 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidance and Evaluation: Semantic-Aware Image Inpainting for Mixed Scenes
Paper and Code
Mar 17, 2020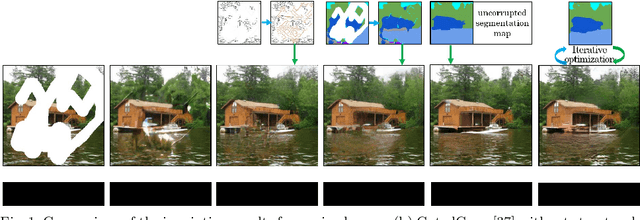
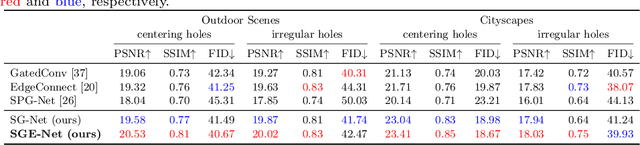
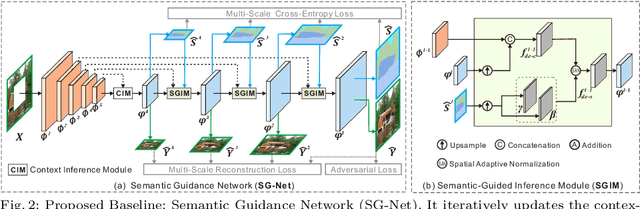

Completing a corrupted image with correct structures and reasonable textures for a mixed scene remains an elusive challenge. Since the missing hole in a mixed scene of a corrupted image often contains various semantic information, conventional two-stage approaches utilizing structural information often lead to the problem of unreliable structural prediction and ambiguous image texture generation. In this paper, we propose a Semantic Guidance and Evaluation Network (SGE-Net) to iteratively update the structural priors and the inpainted image in an interplay framework of semantics extraction and image inpainting. It utilizes semantic segmentation map as guidance in each scale of inpainting, under which location-dependent inferences are re-evaluated, and, accordingly, poorly-inferred regions are refined in subsequent scales. Extensive experiments on real-world images of mixed scenes demonstrated the superiority of our proposed method over state-of-the-art approaches, in terms of clear boundaries and photo-realistic textures.