations and guides the learning of a representation transfer network. In the second step, FedUD applies the learned knowledge to enrich the representations of the host party's unaligned data such that both aligned and unaligned data can contribute to federated model training. Experiments on two real-world datasets demonstrate the superior performance of FedUD for federated CTR prediction.
Masked Multi-Domain Network: Multi-Type and Multi-Scenario Conversion Rate Prediction with a Single Model
Mar 26, 2024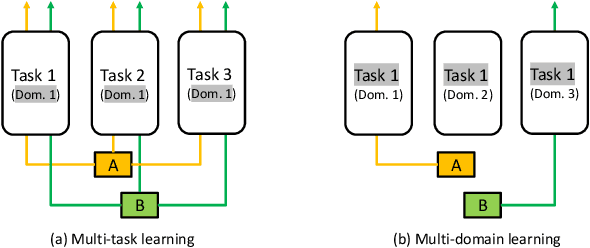

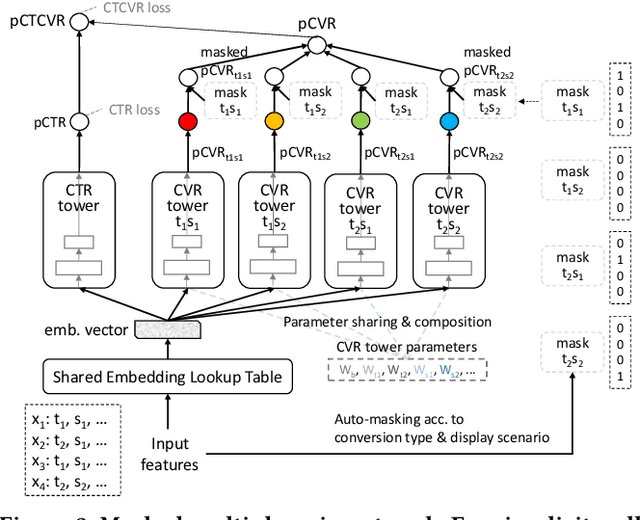
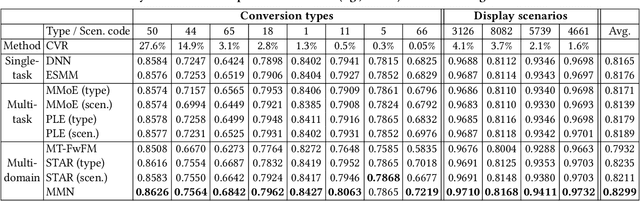
In real-world advertising systems, conversions have different types in nature and ads can be shown in different display scenarios, both of which highly impact the actual conversion rate (CVR). This results in the multi-type and multi-scenario CVR prediction problem. A desired model for this problem should satisfy the following requirements: 1) Accuracy: the model should achieve fine-grained accuracy with respect to any conversion type in any display scenario. 2) Scalability: the model parameter size should be affordable. 3) Convenience: the model should not require a large amount of effort in data partitioning, subset processing and separate storage. Existing approaches cannot simultaneously satisfy these requirements. For example, building a separate model for each (conversion type, display scenario) pair is neither scalable nor convenient. Building a unified model trained on all the data with conversion type and display scenario included as two features is not accurate enough. In this paper, we propose the Masked Multi-domain Network (MMN) to solve this problem. To achieve the accuracy requirement, we model domain-specific parameters and propose a dynamically weighted loss to account for the loss scale imbalance issue within each mini-batch. To achieve the scalability requirement, we propose a parameter sharing and composition strategy to reduce model parameters from a product space to a sum space. To achieve the convenience requirement, we propose an auto-masking strategy which can take mixed data from all the domains as input. It avoids the overhead caused by data partitioning, individual processing and separate storage. Both offline and online experimental results validate the superiority of MMN for multi-type and multi-scenario CVR prediction. MMN is now the serving model for real-time CVR prediction in UC Toutiao.
Contrastive Learning for Conversion Rate Prediction
Jul 12, 2023



Conversion rate (CVR) prediction plays an important role in advertising systems. Recently, supervised deep neural network-based models have shown promising performance in CVR prediction. However, they are data hungry and require an enormous amount of training data. In online advertising systems, although there are millions to billions of ads, users tend to click only a small set of them and to convert on an even smaller set. This data sparsity issue restricts the power of these deep models. In this paper, we propose the Contrastive Learning for CVR prediction (CL4CVR) framework. It associates the supervised CVR prediction task with a contrastive learning task, which can learn better data representations exploiting abundant unlabeled data and improve the CVR prediction performance. To tailor the contrastive learning task to the CVR prediction problem, we propose embedding masking (EM), rather than feature masking, to create two views of augmented samples. We also propose a false negative elimination (FNE) component to eliminate samples with the same feature as the anchor sample, to account for the natural property in user behavior data. We further propose a supervised positive inclusion (SPI) component to include additional positive samples for each anchor sample, in order to make full use of sparse but precious user conversion events. Experimental results on two real-world conversion datasets demonstrate the superior performance of CL4CVR. The source code is available at https://github.com/DongRuiHust/CL4CVR.
The Short Text Matching Model Enhanced with Knowledge via Contrastive Learning
Apr 08, 2023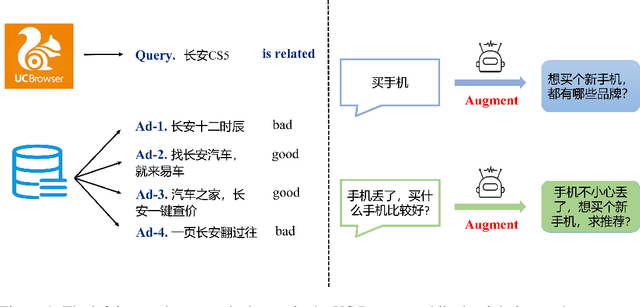
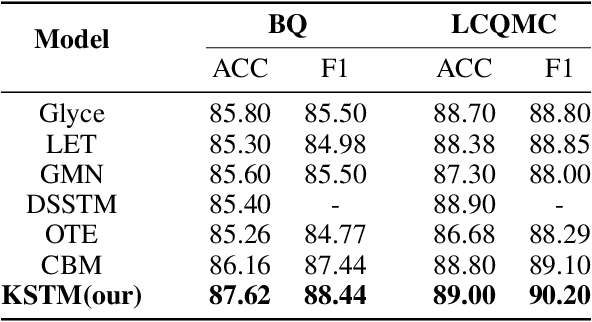
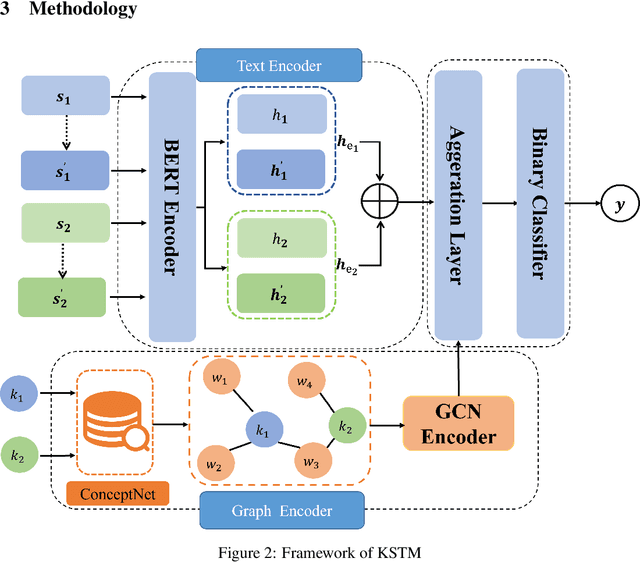
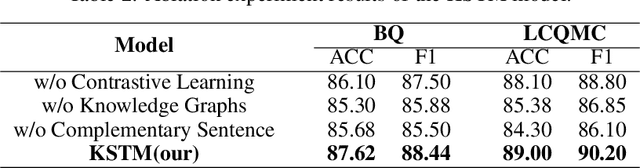
In recent years, short Text Matching tasks have been widely applied in the fields ofadvertising search and recommendation. The difficulty lies in the lack of semantic information and word ambiguity caused by the short length of the text. Previous works have introduced complement sentences or knowledge bases to provide additional feature information. However, these methods have not fully interacted between the original sentence and the complement sentence, and have not considered the noise issue that may arise from the introduction of external knowledge bases. Therefore, this paper proposes a short Text Matching model that combines contrastive learning and external knowledge. The model uses a generative model to generate corresponding complement sentences and uses the contrastive learning method to guide the model to obtain more semantically meaningful encoding of the original sentence. In addition, to avoid noise, we use keywords as the main semantics of the original sentence to retrieve corresponding knowledge words in the knowledge base, and construct a knowledge graph. The graph encoding model is used to integrate the knowledge base information into the model. Our designed model achieves state-of-the-art performance on two publicly available Chinese Text Matching datasets, demonstrating the effectiveness of our model.