 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoring Noisy Demonstration for Imitation Learning With Diffusion Models
Oct 16, 2025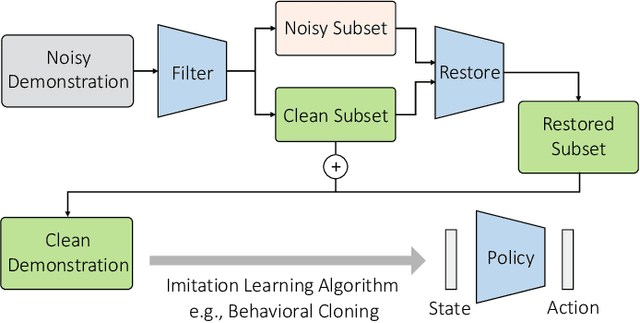
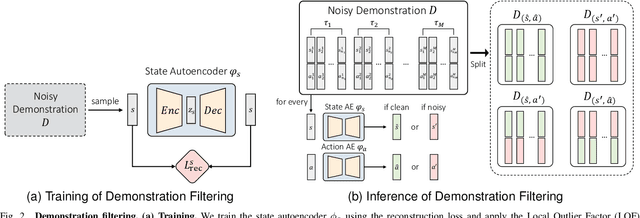
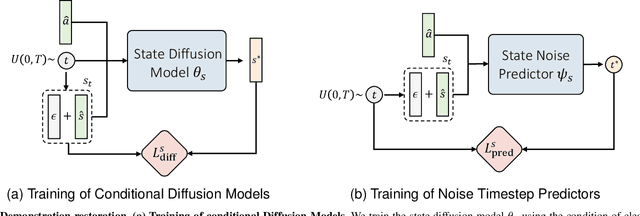
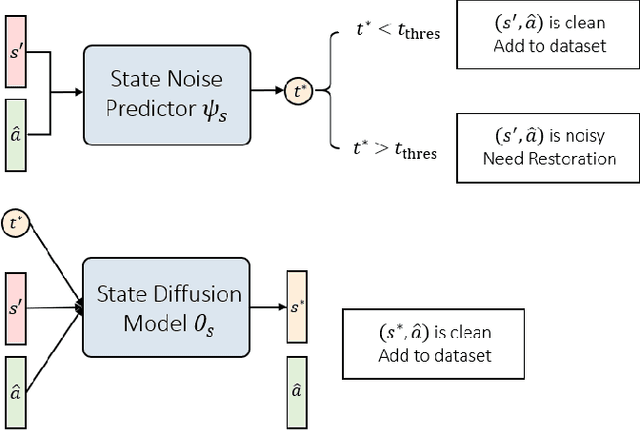
Imitation learning (IL) aims to learn a policy from expert demonstrations and has been applied to various applications. By learning from the expert policy, IL methods do not require environmental interactions or reward signals. However, most existing imitation learning algorithms assume perfect expert demonstrations, but expert demonstrations often contain imperfections caused by errors from human experts or sensor/control system inaccuracies. To address the above problems, this work proposes a filter-and-restore framework to best leverage expert demonstrations with inherent noise. Our proposed method first filters clean samples from the demonstrations and then learns conditional diffusion models to recover the noisy ones. We evaluate our proposed framework and existing methods in various domains, including robot arm manipulation, dexterous manipulation, and locomotion. The experiment results show that our proposed framework consistently outperforms existing methods across all the tasks. Ablation studies further validate the effectiveness of each component and demonstrate the framework's robustness to different noise types and levels. These results confirm the practical applicability of our framework to noisy offline demonstration data.
* Published in IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
Human-Feedback Efficient Reinforcement Learning for Online Diffusion Model Finetuning
Oct 07, 2024Controllable generation through Stable Diffusion (SD) fine-tuning aims to improve fidelity, safety, and alignment with human guidance. Existing reinforcement learning from human feedback methods usually rely on predefined heuristic reward functions or pretrained reward models built on large-scale datasets, limiting their applicability to scenarios where collecting such data is costly or difficult. To effectively and efficiently utilize human feedback, we develop a framework, HERO, which leverages online human feedback collected on the fly during model learning. Specifically, HERO features two key mechanisms: (1) Feedback-Aligned Representation Learning, an online training method that captures human feedback and provides informative learning signals for fine-tuning, and (2) Feedback-Guided Image Generation, which involves generating images from SD's refined initialization samples, enabling faster convergence towards the evaluator's intent. We demonstrate that HERO is 4x more efficient in online feedback for body part anomaly correction compared to the best existing method. Additionally, experiments show that HERO can effectively handle tasks like reasoning, counting, personalization, and reducing NSFW content with only 0.5K online feedback.
Diffusion Model-Augmented Behavioral Cloning
Feb 26, 2023Imitation learning addresses the challenge of learning by observing an expert's demonstrations without access to reward signals from the environment. Behavioral cloning (BC) formulates imitation learning as a supervised learning problem and learns from sampled state-action pairs. Despite its simplicity, it often fails to capture the temporal structure of the task and the global information of expert demonstrations. This work aims to augment BC by employing diffusion models for modeling expert behaviors, and designing a learning objective that leverages learned diffusion models to guide policy learning. To this end, we propose diffusion model-augmented behavioral cloning (Diffusion-BC) that combines our proposed diffusion model guided learning objective with the BC objective, which complements each other. Our proposed method outperforms baselines or achieves competitive performance in various continuous control domains, including navigation, robot arm manipulation, and locomotion. Ablation studies justify our design choices and investigate the effect of balancing the BC and our proposed diffusion model objective.
Learning Facial Liveness Representation for Domain Generalized Face Anti-spoofing
Aug 16, 2022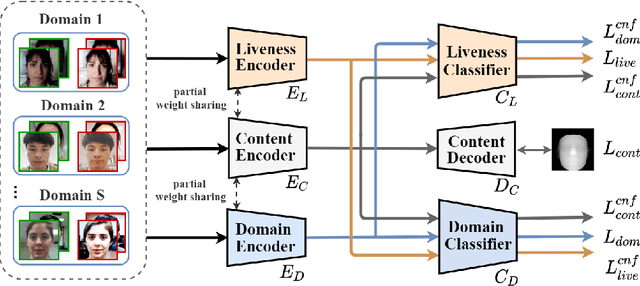
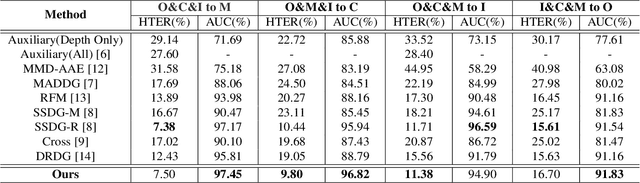
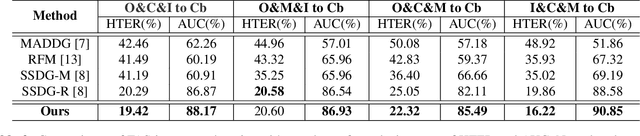
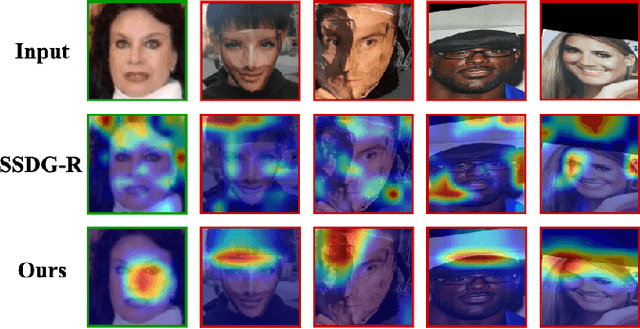
Face anti-spoofing (FAS) aims at distinguishing face spoof attacks from the authentic ones, which is typically approached by learning proper models for performing the associated classification task. In practice, one would expect such models to be generalized to FAS in different image domains. Moreover, it is not practical to assume that the type of spoof attacks would be known in advance. In this paper, we propose a deep learning model for addressing the aforementioned domain-generalized face anti-spoofing task. In particular, our proposed network is able to disentangle facial liveness representation from the irrelevant ones (i.e., facial content and image domain features). The resulting liveness representation exhibits sufficient domain invariant properties, and thus it can be applied for performing domain-generalized FAS. In our experiments, we conduct experiments on five benchmark datasets with various settings, and we verify that our model performs favorably against state-of-the-art approaches in identifying novel types of spoof attacks in unseen image domains.
Domain-Generalized Textured Surface Anomaly Detection
Mar 23, 2022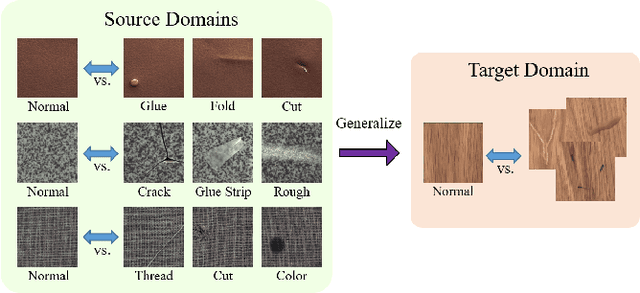
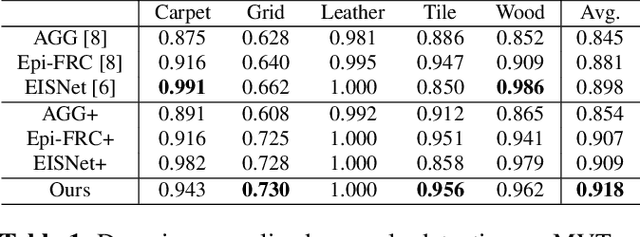
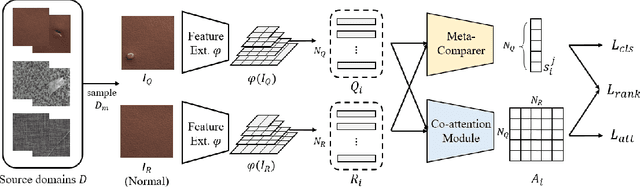
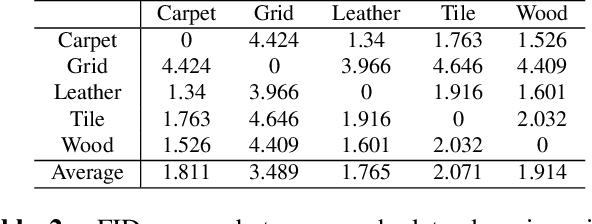
Anomaly detection aims to identify abnormal data that deviates from the normal ones, while typically requiring a sufficient amount of normal data to train the model for performing this task. Despite the success of recent anomaly detection methods, performing anomaly detection in an unseen domain remain a challenging task. In this paper, we address the task of domain-generalized textured surface anomaly detection. By observing normal and abnormal surface data across multiple source domains, our model is expected to be generalized to an unseen textured surface of interest, in which only a small number of normal data can be observed during testing. Although with only image-level labels observed in the training data, our patch-based meta-learning model exhibits promising generalization ability: not only can it generalize to unseen image domains, but it can also localize abnormal regions in the query image. Our experiments verify that our model performs favorably against state-of-the-art anomaly detection and domain generalization approaches in various settings.
Deep Representation Decomposition for Feature Disentanglement
Nov 02, 2020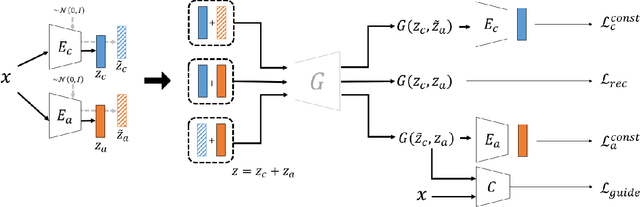
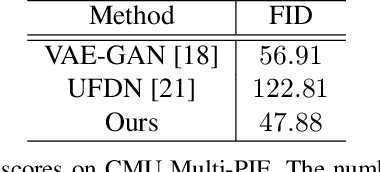


Representation disentanglement aims at learning interpretable features, so that the output can be recovered or manipulated accordingly. While existing works like infoGAN and AC-GAN exist, they choose to derive disjoint attribute code for feature disentanglement, which is not applicable for existing/trained generative models. In this paper, we propose a decomposition-GAN (dec-GAN), which is able to achieve the decomposition of an existing latent representation into content and attribute features. Guided by the classifier pre-trained on the attributes of interest, our dec-GAN decomposes the attributes of interest from the latent representation, while data recovery and feature consistency objectives enforce the learning of our proposed method. Our experiments on multiple image datasets confirm the effectiveness and robustness of our dec-GAN over recent representation disentanglement models.
Order-Free RNN with Visual Attention for Multi-Label Classification
Dec 20, 2017


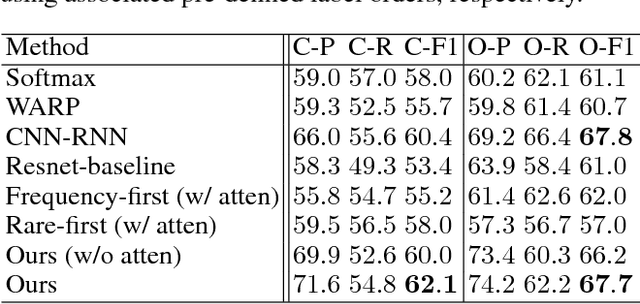
In this paper, we propose the joint learning attention and recurrent neural network (RNN) models for multi-label classification. While approaches based on the use of either model exist (e.g., for the task of image captioning), training such existing network architectures typically require pre-defined label sequences. For multi-label classification, it would be desirable to have a robust inference process, so that the prediction error would not propagate and thus affect the performance. Our proposed model uniquely integrates attention and Long Short Term Memory (LSTM) models, which not only addresses the above problem but also allows one to identify visual objects of interests with varying sizes without the prior knowledge of particular label ordering. More importantly, label co-occurrence information can be jointly exploited by our LSTM model. Finally, by advancing the technique of beam search, prediction of multiple labels can be efficiently achieved by our proposed network model.