 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePG-SAG: Parallel Gaussian Splatting for Fine-Grained Large-Scale Urban Buildings Reconstruction via Semantic-Aware Grouping
Jan 03, 2025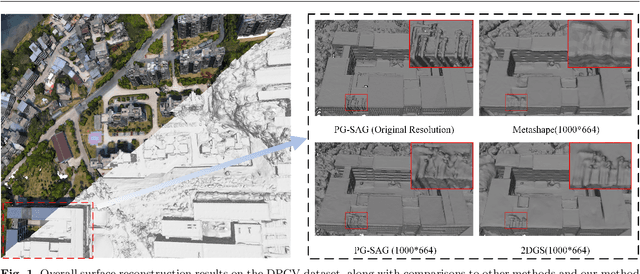
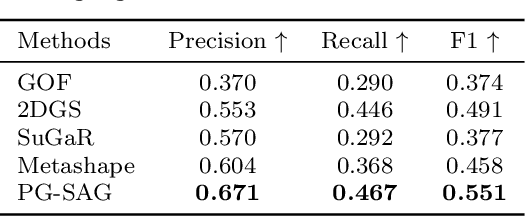


3D Gaussian Splatting (3DGS) has emerged as a transformative method in the field of real-time novel synthesis. Based on 3DGS, recent advancements cope with large-scale scenes via spatial-based partition strategy to reduce video memory and optimization time costs. In this work, we introduce a parallel Gaussian splatting method, termed PG-SAG, which fully exploits semantic cues for both partitioning and Gaussian kernel optimization, enabling fine-grained building surface reconstruction of large-scale urban areas without downsampling the original image resolution. First, the Cross-modal model - Language Segment Anything is leveraged to segment building masks. Then, the segmented building regions is grouped into sub-regions according to the visibility check across registered images. The Gaussian kernels for these sub-regions are optimized in parallel with masked pixels. In addition, the normal loss is re-formulated for the detected edges of masks to alleviate the ambiguities in normal vectors on edges. Finally, to improve the optimization of 3D Gaussians, we introduce a gradient-constrained balance-load loss that accounts for the complexity of the corresponding scenes, effectively minimizing the thread waiting time in the pixel-parallel rendering stage as well as the reconstruction lost. Extensive experiments are tested on various urban datasets, the results demonstrated the superior performance of our PG-SAG on building surface reconstruction, compared to several state-of-the-art 3DGS-based methods. Project Web:https://github.com/TFWang-9527/PG-SAG.
Tortho-Gaussian: Splatting True Digital Orthophoto Maps
Nov 29, 2024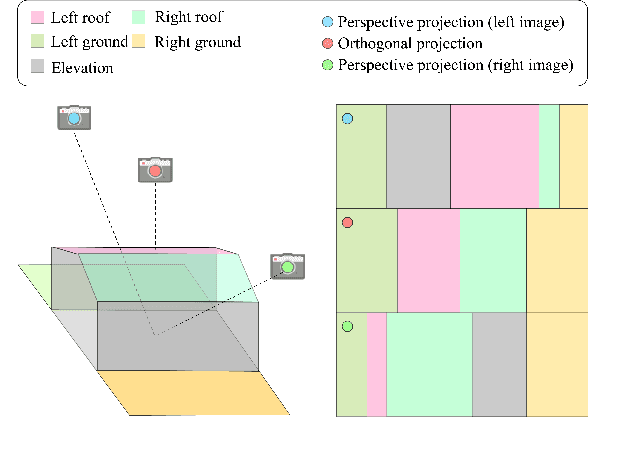

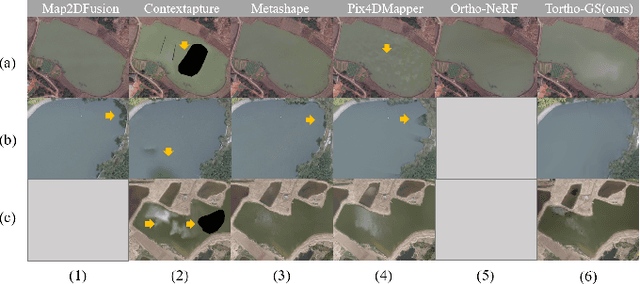

True Digital Orthophoto Maps (TDOMs) are essential products for digital twins and Geographic Information Systems (GIS). Traditionally, TDOM generation involves a complex set of traditional photogrammetric process, which may deteriorate due to various challenges, including inaccurate Digital Surface Model (DSM), degenerated occlusion detections, and visual artifacts in weak texture regions and reflective surfaces, etc. To address these challenges, we introduce TOrtho-Gaussian, a novel method inspired by 3D Gaussian Splatting (3DGS) that generates TDOMs through orthogonal splatting of optimized anisotropic Gaussian kernel. More specifically, we first simplify the orthophoto generation by orthographically splatting the Gaussian kernels onto 2D image planes, formulating a geometrically elegant solution that avoids the need for explicit DSM and occlusion detection. Second, to produce TDOM of large-scale area, a divide-and-conquer strategy is adopted to optimize memory usage and time efficiency of training and rendering for 3DGS. Lastly, we design a fully anisotropic Gaussian kernel that adapts to the varying characteristics of different regions, particularly improving the rendering quality of reflective surfaces and slender structures. Extensive experimental evaluations demonstrate that our method outperforms existing commercial software in several aspects, including the accuracy of building boundaries, the visual quality of low-texture regions and building facades. These results underscore the potential of our approach for large-scale urban scene reconstruction, offering a robust alternative for enhancing TDOM quality and scalability.
Grounded Graph Decoding Improves Compositional Generalization in Question Answering
Nov 05, 2021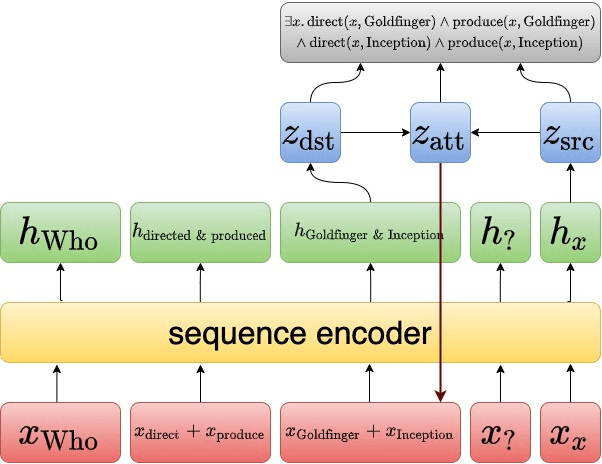
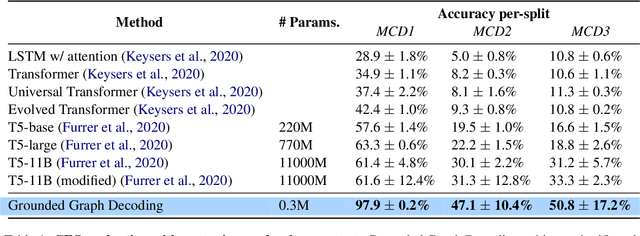
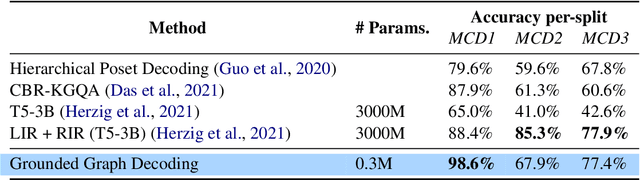
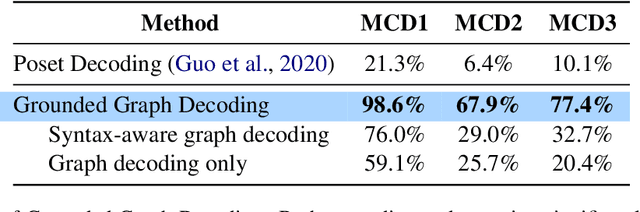
Question answering models struggle to generalize to novel compositions of training patterns, such to longer sequences or more complex test structures. Current end-to-end models learn a flat input embedding which can lose input syntax context. Prior approaches improve generalization by learning permutation invariant models, but these methods do not scale to more complex train-test splits. We propose Grounded Graph Decoding, a method to improve compositional generalization of language representations by grounding structured predictions with an attention mechanism. Grounding enables the model to retain syntax information from the input in thereby significantly improving generalization over complex inputs. By predicting a structured graph containing conjunctions of query clauses, we learn a group invariant representation without making assumptions on the target domain. Our model significantly outperforms state-of-the-art baselines on the Compositional Freebase Questions (CFQ) dataset, a challenging benchmark for compositional generalization in question answering. Moreover, we effectively solve the MCD1 split with 98% accuracy.