 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Multi-Domain Network: Multi-Type and Multi-Scenario Conversion Rate Prediction with a Single Model
Mar 26, 2024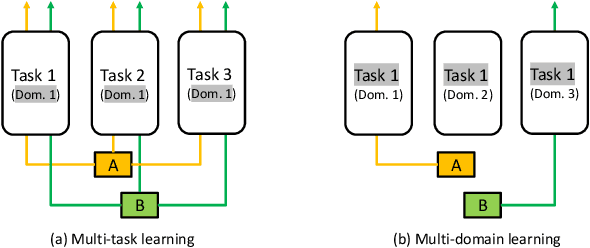

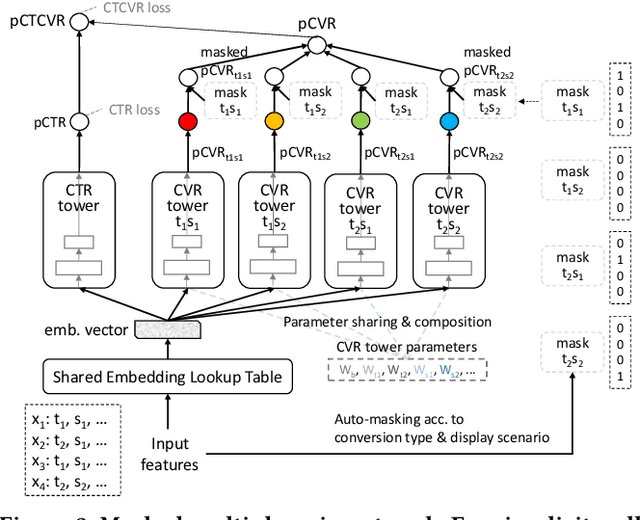
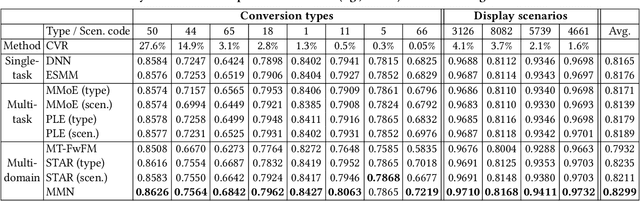
In real-world advertising systems, conversions have different types in nature and ads can be shown in different display scenarios, both of which highly impact the actual conversion rate (CVR). This results in the multi-type and multi-scenario CVR prediction problem. A desired model for this problem should satisfy the following requirements: 1) Accuracy: the model should achieve fine-grained accuracy with respect to any conversion type in any display scenario. 2) Scalability: the model parameter size should be affordable. 3) Convenience: the model should not require a large amount of effort in data partitioning, subset processing and separate storage. Existing approaches cannot simultaneously satisfy these requirements. For example, building a separate model for each (conversion type, display scenario) pair is neither scalable nor convenient. Building a unified model trained on all the data with conversion type and display scenario included as two features is not accurate enough. In this paper, we propose the Masked Multi-domain Network (MMN) to solve this problem. To achieve the accuracy requirement, we model domain-specific parameters and propose a dynamically weighted loss to account for the loss scale imbalance issue within each mini-batch. To achieve the scalability requirement, we propose a parameter sharing and composition strategy to reduce model parameters from a product space to a sum space. To achieve the convenience requirement, we propose an auto-masking strategy which can take mixed data from all the domains as input. It avoids the overhead caused by data partitioning, individual processing and separate storage. Both offline and online experimental results validate the superiority of MMN for multi-type and multi-scenario CVR prediction. MMN is now the serving model for real-time CVR prediction in UC Toutiao.
Contrastive Learning for Conversion Rate Prediction
Jul 12, 2023



Conversion rate (CVR) prediction plays an important role in advertising systems. Recently, supervised deep neural network-based models have shown promising performance in CVR prediction. However, they are data hungry and require an enormous amount of training data. In online advertising systems, although there are millions to billions of ads, users tend to click only a small set of them and to convert on an even smaller set. This data sparsity issue restricts the power of these deep models. In this paper, we propose the Contrastive Learning for CVR prediction (CL4CVR) framework. It associates the supervised CVR prediction task with a contrastive learning task, which can learn better data representations exploiting abundant unlabeled data and improve the CVR prediction performance. To tailor the contrastive learning task to the CVR prediction problem, we propose embedding masking (EM), rather than feature masking, to create two views of augmented samples. We also propose a false negative elimination (FNE) component to eliminate samples with the same feature as the anchor sample, to account for the natural property in user behavior data. We further propose a supervised positive inclusion (SPI) component to include additional positive samples for each anchor sample, in order to make full use of sparse but precious user conversion events. Experimental results on two real-world conversion datasets demonstrate the superior performance of CL4CVR. The source code is available at https://github.com/DongRuiHust/CL4CVR.
Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction
May 19, 2021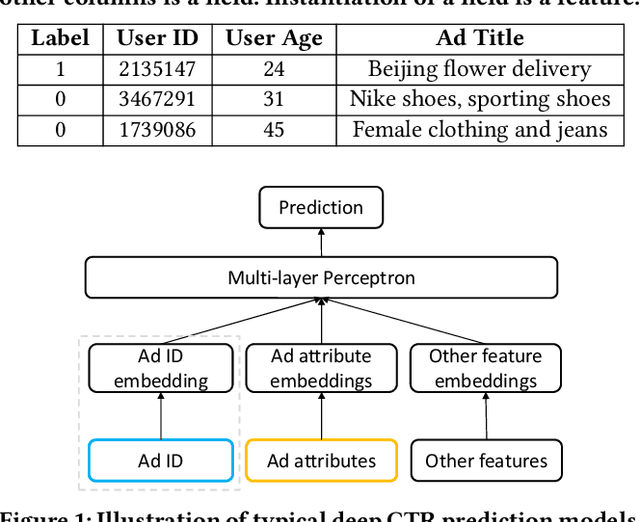
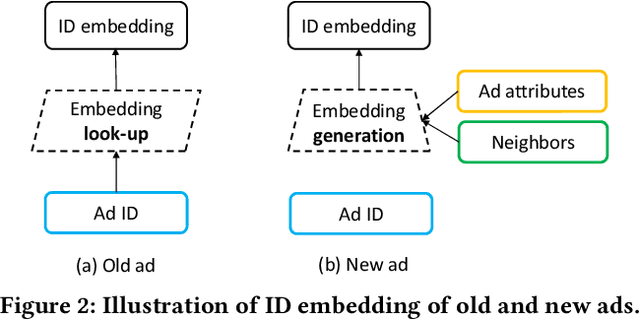
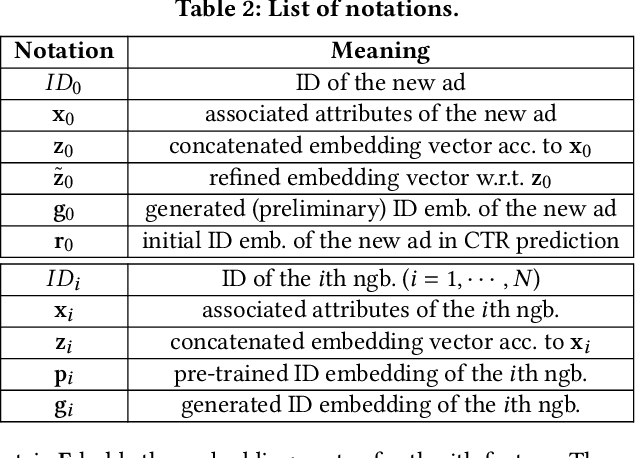
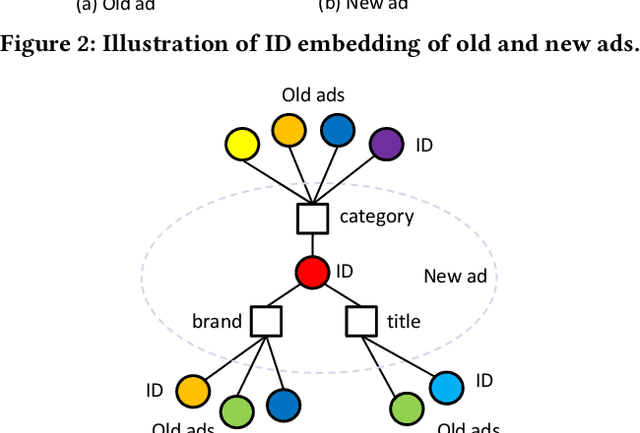
Click-through rate (CTR) prediction is one of the most central tasks in online advertising systems. Recent deep learning-based models that exploit feature embedding and high-order data nonlinearity have shown dramatic successes in CTR prediction. However, these models work poorly on cold-start ads with new IDs, whose embeddings are not well learned yet. In this paper, we propose Graph Meta Embedding (GME) models that can rapidly learn how to generate desirable initial embeddings for new ad IDs based on graph neural networks and meta learning. Previous works address this problem from the new ad itself, but ignore possibly useful information contained in existing old ads. In contrast, GMEs simultaneously consider two information sources: the new ad and existing old ads. For the new ad, GMEs exploit its associated attributes. For existing old ads, GMEs first build a graph to connect them with new ads, and then adaptively distill useful information. We propose three specific GMEs from different perspectives to explore what kind of information to use and how to distill information. In particular, GME-P uses Pre-trained neighbor ID embeddings, GME-G uses Generated neighbor ID embeddings and GME-A uses neighbor Attributes. Experimental results on three real-world datasets show that GMEs can significantly improve the prediction performance in both cold-start (i.e., no training data is available) and warm-up (i.e., a small number of training samples are collected) scenarios over five major deep learning-based CTR prediction models. GMEs can be applied to conversion rate (CVR) prediction as well.
MiNet: Mixed Interest Network for Cross-Domain Click-Through Rate Prediction
Aug 07, 2020

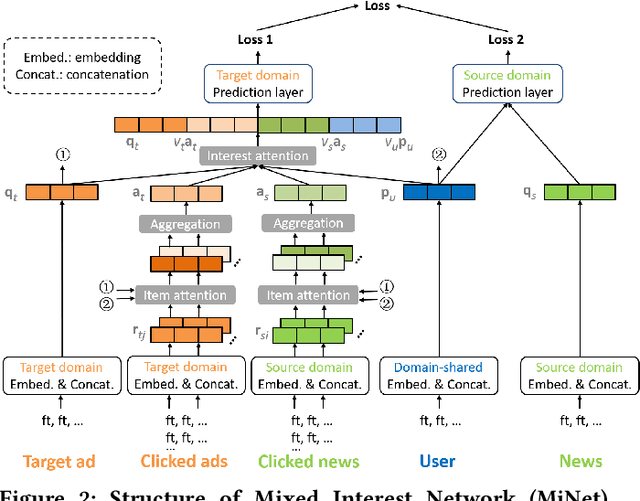
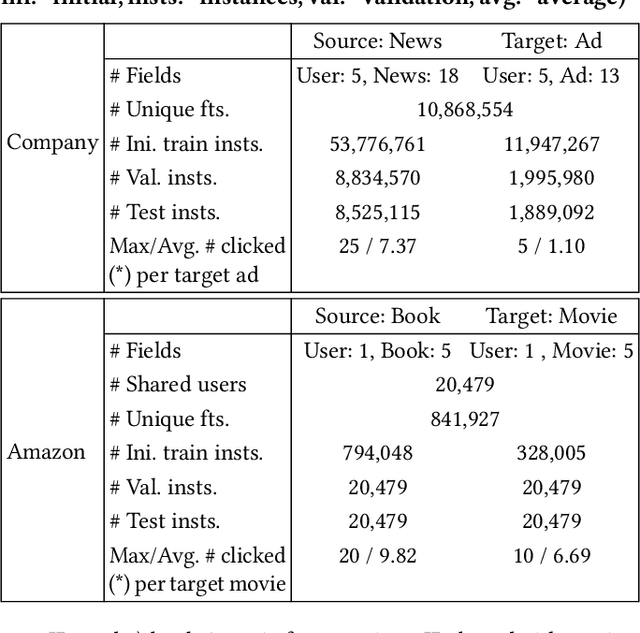
Click-through rate (CTR) prediction is a critical task in online advertising systems. Existing works mainly address the single-domain CTR prediction problem and model aspects such as feature interaction, user behavior history and contextual information. Nevertheless, ads are usually displayed with natural content, which offers an opportunity for cross-domain CTR prediction. In this paper, we address this problem and leverage auxiliary data from a source domain to improve the CTR prediction performance of a target domain. Our study is based on UC Toutiao (a news feed service integrated with the UC Browser App, serving hundreds of millions of users daily), where the source domain is the news and the target domain is the ad. In order to effectively leverage news data for predicting CTRs of ads, we propose the Mixed Interest Network (MiNet) which jointly models three types of user interest: 1) long-term interest across domains, 2) short-term interest from the source domain and 3) short-term interest in the target domain. MiNet contains two levels of attentions, where the item-level attention can adaptively distill useful information from clicked news / ads and the interest-level attention can adaptively fuse different interest representations. Offline experiments show that MiNet outperforms several state-of-the-art methods for CTR prediction. We have deployed MiNet in UC Toutiao and the A/B test results show that the online CTR is also improved substantially. MiNet now serves the main ad traffic in UC Toutiao.
Click-Through Rate Prediction with the User Memory Network
Jul 20, 2019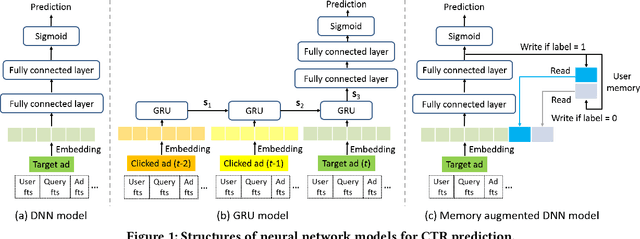
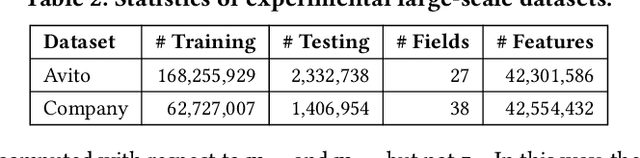
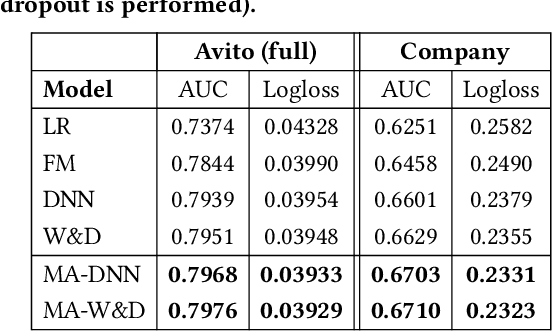
Click-through rate (CTR) prediction is a critical task in online advertising systems. Models like Deep Neural Networks (DNNs) are simple but stateless. They consider each target ad independently and cannot directly extract useful information contained in users' historical ad impressions and clicks. In contrast, models like Recurrent Neural Networks (RNNs) are stateful but complex. They model temporal dependency between users' sequential behaviors and can achieve improved prediction performance than DNNs. However, both the offline training and online prediction process of RNNs are much more complex and time-consuming. In this paper, we propose Memory Augmented DNN (MA-DNN) for practical CTR prediction services. In particular, we create two external memory vectors for each user, memorizing high-level abstractions of what a user possibly likes and dislikes. The proposed MA-DNN achieves a good compromise between DNN and RNN. It is as simple as DNN, but has certain ability to exploit useful information contained in users' historical behaviors as RNN. Both offline and online experiments demonstrate the effectiveness of MA-DNN for practical CTR prediction services. Actually, the memory component can be augmented to other models as well (e.g., the Wide&Deep model).
Representation Learning-Assisted Click-Through Rate Prediction
Jul 19, 2019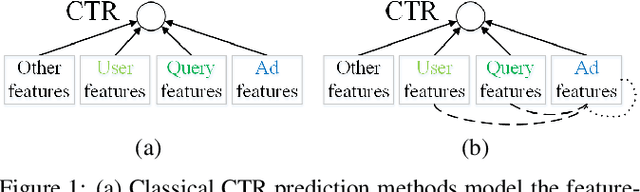
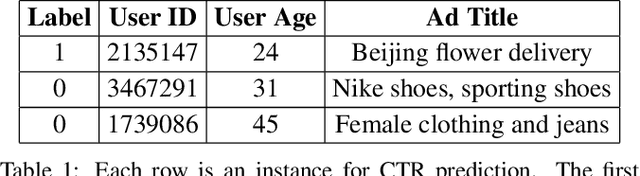
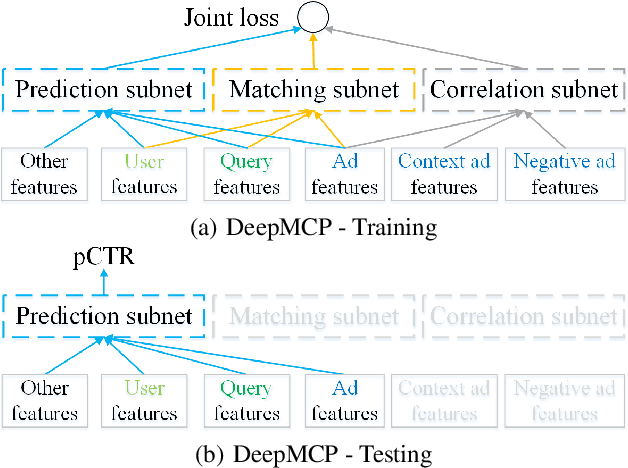
Click-through rate (CTR) prediction is a critical task in online advertising systems. Most existing methods mainly model the feature-CTR relationship and suffer from the data sparsity issue. In this paper, we propose DeepMCP, which models other types of relationships in order to learn more informative and statistically reliable feature representations, and in consequence to improve the performance of CTR prediction. In particular, DeepMCP contains three parts: a matching subnet, a correlation subnet and a prediction subnet. These subnets model the user-ad, ad-ad and feature-CTR relationship respectively. When these subnets are jointly optimized under the supervision of the target labels, the learned feature representations have both good prediction powers and good representation abilities. Experiments on two large-scale datasets demonstrate that DeepMCP outperforms several state-of-the-art models for CTR prediction.
Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction
Jul 19, 2019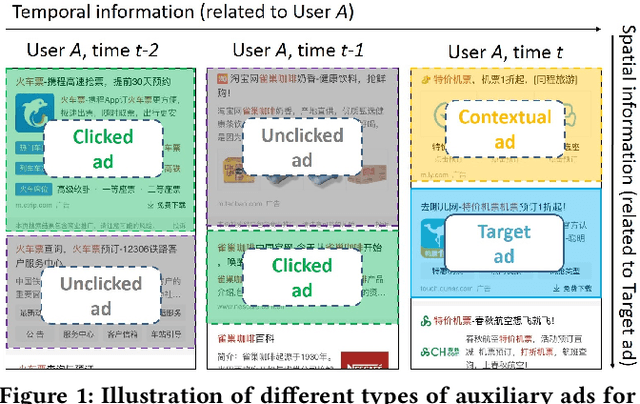
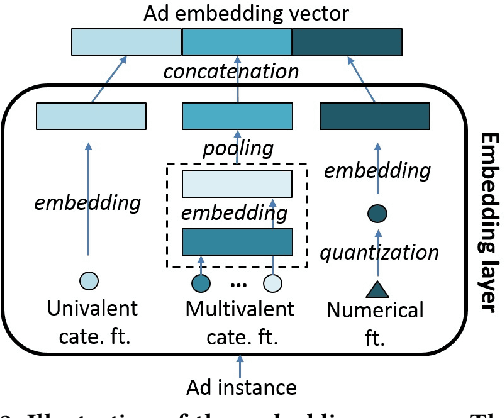

Click-through rate (CTR) prediction is a critical task in online advertising systems. A large body of research considers each ad independently, but ignores its relationship to other ads that may impact the CTR. In this paper, we investigate various types of auxiliary ads for improving the CTR prediction of the target ad. In particular, we explore auxiliary ads from two viewpoints: one is from the spatial domain, where we consider the contextual ads shown above the target ad on the same page; the other is from the temporal domain, where we consider historically clicked and unclicked ads of the user. The intuitions are that ads shown together may influence each other, clicked ads reflect a user's preferences, and unclicked ads may indicate what a user dislikes to certain extent. In order to effectively utilize these auxiliary data, we propose the Deep Spatio-Temporal neural Networks (DSTNs) for CTR prediction. Our model is able to learn the interactions between each type of auxiliary data and the target ad, to emphasize more important hidden information, and to fuse heterogeneous data in a unified framework. Offline experiments on one public dataset and two industrial datasets show that DSTNs outperform several state-of-the-art methods for CTR prediction. We have deployed the best-performing DSTN in Shenma Search, which is the second largest search engine in China. The A/B test results show that the online CTR is also significantly improved compared to our last serving model.