 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Efficient-tuning Methods in Self-supervised Speech Models
Oct 10, 2022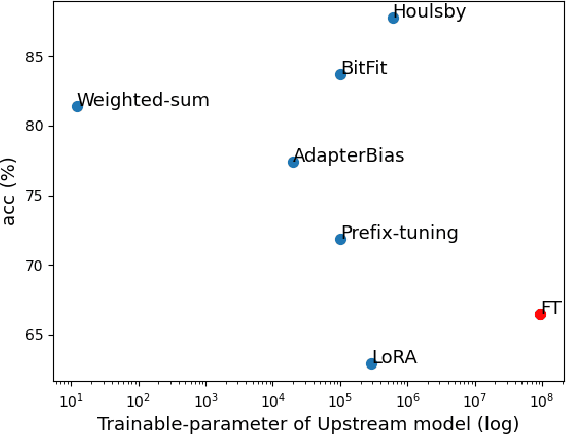
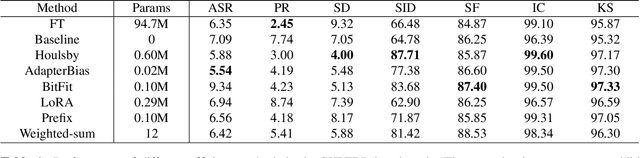
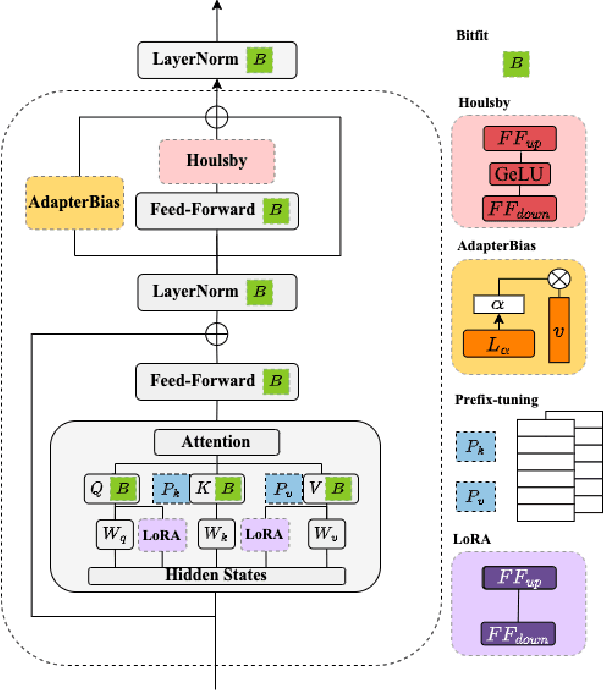
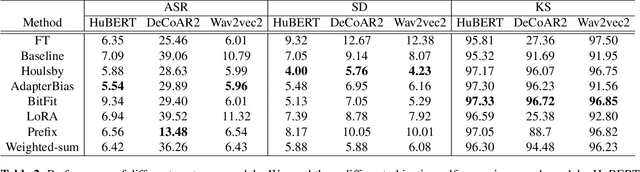
In this study, we aim to explore efficient tuning methods for speech self-supervised learning. Recent studies show that self-supervised learning (SSL) can learn powerful representations for different speech tasks. However, fine-tuning pre-trained models for each downstream task is parameter-inefficient since SSL models are notoriously large with millions of parameters. Adapters are lightweight modules commonly used in NLP to solve this problem. In downstream tasks, the parameters of SSL models are frozen, and only the adapters are trained. Given the lack of studies generally exploring the effectiveness of adapters for self-supervised speech tasks, we intend to fill this gap by adding various adapter modules in pre-trained speech SSL models. We show that the performance parity can be achieved with over 90% parameter reduction, and discussed the pros and cons of efficient tuning techniques. This is the first comprehensive investigation of various adapter types across speech tasks.
Learning Facial Liveness Representation for Domain Generalized Face Anti-spoofing
Aug 16, 2022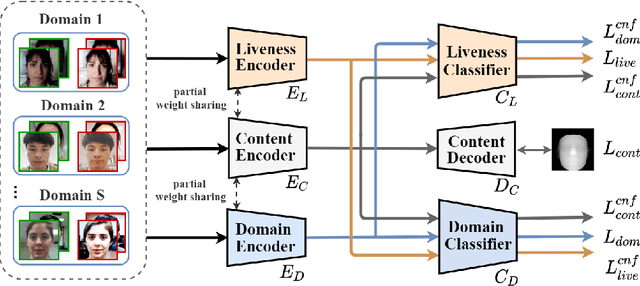
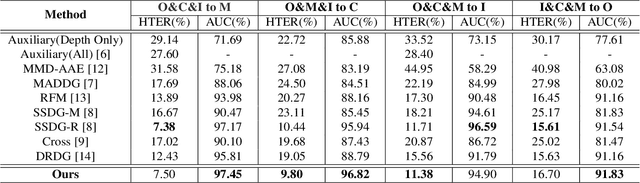
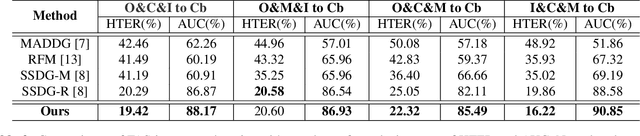
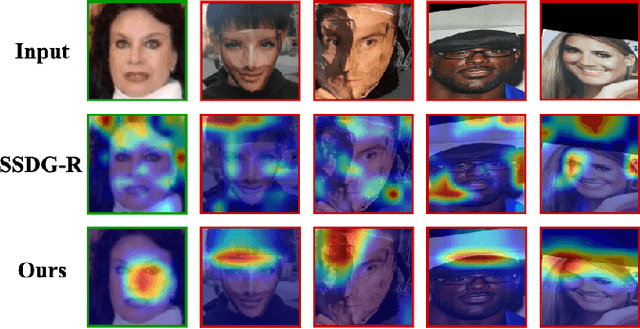
Face anti-spoofing (FAS) aims at distinguishing face spoof attacks from the authentic ones, which is typically approached by learning proper models for performing the associated classification task. In practice, one would expect such models to be generalized to FAS in different image domains. Moreover, it is not practical to assume that the type of spoof attacks would be known in advance. In this paper, we propose a deep learning model for addressing the aforementioned domain-generalized face anti-spoofing task. In particular, our proposed network is able to disentangle facial liveness representation from the irrelevant ones (i.e., facial content and image domain features). The resulting liveness representation exhibits sufficient domain invariant properties, and thus it can be applied for performing domain-generalized FAS. In our experiments, we conduct experiments on five benchmark datasets with various settings, and we verify that our model performs favorably against state-of-the-art approaches in identifying novel types of spoof attacks in unseen image domains.
AdapterBias: Parameter-efficient Token-dependent Representation Shift for Adapters in NLP Tasks
Apr 30, 2022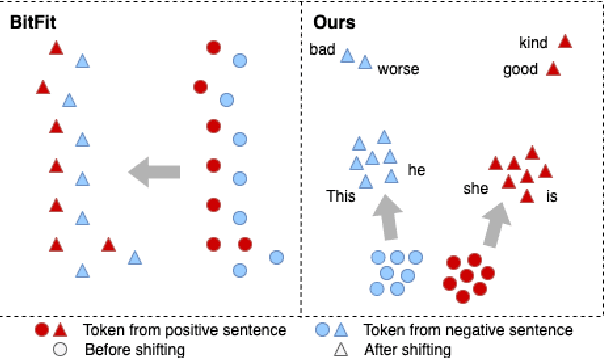
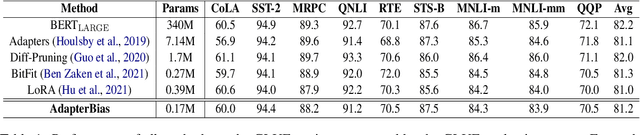
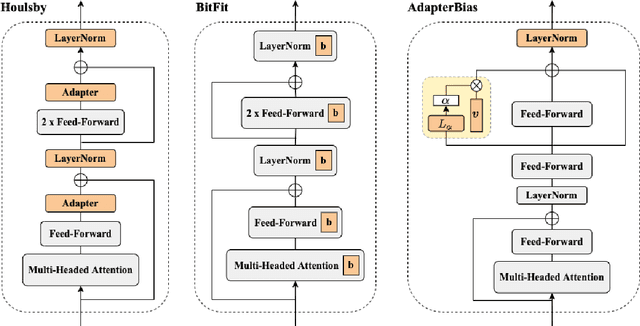
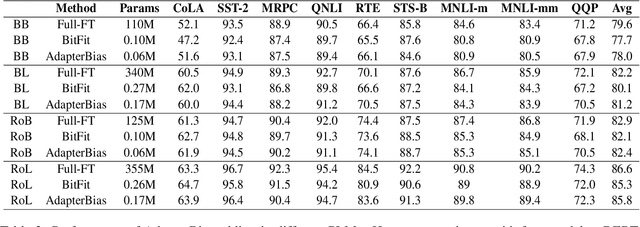
Transformer-based pre-trained models with millions of parameters require large storage. Recent approaches tackle this shortcoming by training adapters, but these approaches still require a relatively large number of parameters. In this study, AdapterBias, a surprisingly simple yet effective adapter architecture, is proposed. AdapterBias adds a token-dependent shift to the hidden output of transformer layers to adapt to downstream tasks with only a vector and a linear layer. Extensive experiments are conducted to demonstrate the effectiveness of AdapterBias. The experiments show that our proposed method can dramatically reduce the trainable parameters compared to the previous works with a minimal decrease in task performances compared with fine-tuned pre-trained models. We further find that AdapterBias automatically learns to assign more significant representation shifts to the tokens related to the task in consideration.