 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025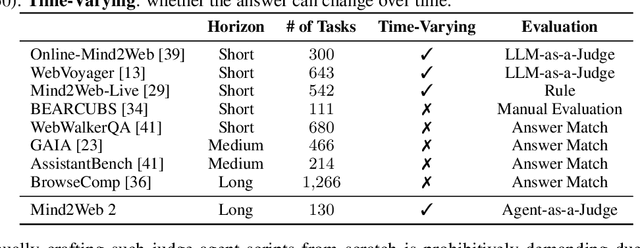
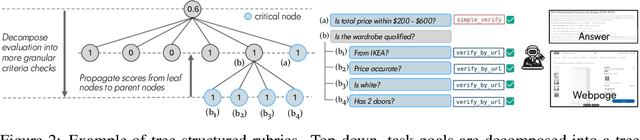

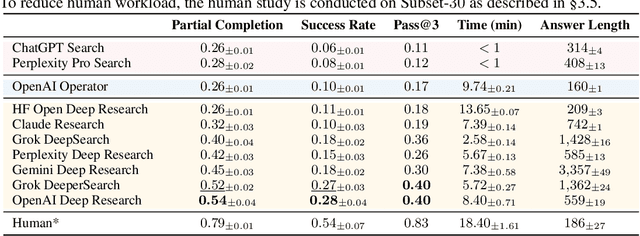
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Feb 20, 2025

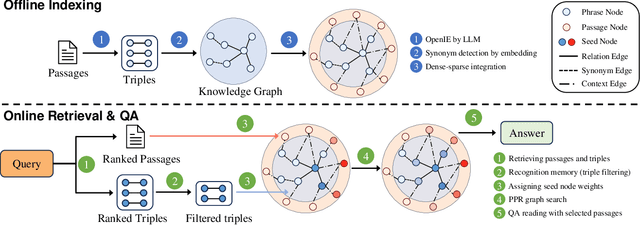
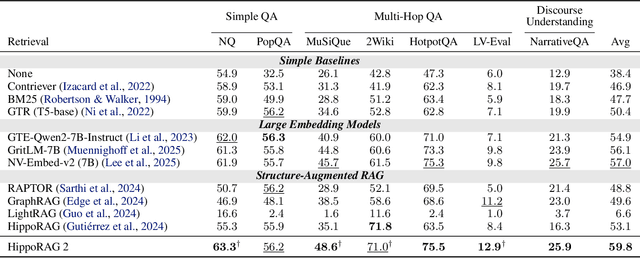
Our ability to continuously acquire, organize, and leverage knowledge is a key feature of human intelligence that AI systems must approximate to unlock their full potential. Given the challenges in continual learning with large language models (LLMs), retrieval-augmented generation (RAG) has become the dominant way to introduce new information. However, its reliance on vector retrieval hinders its ability to mimic the dynamic and interconnected nature of human long-term memory. Recent RAG approaches augment vector embeddings with various structures like knowledge graphs to address some of these gaps, namely sense-making and associativity. However, their performance on more basic factual memory tasks drops considerably below standard RAG. We address this unintended deterioration and propose HippoRAG 2, a framework that outperforms standard RAG comprehensively on factual, sense-making, and associative memory tasks. HippoRAG 2 builds upon the Personalized PageRank algorithm used in HippoRAG and enhances it with deeper passage integration and more effective online use of an LLM. This combination pushes this RAG system closer to the effectiveness of human long-term memory, achieving a 7% improvement in associative memory tasks over the state-of-the-art embedding model while also exhibiting superior factual knowledge and sense-making memory capabilities. This work paves the way for non-parametric continual learning for LLMs. Our code and data will be released at https://github.com/OSU-NLP-Group/HippoRAG.
Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents
Oct 07, 2024



Multimodal large language models (MLLMs) are transforming the capabilities of graphical user interface (GUI) agents, facilitating their transition from controlled simulations to complex, real-world applications across various platforms. However, the effectiveness of these agents hinges on the robustness of their grounding capability. Current GUI agents predominantly utilize text-based representations such as HTML or accessibility trees, which, despite their utility, often introduce noise, incompleteness, and increased computational overhead. In this paper, we advocate a human-like embodiment for GUI agents that perceive the environment entirely visually and directly take pixel-level operations on the GUI. The key is visual grounding models that can accurately map diverse referring expressions of GUI elements to their coordinates on the GUI across different platforms. We show that a simple recipe, which includes web-based synthetic data and slight adaptation of the LLaVA architecture, is surprisingly effective for training such visual grounding models. We collect the largest dataset for GUI visual grounding so far, containing 10M GUI elements and their referring expressions over 1.3M screenshots, and use it to train UGround, a strong universal visual grounding model for GUI agents. Empirical results on six benchmarks spanning three categories (grounding, offline agent, and online agent) show that 1) UGround substantially outperforms existing visual grounding models for GUI agents, by up to 20% absolute, and 2) agents with UGround outperform state-of-the-art agents, despite the fact that existing agents use additional text-based input while ours only uses visual perception. These results provide strong support for the feasibility and promises of GUI agents that navigate the digital world as humans do.
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
May 23, 2024



In order to thrive in hostile and ever-changing natural environments, mammalian brains evolved to store large amounts of knowledge about the world and continually integrate new information while avoiding catastrophic forgetting. Despite the impressive accomplishments, large language models (LLMs), even with retrieval-augmented generation (RAG), still struggle to efficiently and effectively integrate a large amount of new experiences after pre-training. In this work, we introduce HippoRAG, a novel retrieval framework inspired by the hippocampal indexing theory of human long-term memory to enable deeper and more efficient knowledge integration over new experiences. HippoRAG synergistically orchestrates LLMs, knowledge graphs, and the Personalized PageRank algorithm to mimic the different roles of neocortex and hippocampus in human memory. We compare HippoRAG with existing RAG methods on multi-hop question answering and show that our method outperforms the state-of-the-art methods remarkably, by up to 20%. Single-step retrieval with HippoRAG achieves comparable or better performance than iterative retrieval like IRCoT while being 10-30 times cheaper and 6-13 times faster, and integrating HippoRAG into IRCoT brings further substantial gains. Finally, we show that our method can tackle new types of scenarios that are out of reach of existing methods. Code and data are available at https://github.com/OSU-NLP-Group/HippoRAG.
Middleware for LLMs: Tools Are Instrumental for Language Agents in Complex Environments
Feb 22, 2024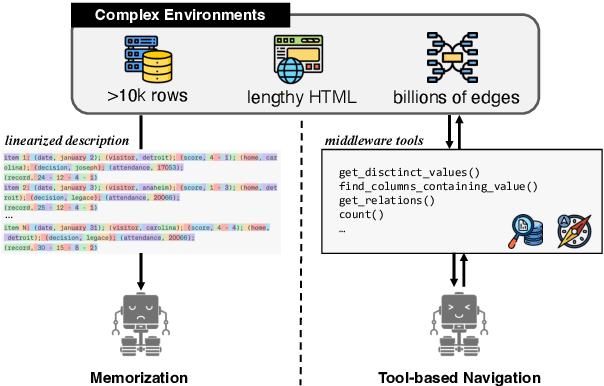



The applications of large language models (LLMs) have expanded well beyond the confines of text processing, signaling a new era where LLMs are envisioned as generalist language agents capable of operating within complex real-world environments. These environments are often highly expansive, making it impossible for the LLM to process them within its short-term memory. Motivated by recent research on extending the capabilities of LLMs with tools, this paper investigates the intriguing potential of tools to augment LLMs in handling such complexity. To this end, we design customized tools to aid in the proactive exploration within these massive environments. Such tools can serve as a middleware layer shielding the LLM from environmental complexity. In two representative complex environments -- knowledge bases (KBs) and databases -- we demonstrate the significant potential of augmenting language agents with tools in complex environments. Notably, equipped with these tools, GPT-4 achieves 2.8X the performance of the best baseline in tasks requiring access to database content and 2.2X in KB tasks. Our findings illuminate the path for advancing language agents in complex real-world applications.
Data Distribution Bottlenecks in Grounding Language Models to Knowledge Bases
Sep 15, 2023



Language models (LMs) have already demonstrated remarkable abilities in understanding and generating both natural and formal language. Despite these advances, their integration with real-world environments such as large-scale knowledge bases (KBs) remains an underdeveloped area, affecting applications such as semantic parsing and indulging in "hallucinated" information. This paper is an experimental investigation aimed at uncovering the robustness challenges that LMs encounter when tasked with knowledge base question answering (KBQA). The investigation covers scenarios with inconsistent data distribution between training and inference, such as generalization to unseen domains, adaptation to various language variations, and transferability across different datasets. Our comprehensive experiments reveal that even when employed with our proposed data augmentation techniques, advanced small and large language models exhibit poor performance in various dimensions. While the LM is a promising technology, the robustness of the current form in dealing with complex environments is fragile and of limited practicality because of the data distribution issue. This calls for future research on data collection and LM learning paradims.
Question Decomposition Tree for Answering Complex Questions over Knowledge Bases
Jun 13, 2023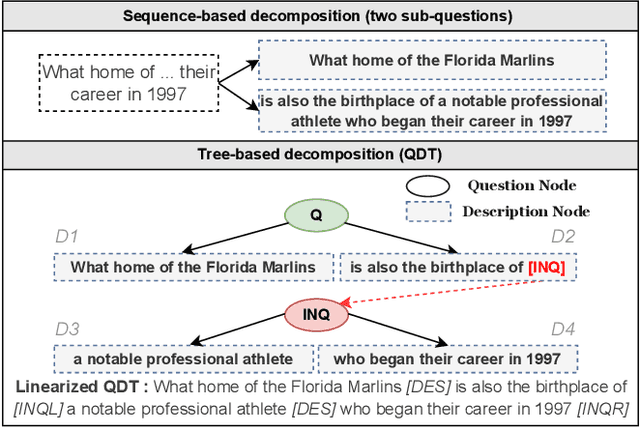


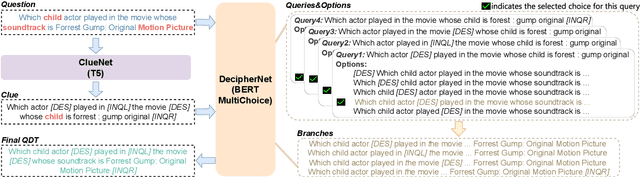
Knowledge base question answering (KBQA) has attracted a lot of interest in recent years, especially for complex questions which require multiple facts to answer. Question decomposition is a promising way to answer complex questions. Existing decomposition methods split the question into sub-questions according to a single compositionality type, which is not sufficient for questions involving multiple compositionality types. In this paper, we propose Question Decomposition Tree (QDT) to represent the structure of complex questions. Inspired by recent advances in natural language generation (NLG), we present a two-staged method called Clue-Decipher to generate QDT. It can leverage the strong ability of NLG model and simultaneously preserve the original questions. To verify that QDT can enhance KBQA task, we design a decomposition-based KBQA system called QDTQA. Extensive experiments show that QDTQA outperforms previous state-of-the-art methods on ComplexWebQuestions dataset. Besides, our decomposition method improves an existing KBQA system by 12% and sets a new state-of-the-art on LC-QuAD 1.0.
TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Bases
Oct 24, 2022



Pre-trained language models (PLMs) have shown their effectiveness in multiple scenarios. However, KBQA remains challenging, especially regarding coverage and generalization settings. This is due to two main factors: i) understanding the semantics of both questions and relevant knowledge from the KB; ii) generating executable logical forms with both semantic and syntactic correctness. In this paper, we present a new KBQA model, TIARA, which addresses those issues by applying multi-grained retrieval to help the PLM focus on the most relevant KB contexts, viz., entities, exemplary logical forms, and schema items. Moreover, constrained decoding is used to control the output space and reduce generation errors. Experiments over important benchmarks demonstrate the effectiveness of our approach. TIARA outperforms previous SOTA, including those using PLMs or oracle entity annotations, by at least 4.1 and 1.1 F1 points on GrailQA and WebQuestionsSP, respectively.
Deep Learning-based Sequential Recommender Systems: Concepts, Algorithms, and Evaluations
Apr 30, 2019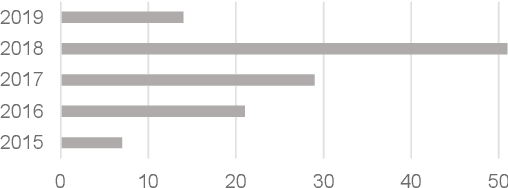
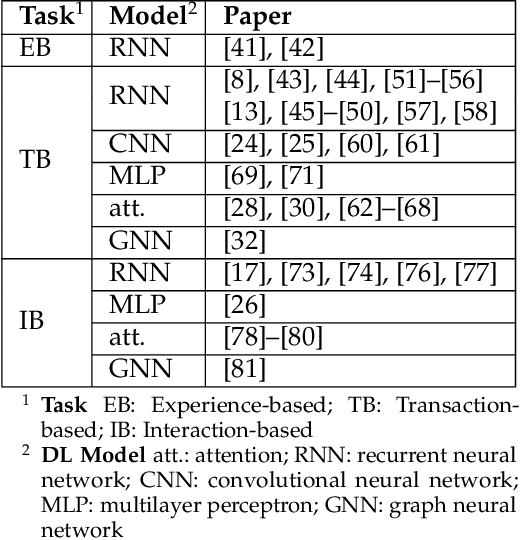
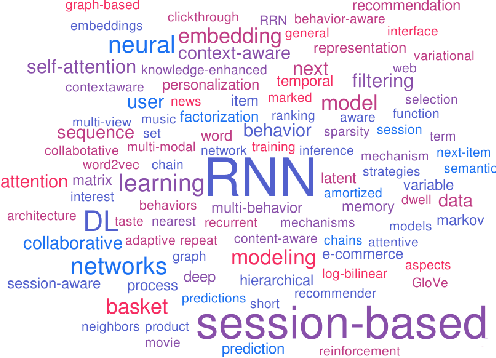
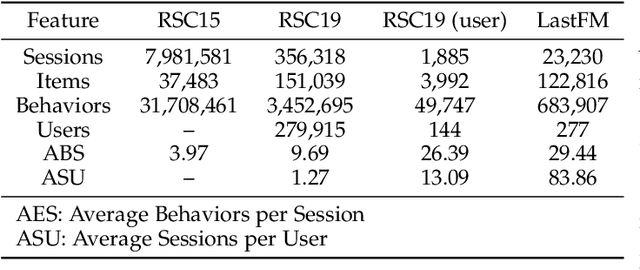
In the field of sequential recommendation, deep learning methods have received a lot of attention in the past few years and surpassed traditional models such as Markov chain-based and factorization-based ones. However, DL-based methods also have some critical drawbacks, such as insufficient modeling of user representation and ignoring to distinguish the different types of interactions (i.e., user behavior) among users and items. In this view, this survey focuses on DL-based sequential recommender systems by taking the aforementioned issues into consideration. Specifically, we illustrate the concept of sequential recommendation, propose a categorization of existing algorithms in terms of three types of behavioral sequence, summarize the key factors affecting the performance of DL-based models, and conduct corresponding evaluations to demonstrate the effects of these factors. We conclude this survey by systematically outlining future directions and challenges in this field.