 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN Vocoder: Multi-Resolution Discriminator Is All You Need
Mar 09, 2021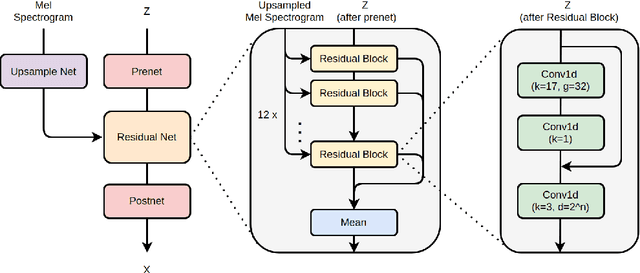
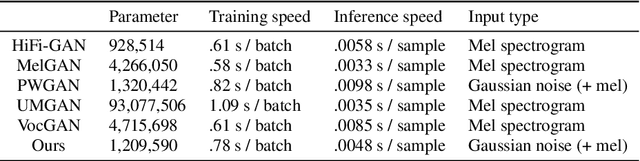
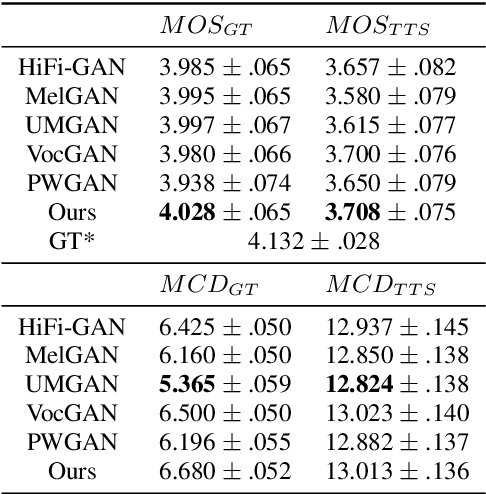
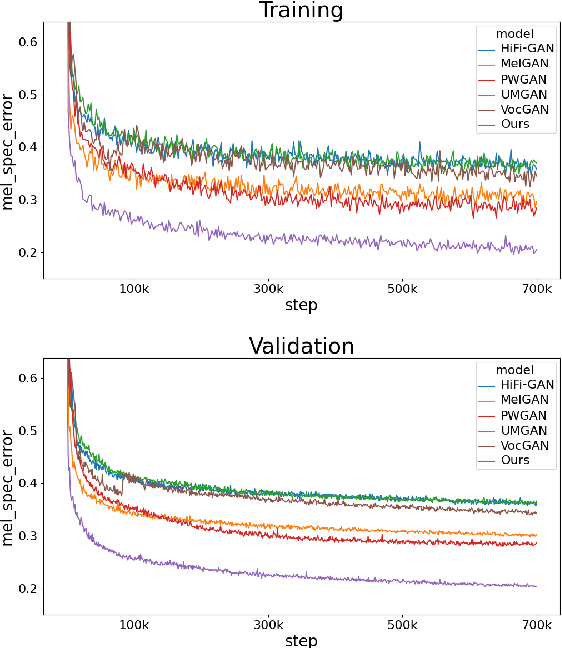
Several of the latest GAN-based vocoders show remarkable achievements, outperforming autoregressive and flow-based competitors in both qualitative and quantitative measures while synthesizing orders of magnitude faster. In this work, we hypothesize that the common factor underlying their success is the multi-resolution discriminating framework, not the minute details in architecture, loss function, or training strategy. We experimentally test the hypothesis by evaluating six different generators paired with one shared multi-resolution discriminating framework. For all evaluative measures with respect to text-to-speech syntheses and for all perceptual metrics, their performances are not distinguishable from one another, which supports our hypothesis.
Axial Residual Networks for CycleGAN-based Voice Conversion
Mar 08, 2021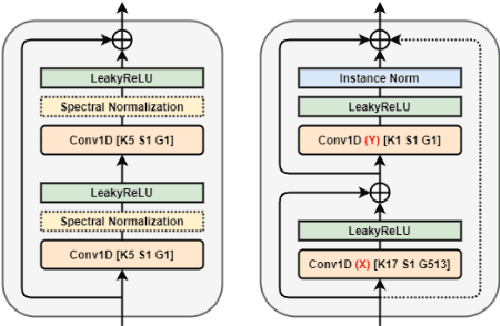
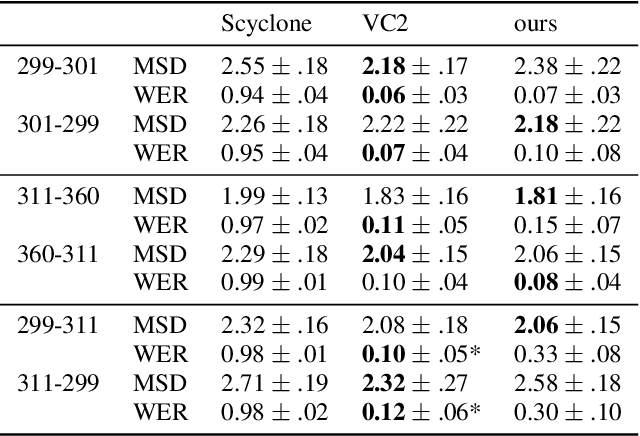
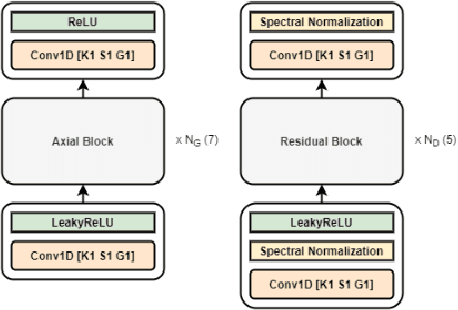
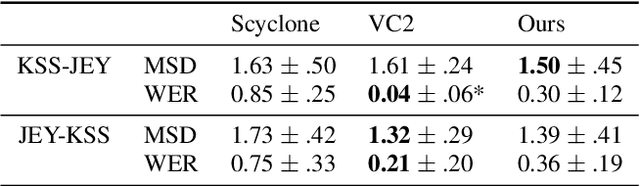
We propose a novel architecture and improved training objectives for non-parallel voice conversion. Our proposed CycleGAN-based model performs a shape-preserving transformation directly on a high frequency-resolution magnitude spectrogram, converting its style (i.e. speaker identity) while preserving the speech content. Throughout the entire conversion process, the model does not resort to compressed intermediate representations of any sort (e.g. mel spectrogram, low resolution spectrogram, decomposed network feature). We propose an efficient axial residual block architecture to support this expensive procedure and various modifications to the CycleGAN losses to stabilize the training process. We demonstrate via experiments that our proposed model outperforms Scyclone and shows a comparable or better performance to that of CycleGAN-VC2 even without employing a neural vocoder.