 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Driven Prompt Learning: A Joint Framework for Multi-modal Cloud Removal and Segmentation
Jan 17, 2026Optical remote sensing imagery is indispensable for Earth observation, yet persistent cloud occlusion limits its downstream utility. Most cloud removal (CR) methods are optimized for low-level fidelity and can over-smooth textures and boundaries that are critical for analysis-ready data (ARD), leading to a mismatch between visually plausible restoration and semantic utility. To bridge this gap, we propose TDP-CR, a task-driven multimodal framework that jointly performs cloud removal and land-cover segmentation. Central to our approach is a Prompt-Guided Fusion (PGF) mechanism, which utilizes a learnable degradation prompt to encode cloud thickness and spatial uncertainty. By combining global channel context with local prompt-conditioned spatial bias, PGF adaptively integrates Synthetic Aperture Radar (SAR) information only where optical data is corrupted. We further introduce a parameter-efficient two-phase training strategy that decouples reconstruction and semantic representation learning. Experiments on the LuojiaSET-OSFCR dataset demonstrate the superiority of our framework: TDP-CR surpasses heavy state-of-the-art baselines by 0.18 dB in PSNR while using only 15\% of the parameters, and achieves a 1.4\% improvement in mIoU consistently against multi-task competitors, effectively delivering analysis-ready data.
Spiking Meets Attention: Efficient Remote Sensing Image Super-Resolution with Attention Spiking Neural Networks
Mar 06, 2025Spiking neural networks (SNNs) are emerging as a promising alternative to traditional artificial neural networks (ANNs), offering biological plausibility and energy efficiency. Despite these merits, SNNs are frequently hampered by limited capacity and insufficient representation power, yet remain underexplored in remote sensing super-resolution (SR) tasks. In this paper, we first observe that spiking signals exhibit drastic intensity variations across diverse textures, highlighting an active learning state of the neurons. This observation motivates us to apply SNNs for efficient SR of RSIs. Inspired by the success of attention mechanisms in representing salient information, we devise the spiking attention block (SAB), a concise yet effective component that optimizes membrane potentials through inferred attention weights, which, in turn, regulates spiking activity for superior feature representation. Our key contributions include: 1) we bridge the independent modulation between temporal and channel dimensions, facilitating joint feature correlation learning, and 2) we access the global self-similar patterns in large-scale remote sensing imagery to infer spatial attention weights, incorporating effective priors for realistic and faithful reconstruction. Building upon SAB, we proposed SpikeSR, which achieves state-of-the-art performance across various remote sensing benchmarks such as AID, DOTA, and DIOR, while maintaining high computational efficiency. The code of SpikeSR will be available upon paper acceptance.
Super-Resolution for Remote Sensing Imagery via the Coupling of a Variational Model and Deep Learning
Dec 13, 2024



Image super-resolution (SR) is an effective way to enhance the spatial resolution and detail information of remote sensing images, to obtain a superior visual quality. As SR is severely ill-conditioned, effective image priors are necessary to regularize the solution space and generate the corresponding high-resolution (HR) image. In this paper, we propose a novel gradient-guided multi-frame super-resolution (MFSR) framework for remote sensing imagery reconstruction. The framework integrates a learned gradient prior as the regularization term into a model-based optimization method. Specifically, the local gradient regularization (LGR) prior is derived from the deep residual attention network (DRAN) through gradient profile transformation. The non-local total variation (NLTV) prior is characterized using the spatial structure similarity of the gradient patches with the maximum a posteriori (MAP) model. The modeled prior performs well in preserving edge smoothness and suppressing visual artifacts, while the learned prior is effective in enhancing sharp edges and recovering fine structures. By incorporating the two complementary priors into an adaptive norm based reconstruction framework, the mixed L1 and L2 regularization minimization problem is optimized to achieve the required HR remote sensing image. Extensive experimental results on remote sensing data demonstrate that the proposed method can produce visually pleasant images and is superior to several of the state-of-the-art SR algorithms in terms of the quantitative evaluation.
A Single-Frame and Multi-Frame Cascaded Image Super-Resolution Method
Dec 13, 2024



The objective of image super-resolution is to reconstruct a high-resolution (HR) image with the prior knowledge from one or several low-resolution (LR) images. However, in the real world, due to the limited complementary information, the performance of both single-frame and multi-frame super-resolution reconstruction degrades rapidly as the magnification increases. In this paper, we propose a novel two-step image super resolution method concatenating multi-frame super-resolution (MFSR) with single-frame super-resolution (SFSR), to progressively upsample images to the desired resolution. The proposed method consisting of an L0-norm constrained reconstruction scheme and an enhanced residual back-projection network, integrating the flexibility of the variational modelbased method and the feature learning capacity of the deep learning-based method. To verify the effectiveness of the proposed algorithm, extensive experiments with both simulated and real world sequences were implemented. The experimental results show that the proposed method yields superior performance in both objective and perceptual quality measurements. The average PSNRs of the cascade model in set5 and set14 are 33.413 dB and 29.658 dB respectively, which are 0.76 dB and 0.621 dB more than the baseline method. In addition, the experiment indicates that this cascade model can be robustly applied to different SFSR and MFSR methods.
* 20 pages, 13 figures
Tortho-Gaussian: Splatting True Digital Orthophoto Maps
Nov 29, 2024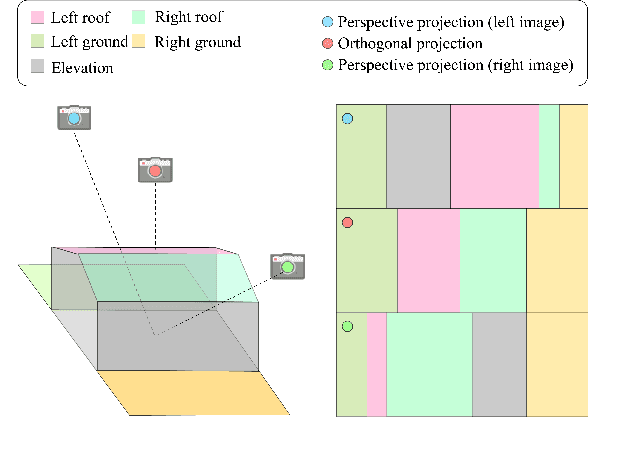

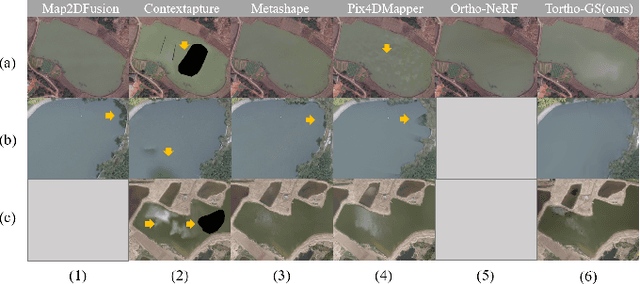

True Digital Orthophoto Maps (TDOMs) are essential products for digital twins and Geographic Information Systems (GIS). Traditionally, TDOM generation involves a complex set of traditional photogrammetric process, which may deteriorate due to various challenges, including inaccurate Digital Surface Model (DSM), degenerated occlusion detections, and visual artifacts in weak texture regions and reflective surfaces, etc. To address these challenges, we introduce TOrtho-Gaussian, a novel method inspired by 3D Gaussian Splatting (3DGS) that generates TDOMs through orthogonal splatting of optimized anisotropic Gaussian kernel. More specifically, we first simplify the orthophoto generation by orthographically splatting the Gaussian kernels onto 2D image planes, formulating a geometrically elegant solution that avoids the need for explicit DSM and occlusion detection. Second, to produce TDOM of large-scale area, a divide-and-conquer strategy is adopted to optimize memory usage and time efficiency of training and rendering for 3DGS. Lastly, we design a fully anisotropic Gaussian kernel that adapts to the varying characteristics of different regions, particularly improving the rendering quality of reflective surfaces and slender structures. Extensive experimental evaluations demonstrate that our method outperforms existing commercial software in several aspects, including the accuracy of building boundaries, the visual quality of low-texture regions and building facades. These results underscore the potential of our approach for large-scale urban scene reconstruction, offering a robust alternative for enhancing TDOM quality and scalability.
Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution
May 08, 2024


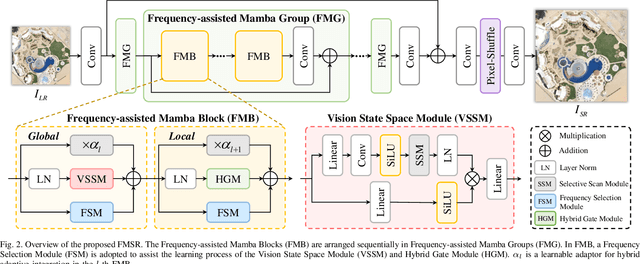
Recent progress in remote sensing image (RSI) super-resolution (SR) has exhibited remarkable performance using deep neural networks, e.g., Convolutional Neural Networks and Transformers. However, existing SR methods often suffer from either a limited receptive field or quadratic computational overhead, resulting in sub-optimal global representation and unacceptable computational costs in large-scale RSI. To alleviate these issues, we develop the first attempt to integrate the Vision State Space Model (Mamba) for RSI-SR, which specializes in processing large-scale RSI by capturing long-range dependency with linear complexity. To achieve better SR reconstruction, building upon Mamba, we devise a Frequency-assisted Mamba framework, dubbed FMSR, to explore the spatial and frequent correlations. In particular, our FMSR features a multi-level fusion architecture equipped with the Frequency Selection Module (FSM), Vision State Space Module (VSSM), and Hybrid Gate Module (HGM) to grasp their merits for effective spatial-frequency fusion. Recognizing that global and local dependencies are complementary and both beneficial for SR, we further recalibrate these multi-level features for accurate feature fusion via learnable scaling adaptors. Extensive experiments on AID, DOTA, and DIOR benchmarks demonstrate that our FMSR outperforms state-of-the-art Transformer-based methods HAT-L in terms of PSNR by 0.11 dB on average, while consuming only 28.05% and 19.08% of its memory consumption and complexity, respectively.
Deep Blind Super-Resolution for Satellite Video
Jan 13, 2024



Recent efforts have witnessed remarkable progress in Satellite Video Super-Resolution (SVSR). However, most SVSR methods usually assume the degradation is fixed and known, e.g., bicubic downsampling, which makes them vulnerable in real-world scenes with multiple and unknown degradations. To alleviate this issue, blind SR has thus become a research hotspot. Nevertheless, existing approaches are mainly engaged in blur kernel estimation while losing sight of another critical aspect for VSR tasks: temporal compensation, especially compensating for blurry and smooth pixels with vital sharpness from severely degraded satellite videos. Therefore, this paper proposes a practical Blind SVSR algorithm (BSVSR) to explore more sharp cues by considering the pixel-wise blur levels in a coarse-to-fine manner. Specifically, we employed multi-scale deformable convolution to coarsely aggregate the temporal redundancy into adjacent frames by window-slid progressive fusion. Then the adjacent features are finely merged into mid-feature using deformable attention, which measures the blur levels of pixels and assigns more weights to the informative pixels, thus inspiring the representation of sharpness. Moreover, we devise a pyramid spatial transformation module to adjust the solution space of sharp mid-feature, resulting in flexible feature adaptation in multi-level domains. Quantitative and qualitative evaluations on both simulated and real-world satellite videos demonstrate that our BSVSR performs favorably against state-of-the-art non-blind and blind SR models. Code will be available at https://github.com/XY-boy/Blind-Satellite-VSR
* Published in IEEE TGRS
TDiffDe: A Truncated Diffusion Model for Remote Sensing Hyperspectral Image Denoising
Nov 22, 2023



Hyperspectral images play a crucial role in precision agriculture, environmental monitoring or ecological analysis. However, due to sensor equipment and the imaging environment, the observed hyperspectral images are often inevitably corrupted by various noise. In this study, we proposed a truncated diffusion model, called TDiffDe, to recover the useful information in hyperspectral images gradually. Rather than starting from a pure noise, the input data contains image information in hyperspectral image denoising. Thus, we cut the trained diffusion model from small steps to avoid the destroy of valid information.
EDiffSR: An Efficient Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Oct 30, 2023



Recently, convolutional networks have achieved remarkable development in remote sensing image Super-Resoltuion (SR) by minimizing the regression objectives, e.g., MSE loss. However, despite achieving impressive performance, these methods often suffer from poor visual quality with over-smooth issues. Generative adversarial networks have the potential to infer intricate details, but they are easy to collapse, resulting in undesirable artifacts. To mitigate these issues, in this paper, we first introduce Diffusion Probabilistic Model (DPM) for efficient remote sensing image SR, dubbed EDiffSR. EDiffSR is easy to train and maintains the merits of DPM in generating perceptual-pleasant images. Specifically, different from previous works using heavy UNet for noise prediction, we develop an Efficient Activation Network (EANet) to achieve favorable noise prediction performance by simplified channel attention and simple gate operation, which dramatically reduces the computational budget. Moreover, to introduce more valuable prior knowledge into the proposed EDiffSR, a practical Conditional Prior Enhancement Module (CPEM) is developed to help extract an enriched condition. Unlike most DPM-based SR models that directly generate conditions by amplifying LR images, the proposed CPEM helps to retain more informative cues for accurate SR. Extensive experiments on four remote sensing datasets demonstrate that EDiffSR can restore visual-pleasant images on simulated and real-world remote sensing images, both quantitatively and qualitatively. The code of EDiffSR will be available at https://github.com/XY-boy/EDiffSR
Local-Global Temporal Difference Learning for Satellite Video Super-Resolution
Apr 10, 2023



Optical-flow-based and kernel-based approaches have been widely explored for temporal compensation in satellite video super-resolution (VSR). However, these techniques involve high computational consumption and are prone to fail under complex motions. In this paper, we proposed to exploit the well-defined temporal difference for efficient and robust temporal compensation. To fully utilize the temporal information within frames, we separately modeled the short-term and long-term temporal discrepancy since they provide distinctive complementary properties. Specifically, a short-term temporal difference module is designed to extract local motion representations from residual maps between adjacent frames, which provides more clues for accurate texture representation. Meanwhile, the global dependency in the entire frame sequence is explored via long-term difference learning. The differences between forward and backward segments are incorporated and activated to modulate the temporal feature, resulting in holistic global compensation. Besides, we further proposed a difference compensation unit to enrich the interaction between the spatial distribution of the target frame and compensated results, which helps maintain spatial consistency while refining the features to avoid misalignment. Extensive objective and subjective evaluation of five mainstream satellite videos demonstrates that the proposed method performs favorably for satellite VSR. Code will be available at \url{https://github.com/XY-boy/TDMVSR}