 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Scale Spatial-Temporal Network for Wireless Video Transmission
Nov 15, 2024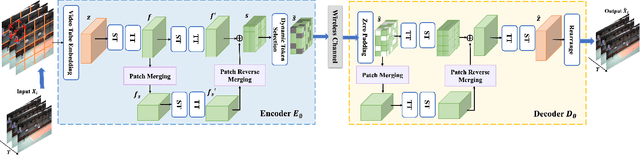
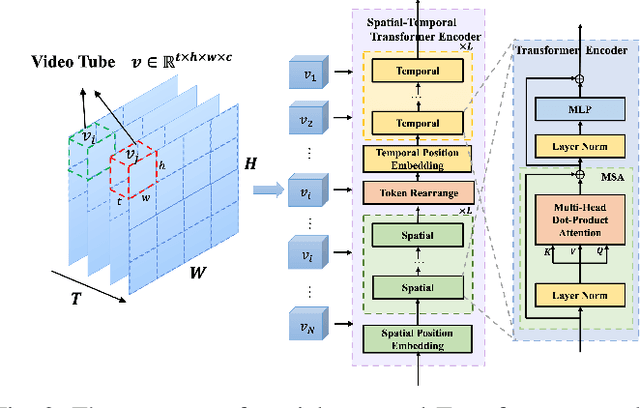
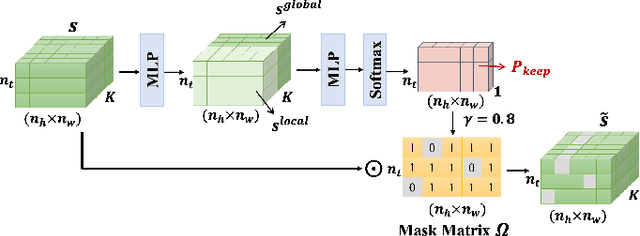
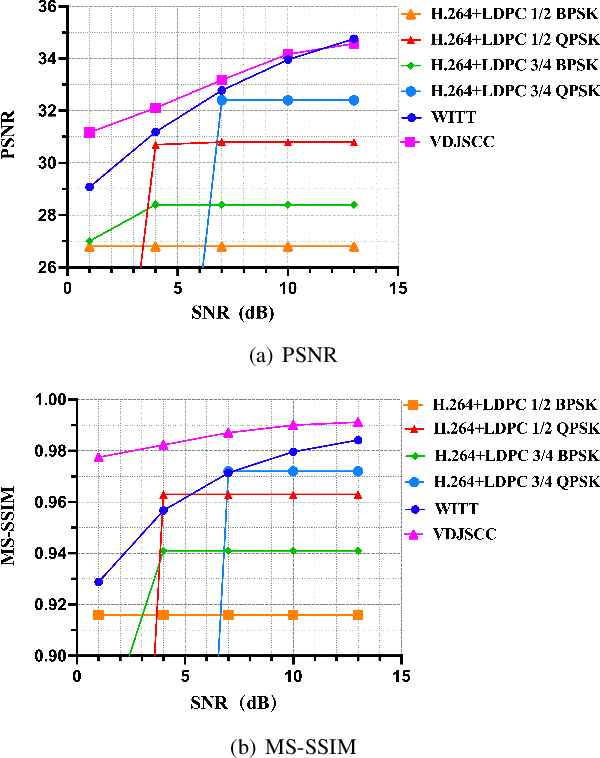
Deep joint source-channel coding (DeepJSCC) has shown promise in wireless transmission of text, speech, and images within the realm of semantic communication. However, wireless video transmission presents greater challenges due to the difficulty of extracting and compactly representing both spatial and temporal features, as well as its significant bandwidth and computational resource requirements. In response, we propose a novel video DeepJSCC (VDJSCC) approach to enable end-to-end video transmission over a wireless channel. Our approach involves the design of a multi-scale vision Transformer encoder and decoder to effectively capture spatial-temporal representations over long-term frames. Additionally, we propose a dynamic token selection module to mask less semantically important tokens from spatial or temporal dimensions, allowing for content-adaptive variable-length video coding by adjusting the token keep ratio. Experimental results demonstrate the effectiveness of our VDJSCC approach compared to digital schemes that use separate source and channel codes, as well as other DeepJSCC schemes, in terms of reconstruction quality and bandwidth reduction.
Multitask deep learning with spectral knowledge for hyperspectral image classification
May 11, 2019

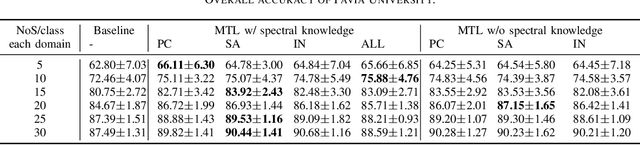

In this letter, we introduce multitask learning to hyperspectral image classification. Deep learning models have achieved promising results on hyperspectral image classification, but their performance highly rely on sufficient labeled samples, which are scarce on hyperspectral images. However, samples from multiple data sets might be sufficient to train one deep learning model, thereby improving its performance. To do so, spectral knowledge is introduced to ensure that the shared features are similar across domains. Four hyperspectral data sets were used in the experiments. We achieved better classification accuracies on three data sets (Pavia University, Indian Pines, and Pavia Center) originally with poor results or simple classification systems and competitive results on Salinas Valley data originally with a complex classification system. Spectral knowledge is useful to prevent the deep network from overfitting when the training samples were scarce. The proposed method successfully utilized samples from multiple data sets to increase its performance.
Impacts of Dirty Data: and Experimental Evaluation
Mar 16, 2018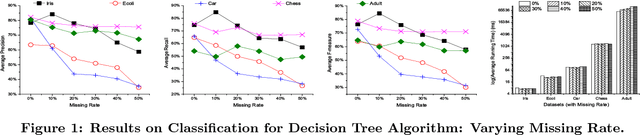
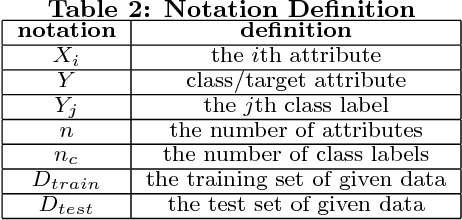
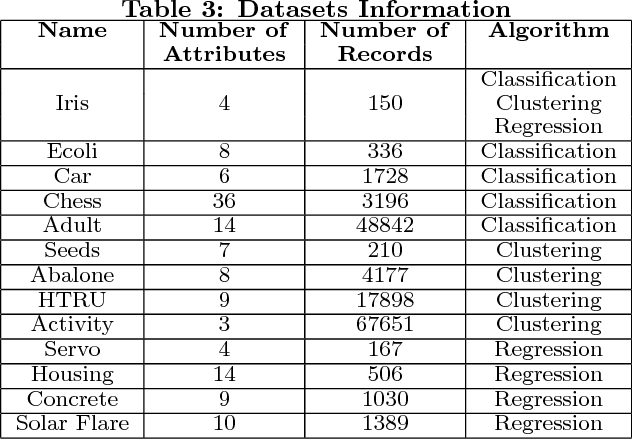
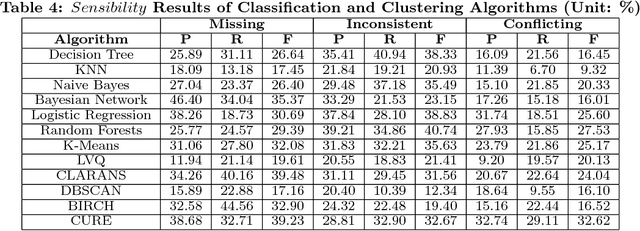
Data quality issues have attracted widespread attention due to the negative impacts of dirty data on data mining and machine learning results. The relationship between data quality and the accuracy of results could be applied on the selection of the appropriate algorithm with the consideration of data quality and the determination of the data share to clean. However, rare research has focused on exploring such relationship. Motivated by this, this paper conducts an experimental comparison for the effects of missing, inconsistent and conflicting data on classification, clustering, and regression algorithms. Based on the experimental findings, we provide guidelines for algorithm selection and data cleaning.