 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Stop Reusing: Dynamic Gradient Gating for Sample-Efficient RLVR
May 19, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become the dominant paradigm for advanced reasoning in Large Language Models (LLMs), but rollout samples are expensive to obtain, making sample efficiency a critical bottleneck. A natural remedy is to reuse each rollout batch for multiple gradient updates, a standard practice in classical RL. Yet in RLVR, this amplifies policy shift, leading to severe performance degradation. Detecting the onset of degradation early enough to stop reuse remains an open and challenging problem. We close this gap by identifying the \textit{Disproportionate Weight Divergence (DWD)} phenomenon: performance degradation is synchronized with a sharp surge in the \texttt{lm\_head} weight change, while intermediate layers remain stable. Empirically, we verify that DWD emerges consistently across diverse LLMs and tasks. Theoretically, we prove that (i) harmful gradients concentrate at the \texttt{lm\_head} while intermediate layers are structurally attenuated, and (ii) the \texttt{lm\_head} gradient norm lower-bounds the policy divergence. These results establish the \texttt{lm\_head} gradient norm as a principled, real-time signal of catastrophic policy shift. Guided by this insight, we propose \textit{Dynamic Gradient Gating (DGG)}, a lightweight intervention that monitors the \texttt{lm\_head} gradient norm in real time and intercepts harmful gradients before they corrupt the optimizer. DGG consistently matches or exceeds the standard single-use baseline, achieving up to $2.93\times$ sample efficiency and $2.14\times$ wall-clock speedup across math, ALFWorld, WebShop, and search-augmented QA tasks.
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
May 07, 2026A persistent skill library allows language model agents to reuse successful strategies across tasks. Maintaining such a library requires three coupled capabilities. The agent selects a relevant skill, utilizes it during execution, and distills new skills from experience. Existing methods optimize these capabilities in isolation or with separate reward sources, resulting in partial and conflicting evolution. We propose Skill1, a framework that trains a single policy to co-evolve skill selection, utilization, and distillation toward a shared task-outcome objective. The policy generates a query to search the skill library, re-ranks candidates to select one, solves the task conditioned on it, and distills a new skill from the trajectory. All learning derives from a single task-outcome signal. Its low-frequency trend credits selection and its high-frequency variation credits distillation. Experiments on ALFWorld and WebShop show that Skill1 outperforms prior skill-based and reinforcement learning baselines. Training dynamics confirm the co-evolution of the three capabilities, and ablations show that removing any credit signal degrades the evolution.
AMIA: Automatic Masking and Joint Intention Analysis Makes LVLMs Robust Jailbreak Defenders
May 30, 2025We introduce AMIA, a lightweight, inference-only defense for Large Vision-Language Models (LVLMs) that (1) Automatically Masks a small set of text-irrelevant image patches to disrupt adversarial perturbations, and (2) conducts joint Intention Analysis to uncover and mitigate hidden harmful intents before response generation. Without any retraining, AMIA improves defense success rates across diverse LVLMs and jailbreak benchmarks from an average of 52.4% to 81.7%, preserves general utility with only a 2% average accuracy drop, and incurs only modest inference overhead. Ablation confirms both masking and intention analysis are essential for a robust safety-utility trade-off.
The Energy Loss Phenomenon in RLHF: A New Perspective on Mitigating Reward Hacking
Jan 31, 2025



This work identifies the Energy Loss Phenomenon in Reinforcement Learning from Human Feedback (RLHF) and its connection to reward hacking. Specifically, energy loss in the final layer of a Large Language Model (LLM) gradually increases during the RL process, with an excessive increase in energy loss characterizing reward hacking. Beyond empirical analysis, we further provide a theoretical foundation by proving that, under mild conditions, the increased energy loss reduces the upper bound of contextual relevance in LLMs, which is a critical aspect of reward hacking as the reduced contextual relevance typically indicates overfitting to reward model-favored patterns in RL. To address this issue, we propose an Energy loss-aware PPO algorithm (EPPO) which penalizes the increase in energy loss in the LLM's final layer during reward calculation to prevent excessive energy loss, thereby mitigating reward hacking. We theoretically show that EPPO can be conceptually interpreted as an entropy-regularized RL algorithm, which provides deeper insights into its effectiveness. Extensive experiments across various LLMs and tasks demonstrate the commonality of the energy loss phenomenon, as well as the effectiveness of \texttt{EPPO} in mitigating reward hacking and improving RLHF performance.
HyperSIGMA: Hyperspectral Intelligence Comprehension Foundation Model
Jun 17, 2024



Foundation models (FMs) are revolutionizing the analysis and understanding of remote sensing (RS) scenes, including aerial RGB, multispectral, and SAR images. However, hyperspectral images (HSIs), which are rich in spectral information, have not seen much application of FMs, with existing methods often restricted to specific tasks and lacking generality. To fill this gap, we introduce HyperSIGMA, a vision transformer-based foundation model for HSI interpretation, scalable to over a billion parameters. To tackle the spectral and spatial redundancy challenges in HSIs, we introduce a novel sparse sampling attention (SSA) mechanism, which effectively promotes the learning of diverse contextual features and serves as the basic block of HyperSIGMA. HyperSIGMA integrates spatial and spectral features using a specially designed spectral enhancement module. In addition, we construct a large-scale hyperspectral dataset, HyperGlobal-450K, for pre-training, which contains about 450K hyperspectral images, significantly surpassing existing datasets in scale. Extensive experiments on various high-level and low-level HSI tasks demonstrate HyperSIGMA's versatility and superior representational capability compared to current state-of-the-art methods. Moreover, HyperSIGMA shows significant advantages in scalability, robustness, cross-modal transferring capability, and real-world applicability.
Mitigating Reward Hacking via Information-Theoretic Reward Modeling
Feb 16, 2024Despite the success of reinforcement learning from human feedback (RLHF) in aligning language models with human values, reward hacking, also termed reward overoptimization, remains a critical challenge, which primarily stems from limitations in reward modeling, i.e., generalizability of the reward model and inconsistency in the preference dataset. In this work, we tackle this problem from an information theoretic-perspective, and propose a generalizable and robust framework for reward modeling, namely InfoRM, by introducing a variational information bottleneck objective to filter out irrelevant information and developing a mechanism for model complexity modulation. Notably, we further identify a correlation between overoptimization and outliers in the latent space, establishing InfoRM as a promising tool for detecting reward overoptimization. Inspired by this finding, we propose the Integrated Cluster Deviation Score (ICDS), which quantifies deviations in the latent space, as an indicator of reward overoptimization to facilitate the development of online mitigation strategies. Extensive experiments on a wide range of settings and model scales (70M, 440M, 1.4B, and 7B) support the effectiveness of InfoRM. Further analyses reveal that InfoRM's overoptimization detection mechanism is effective, potentially signifying a notable advancement in the field of RLHF. Code will be released upon acceptance.
DDS2M: Self-Supervised Denoising Diffusion Spatio-Spectral Model for Hyperspectral Image Restoration
Mar 19, 2023Diffusion models have recently received a surge of interest due to their impressive performance for image restoration, especially in terms of noise robustness. However, existing diffusion-based methods are trained on a large amount of training data and perform very well in-distribution, but can be quite susceptible to distribution shift. This is especially inappropriate for data-starved hyperspectral image (HSI) restoration. To tackle this problem, this work puts forth a self-supervised diffusion model for HSI restoration, namely Denoising Diffusion Spatio-Spectral Model (\texttt{DDS2M}), which works by inferring the parameters of the proposed Variational Spatio-Spectral Module (VS2M) during the reverse diffusion process, solely using the degraded HSI without any extra training data. In VS2M, a variational inference-based loss function is customized to enable the untrained spatial and spectral networks to learn the posterior distribution, which serves as the transitions of the sampling chain to help reverse the diffusion process. Benefiting from its self-supervised nature and the diffusion process, \texttt{DDS2M} enjoys stronger generalization ability to various HSIs compared to existing diffusion-based methods and superior robustness to noise compared to existing HSI restoration methods. Extensive experiments on HSI denoising, noisy HSI completion and super-resolution on a variety of HSIs demonstrate \texttt{DDS2M}'s superiority over the existing task-specific state-of-the-arts.
Uncertainty-Aware Unsupervised Image Deblurring with Deep Priors Guided by Domain Knowledge
Oct 09, 2022


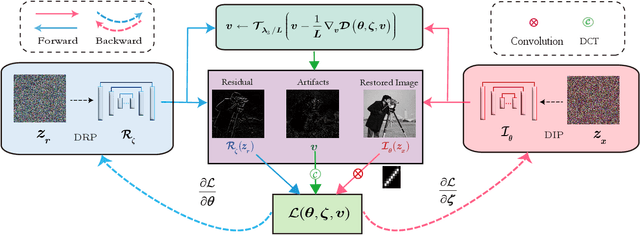
Non-blind deblurring methods achieve decent performance under the accurate blur kernel assumption. Since the kernel error is inevitable in practice, ringing artifacts are often introduced by non-blind deblurring. Recently, semi-blind deblurring methods can handle kernel uncertainty by introducing the prior of the kernel (or induced) error. However, how to design a suitable prior for the kernel (or induced) error remains challenging. Hand-crafted prior, incorporating domain knowledge, generally performs well but may lead to poor performance when kernel (or induced) error is complex. Data-driven prior, which excessively depends on the diversity and abundance of training data, is vulnerable to out-of-distribution blurs and images. To address this challenge, we suggest a data-free deep prior for the kernel induced error (termed as residual) expressed by a customized untrained deep neural network, which allows us to flexibly adapt to different blurs and images in real scenarios. By organically integrating the respective strengths of deep priors and hand-crafted priors, we propose an unsupervised semi-blind deblurring model which recovers the latent image from the blurry image and inaccurate blur kernel. To tackle the formulated model, an efficient alternating minimization algorithm is developed. Extensive experiments demonstrate the superiority of the proposed method to both data-driven prior and hand-crafted prior based methods in terms of the image quality and the robustness to the kernel error.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022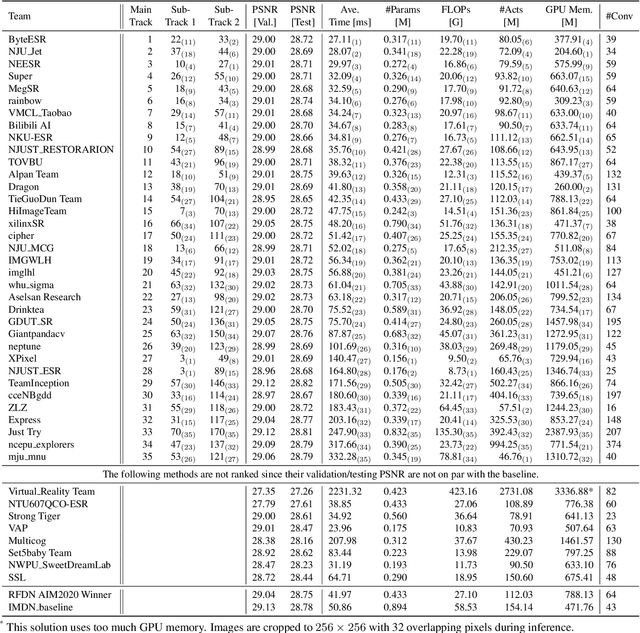
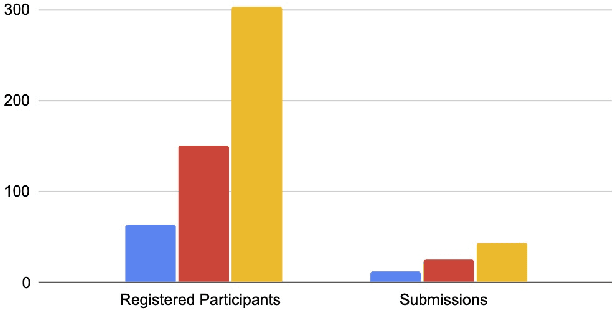
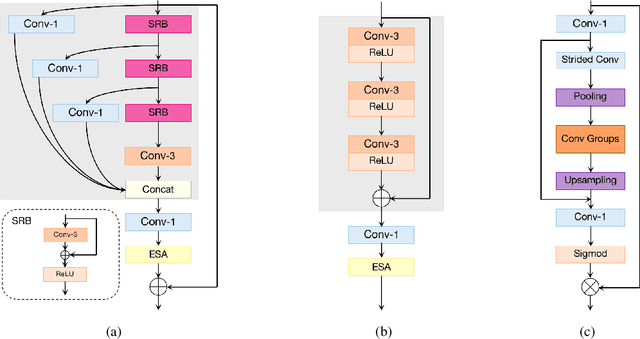
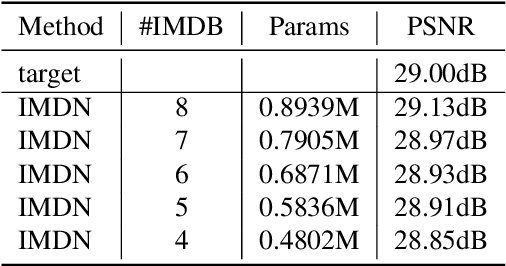
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.