 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-Global Temporal Difference Learning for Satellite Video Super-Resolution
Apr 10, 2023



Optical-flow-based and kernel-based approaches have been widely explored for temporal compensation in satellite video super-resolution (VSR). However, these techniques involve high computational consumption and are prone to fail under complex motions. In this paper, we proposed to exploit the well-defined temporal difference for efficient and robust temporal compensation. To fully utilize the temporal information within frames, we separately modeled the short-term and long-term temporal discrepancy since they provide distinctive complementary properties. Specifically, a short-term temporal difference module is designed to extract local motion representations from residual maps between adjacent frames, which provides more clues for accurate texture representation. Meanwhile, the global dependency in the entire frame sequence is explored via long-term difference learning. The differences between forward and backward segments are incorporated and activated to modulate the temporal feature, resulting in holistic global compensation. Besides, we further proposed a difference compensation unit to enrich the interaction between the spatial distribution of the target frame and compensated results, which helps maintain spatial consistency while refining the features to avoid misalignment. Extensive objective and subjective evaluation of five mainstream satellite videos demonstrates that the proposed method performs favorably for satellite VSR. Code will be available at \url{https://github.com/XY-boy/TDMVSR}
Guidance and Evaluation: Semantic-Aware Image Inpainting for Mixed Scenes
Mar 17, 2020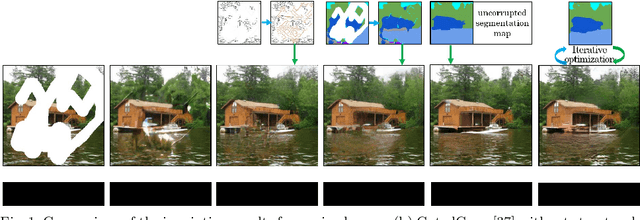
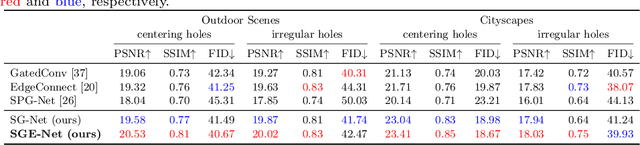
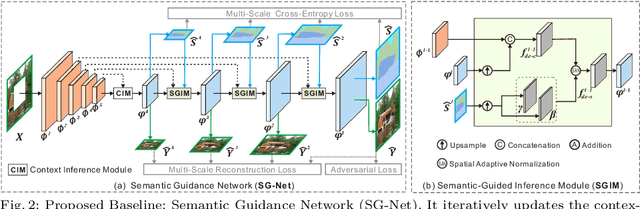

Completing a corrupted image with correct structures and reasonable textures for a mixed scene remains an elusive challenge. Since the missing hole in a mixed scene of a corrupted image often contains various semantic information, conventional two-stage approaches utilizing structural information often lead to the problem of unreliable structural prediction and ambiguous image texture generation. In this paper, we propose a Semantic Guidance and Evaluation Network (SGE-Net) to iteratively update the structural priors and the inpainted image in an interplay framework of semantics extraction and image inpainting. It utilizes semantic segmentation map as guidance in each scale of inpainting, under which location-dependent inferences are re-evaluated, and, accordingly, poorly-inferred regions are refined in subsequent scales. Extensive experiments on real-world images of mixed scenes demonstrated the superiority of our proposed method over state-of-the-art approaches, in terms of clear boundaries and photo-realistic textures.
A Real-time Global Inference Network for One-stage Referring Expression Comprehension
Dec 07, 2019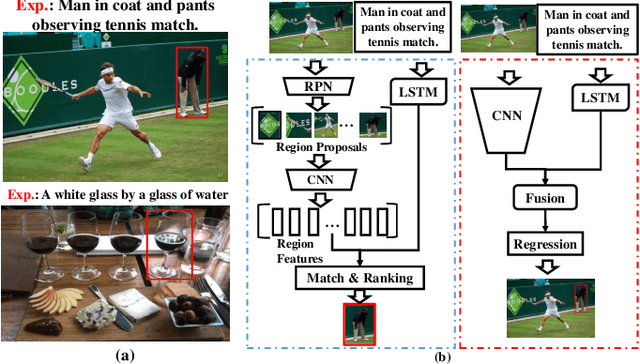
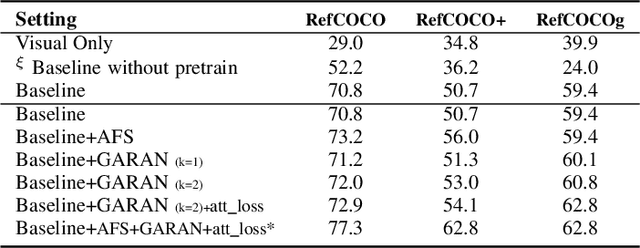
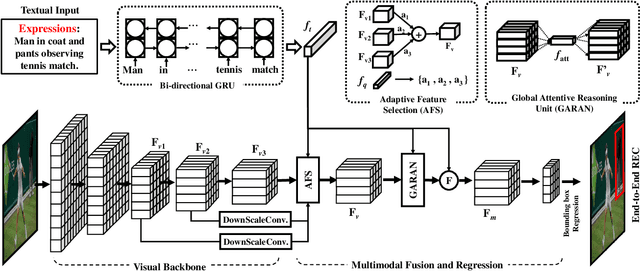

Referring Expression Comprehension (REC) is an emerging research spot in computer vision, which refers to detecting the target region in an image given an text description. Most existing REC methods follow a multi-stage pipeline, which are computationally expensive and greatly limit the application of REC. In this paper, we propose a one-stage model towards real-time REC, termed Real-time Global Inference Network (RealGIN). RealGIN addresses the diversity and complexity issues in REC with two innovative designs: the Adaptive Feature Selection (AFS) and the Global Attentive ReAsoNing unit (GARAN). AFS adaptively fuses features at different semantic levels to handle the varying content of expressions. GARAN uses the textual feature as a pivot to collect expression-related visual information from all regions, and thenselectively diffuse such information back to all regions, which provides sufficient context for modeling the complex linguistic conditions in expressions. On five benchmark datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, ReferIt and Flickr30k, the proposed RealGIN outperforms most prior works and achieves very competitive performances against the most advanced method, i.e., MAttNet. Most importantly, under the same hardware, RealGIN can boost the processing speed by about 10 times over the existing methods.