 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQARM V2: Quantitative Alignment Multi-Modal Recommendation for Reasoning User Sequence Modeling
Feb 09, 2026With the evolution of large language models (LLMs), there is growing interest in leveraging their rich semantic understanding to enhance industrial recommendation systems (RecSys). Traditional RecSys relies on ID-based embeddings for user sequence modeling in the General Search Unit (GSU) and Exact Search Unit (ESU) paradigm, which suffers from low information density, knowledge isolation, and weak generalization ability. While LLMs offer complementary strengths with dense semantic representations and strong generalization, directly applying LLM embeddings to RecSys faces critical challenges: representation unmatch with business objectives and representation unlearning end-to-end with downstream tasks. In this paper, we present QARM V2, a unified framework that bridges LLM semantic understanding with RecSys business requirements for user sequence modeling.
The Short Text Matching Model Enhanced with Knowledge via Contrastive Learning
Apr 08, 2023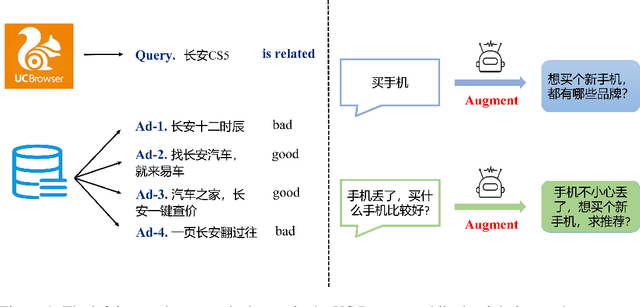
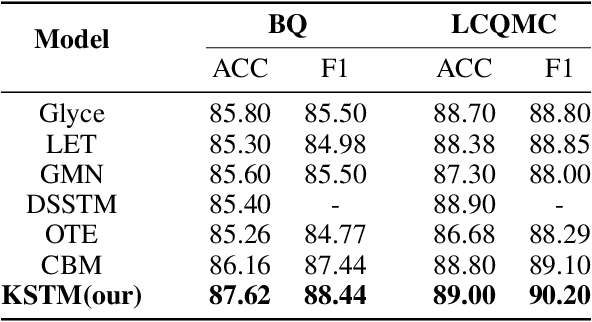
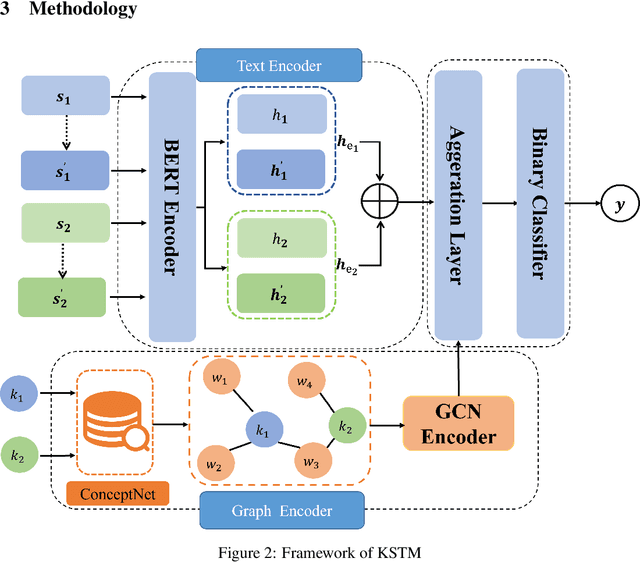
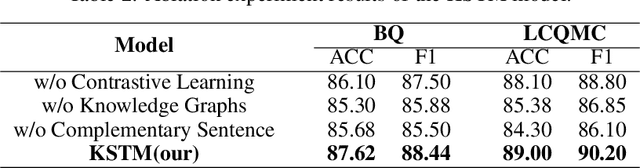
In recent years, short Text Matching tasks have been widely applied in the fields ofadvertising search and recommendation. The difficulty lies in the lack of semantic information and word ambiguity caused by the short length of the text. Previous works have introduced complement sentences or knowledge bases to provide additional feature information. However, these methods have not fully interacted between the original sentence and the complement sentence, and have not considered the noise issue that may arise from the introduction of external knowledge bases. Therefore, this paper proposes a short Text Matching model that combines contrastive learning and external knowledge. The model uses a generative model to generate corresponding complement sentences and uses the contrastive learning method to guide the model to obtain more semantically meaningful encoding of the original sentence. In addition, to avoid noise, we use keywords as the main semantics of the original sentence to retrieve corresponding knowledge words in the knowledge base, and construct a knowledge graph. The graph encoding model is used to integrate the knowledge base information into the model. Our designed model achieves state-of-the-art performance on two publicly available Chinese Text Matching datasets, demonstrating the effectiveness of our model.