 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Path Compression: Compressing Generation Trajectories for Efficient LLM Reasoning
May 20, 2025

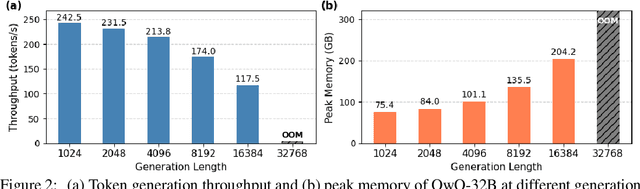
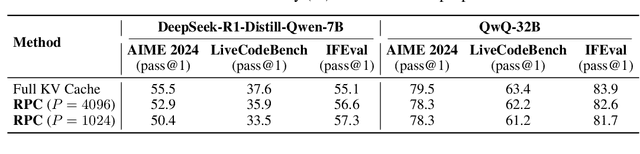
Recent reasoning-focused language models achieve high accuracy by generating lengthy intermediate reasoning paths before producing final answers. While this approach is effective in solving problems that require logical thinking, long reasoning paths significantly increase memory usage and throughput of token generation, limiting the practical deployment of such models. We propose Reasoning Path Compression (RPC), a training-free method that accelerates inference by leveraging the semantic sparsity of reasoning paths. RPC periodically compresses the KV cache by retaining KV cache that receive high importance score, which are computed using a selector window composed of recently generated queries. Experiments show that RPC improves generation throughput of QwQ-32B by up to 1.60$\times$ compared to the inference with full KV cache, with an accuracy drop of 1.2% on the AIME 2024 benchmark. Our findings demonstrate that semantic sparsity in reasoning traces can be effectively exploited for compression, offering a practical path toward efficient deployment of reasoning LLMs. Our code is available at https://github.com/jiwonsong-dev/ReasoningPathCompression.
Column-wise Quantization of Weights and Partial Sums for Accurate and Efficient Compute-In-Memory Accelerators
Feb 11, 2025



Compute-in-memory (CIM) is an efficient method for implementing deep neural networks (DNNs) but suffers from substantial overhead from analog-to-digital converters (ADCs), especially as ADC precision increases. Low-precision ADCs can re- duce this overhead but introduce partial-sum quantization errors degrading accuracy. Additionally, low-bit weight constraints, im- posed by cell limitations and the need for multiple cells for higher- bit weights, present further challenges. While fine-grained partial- sum quantization has been studied to lower ADC resolution effectively, weight granularity, which limits overall partial-sum quantized accuracy, remains underexplored. This work addresses these challenges by aligning weight and partial-sum quantization granularities at the column-wise level. Our method improves accuracy while maintaining dequantization overhead, simplifies training by removing two-stage processes, and ensures robustness to memory cell variations via independent column-wise scale factors. We also propose an open-source CIM-oriented convolution framework to handle fine-grained weights and partial-sums effi- ciently, incorporating a novel tiling method and group convolution. Experimental results on ResNet-20 (CIFAR-10, CIFAR-100) and ResNet-18 (ImageNet) show accuracy improvements of 0.99%, 2.69%, and 1.01%, respectively, compared to the best-performing related works. Additionally, variation analysis reveals the robust- ness of our method against memory cell variations. These findings highlight the effectiveness of our quantization scheme in enhancing accuracy and robustness while maintaining hardware efficiency in CIM-based DNN implementations. Our code is available at https://github.com/jiyoonkm/ColumnQuant.
FastKV: KV Cache Compression for Fast Long-Context Processing with Token-Selective Propagation
Feb 03, 2025While large language models (LLMs) excel at handling long-context sequences, they require substantial key-value (KV) caches to store contextual information, which can heavily burden computational efficiency and memory usage. Previous efforts to compress these KV caches primarily focused on reducing memory demands but were limited in enhancing latency. To address this issue, we introduce FastKV, a KV cache compression method designed to enhance latency for long-context sequences. To enhance processing speeds while maintaining accuracy, FastKV adopts a novel Token-Selective Propagation (TSP) approach that retains the full context information in the initial layers of LLMs and selectively propagates only a portion of this information in deeper layers even in the prefill stage. Additionally, FastKV incorporates grouped-query attention (GQA)-aware KV cache compression to exploit the advantages of GQA in both memory and computational efficiency. Our experimental results show that FastKV achieves 2.00$\times$ and 1.40$\times$ improvements in time-to-first-token (TTFT) and throughput, respectively, compared to HeadKV, the state-of-the-art KV cache compression method. Moreover, FastKV successfully maintains accuracy on long-context benchmarks at levels comparable to the baselines. Our code is available at https://github.com/dongwonjo/FastKV.
Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models
Jun 18, 2024



Binarization, which converts weight parameters to binary values, has emerged as an effective strategy to reduce the size of large language models (LLMs). However, typical binarization techniques significantly diminish linguistic effectiveness of LLMs. To address this issue, we introduce a novel binarization technique called Mixture of Scales (BinaryMoS). Unlike conventional methods, BinaryMoS employs multiple scaling experts for binary weights, dynamically merging these experts for each token to adaptively generate scaling factors. This token-adaptive approach boosts the representational power of binarized LLMs by enabling contextual adjustments to the values of binary weights. Moreover, because this adaptive process only involves the scaling factors rather than the entire weight matrix, BinaryMoS maintains compression efficiency similar to traditional static binarization methods. Our experimental results reveal that BinaryMoS surpasses conventional binarization techniques in various natural language processing tasks and even outperforms 2-bit quantization methods, all while maintaining similar model size to static binarization techniques.
L4Q: Parameter Efficient Quantization-Aware Training on Large Language Models via LoRA-wise LSQ
Feb 15, 2024



Post-training quantization (PTQ) and quantization-aware training (QAT) methods are gaining popularity in mitigating the high memory and computational costs associated with Large Language Models (LLMs). In resource-constrained scenarios, PTQ, with its reduced training overhead, is often preferred over QAT, despite the latter's potential for higher accuracy. Meanwhile, parameter-efficient fine-tuning (PEFT) methods like low-rank adaptation (LoRA) have been introduced, and recent efforts have explored quantization-aware PEFT techniques. However, these approaches may lack generality due to their reliance on the pre-quantized model's configuration. Their effectiveness may be compromised by non-linearly quantized or mixed-precision weights, and the retraining of specific quantization parameters might impede optimal performance. To address these challenges, we propose L4Q, an algorithm for parameter-efficient quantization-aware training. L4Q leverages LoRA-wise learned quantization step size for LLMs, aiming to enhance generality. The simultaneous quantization-and-fine-tuning process of L4Q is applicable to high-precision models, yielding linearly quantized weights with superior accuracy. Our experiments, conducted on the LLaMA and LLaMA2 model families using an instructional dataset, showcase L4Q's capabilities in language comprehension and few-shot in-context learning, achieving sub-4-bit precision while maintaining comparable training times to applying PEFT on a quantized model.
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Feb 14, 2024
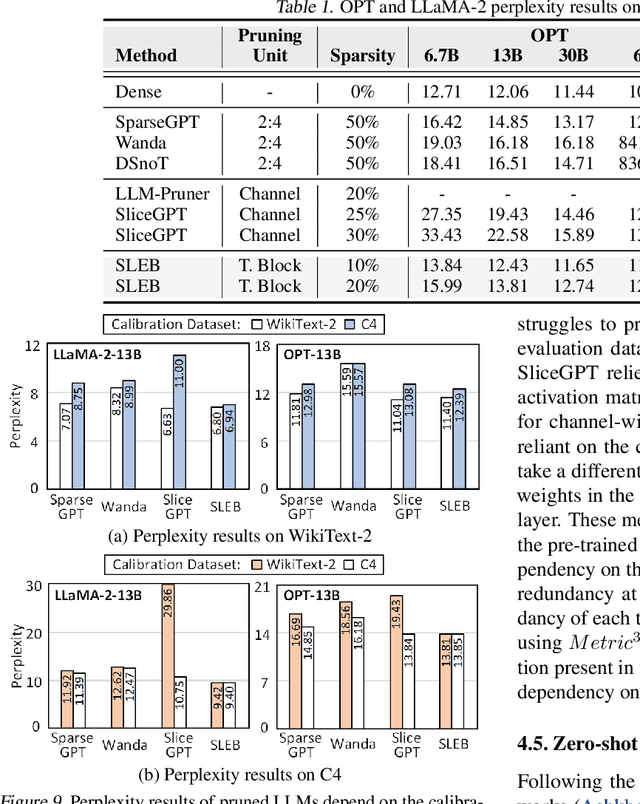
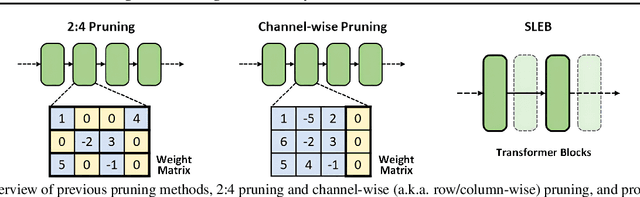
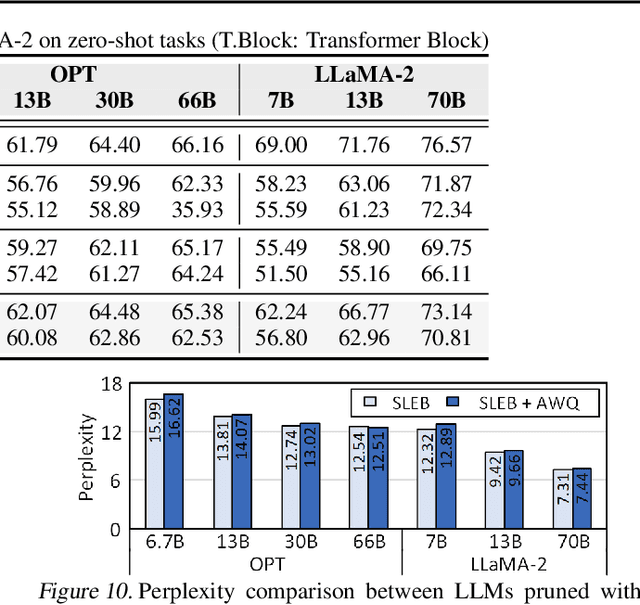
Large language models (LLMs) have proven to be highly effective across various natural language processing tasks. However, their large number of parameters poses significant challenges for practical deployment. Pruning, a technique aimed at reducing the size and complexity of LLMs, offers a potential solution by removing redundant components from the network. Despite the promise of pruning, existing methods often struggle to achieve substantial end-to-end LLM inference speedup. In this paper, we introduce SLEB, a novel approach designed to streamline LLMs by eliminating redundant transformer blocks. We choose the transformer block as the fundamental unit for pruning, because LLMs exhibit block-level redundancy with high similarity between the outputs of neighboring blocks. This choice allows us to effectively enhance the processing speed of LLMs. Our experimental results demonstrate that SLEB successfully accelerates LLM inference without compromising the linguistic capabilities of these models, making it a promising technique for optimizing the efficiency of LLMs. The code is available at: https://github.com/leapingjagg-dev/SLEB
Squeezing Large-Scale Diffusion Models for Mobile
Jul 03, 2023The emergence of diffusion models has greatly broadened the scope of high-fidelity image synthesis, resulting in notable advancements in both practical implementation and academic research. With the active adoption of the model in various real-world applications, the need for on-device deployment has grown considerably. However, deploying large diffusion models such as Stable Diffusion with more than one billion parameters to mobile devices poses distinctive challenges due to the limited computational and memory resources, which may vary according to the device. In this paper, we present the challenges and solutions for deploying Stable Diffusion on mobile devices with TensorFlow Lite framework, which supports both iOS and Android devices. The resulting Mobile Stable Diffusion achieves the inference latency of smaller than 7 seconds for a 512x512 image generation on Android devices with mobile GPUs.
BitSplit-Net: Multi-bit Deep Neural Network with Bitwise Activation Function
Mar 23, 2019

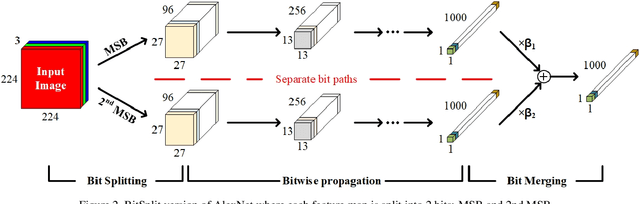
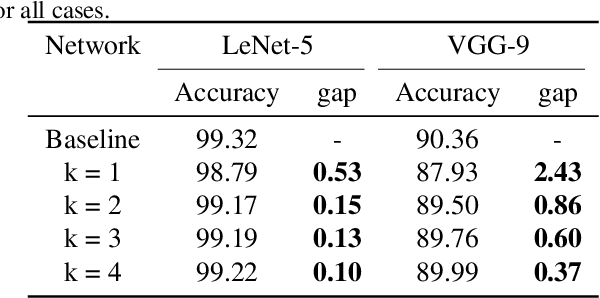
Significant computational cost and memory requirements for deep neural networks (DNNs) make it difficult to utilize DNNs in resource-constrained environments. Binary neural network (BNN), which uses binary weights and binary activations, has been gaining interests for its hardware-friendly characteristics and minimal resource requirement. However, BNN usually suffers from accuracy degradation. In this paper, we introduce "BitSplit-Net", a neural network which maintains the hardware-friendly characteristics of BNN while improving accuracy by using multi-bit precision. In BitSplit-Net, each bit of multi-bit activations propagates independently throughout the network before being merged at the end of the network. Thus, each bit path of the BitSplit-Net resembles BNN and hardware friendly features of BNN, such as bitwise binary activation function, are preserved in our scheme. We demonstrate that the BitSplit version of LeNet-5, VGG-9, AlexNet, and ResNet-18 can be trained to have similar classification accuracy at a lower computational cost compared to conventional multi-bit networks with low bit precision (<= 4-bit). We further evaluate BitSplit-Net on GPU with custom CUDA kernel, showing that BitSplit-Net can achieve better hardware performance in comparison to conventional multi-bit networks.
Neural Network-Hardware Co-design for Scalable RRAM-based BNN Accelerators
Nov 06, 2018



Recently, RRAM-based Binary Neural Network (BNN) hardware has been gaining interests as it requires 1-bit sense-amp only and eliminates the need for high-resolution ADC and DAC. However, RRAM-based BNN hardware still requires high-resolution ADC for partial sum calculation to implement large-scale neural network using multiple memory arrays. We propose a neural network-hardware co-design approach to split input to fit each split network on a RRAM array so that the reconstructed BNNs calculate 1-bit output neuron in each array. As a result, ADC can be completely eliminated from the design even for large-scale neural network. Simulation results show that the proposed network reconstruction and retraining recovers the inference accuracy of the original BNN. The accuracy loss of the proposed scheme in the CIFAR-10 testcase was less than 1.1% compared to the original network.