 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation-Aligned Key Channel Pruning for Efficient Vision-Language Model Inference
May 19, 2026Vision-Language Models suffer severe KV cache pressure at inference, as a single image often encodes into thousands of tokens. Most existing methods exploit token sparsity through token pruning, but permanently discarding visual content causes substantial degradation on fine-grained perception tasks. This motivates a complementary axis, feature sparsity: under a fixed KV cache budget, compressing the channel dimension preserves more visual tokens at the same memory cost. Prior Key channel pruning methods, however, face a structural trade-off: token-wise channel pruning is expressive but unstructured and slow, while head-wise approach is hardware-friendly but less robust. We resolve this with RotateK, a rotation-based structured Key channel pruning framework. RotateK applies an online PCA-based rotation that aligns token-dependent channel importance into a shared low-dimensional subspace, enabling accurate pruning under lightweight head-wise masks; a fused Triton attention kernel operates directly on sparse-channel Keys for efficient decoding. Experiments on two representative VLM backbones show that RotateK consistently outperforms prior Key channel pruning in both accuracy and decoding latency, while joint token-channel pruning improves over token-only baselines at matched KV cache budgets.
RelayGen: Intra-Generation Model Switching for Efficient Reasoning
Feb 06, 2026Large reasoning models (LRMs) achieve strong performance on complex reasoning tasks by generating long, multi-step reasoning trajectories, but inference-time scaling incurs substantial deployment cost. A key challenge is that generation difficulty varies within a single output, whereas existing efficiency-oriented approaches either ignore this intra-generation variation or rely on supervised token-level routing with high system complexity. We present \textbf{RelayGen}, a training-free, segment-level runtime model switching framework that exploits difficulty variation in long-form reasoning. Through offline analysis of generation uncertainty using token probability margins, we show that coarse-grained segment-level control is sufficient to capture difficulty transitions within a reasoning trajectory. RelayGen identifies model-specific switch cues that signal transitions to lower-difficulty segments and dynamically delegates their continuation to a smaller model, while preserving high-difficulty reasoning on the large model. Across multiple reasoning benchmarks, RelayGen substantially reduces inference latency while preserving most of the accuracy of large models. When combined with speculative decoding, RelayGen achieves up to 2.2$\times$ end-to-end speedup with less than 2\% accuracy degradation, without requiring additional training or learned routing components.
Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
Feb 03, 2026The quadratic complexity of attention remains the central bottleneck in long-context inference for large language models. Prior acceleration methods either sparsify the attention map with structured patterns or permanently evict tokens at specific layers, which can retain irrelevant tokens or rely on irreversible early decisions despite the layer-/head-wise dynamics of token importance. In this paper, we propose Token Sparse Attention, a lightweight and dynamic token-level sparsification mechanism that compresses per-head $Q$, $K$, $V$ to a reduced token set during attention and then decompresses the output back to the original sequence, enabling token information to be reconsidered in subsequent layers. Furthermore, Token Sparse Attention exposes a new design point at the intersection of token selection and sparse attention. Our approach is fully compatible with dense attention implementations, including Flash Attention, and can be seamlessly composed with existing sparse attention kernels. Experimental results show that Token Sparse Attention consistently improves accuracy-latency trade-off, achieving up to $\times$3.23 attention speedup at 128K context with less than 1% accuracy degradation. These results demonstrate that dynamic and interleaved token-level sparsification is a complementary and effective strategy for scalable long-context inference.
LiteStage: Latency-aware Layer Skipping for Multi-stage Reasoning
Oct 16, 2025Multi-stage reasoning has emerged as an effective strategy for enhancing the reasoning capability of small language models by decomposing complex problems into sequential sub-stages. However, this comes at the cost of increased latency. We observe that existing adaptive acceleration techniques, such as layer skipping, struggle to balance efficiency and accuracy in this setting due to two key challenges: (1) stage-wise variation in skip sensitivity, and (2) the generation of redundant output tokens. To address these, we propose LiteStage, a latency-aware layer skipping framework for multi-stage reasoning. LiteStage combines a stage-wise offline search that allocates optimal layer budgets with an online confidence-based generation early exit to suppress unnecessary decoding. Experiments on three benchmarks, e.g., OBQA, CSQA, and StrategyQA, show that LiteStage achieves up to 1.70x speedup with less than 4.0% accuracy loss, outperforming prior training-free layer skipping methods.
Reasoning Path Compression: Compressing Generation Trajectories for Efficient LLM Reasoning
May 20, 2025

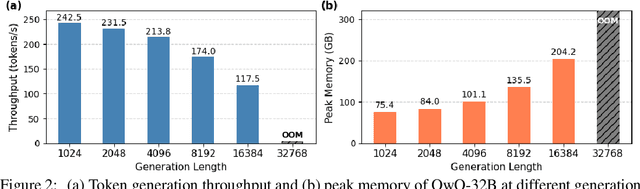
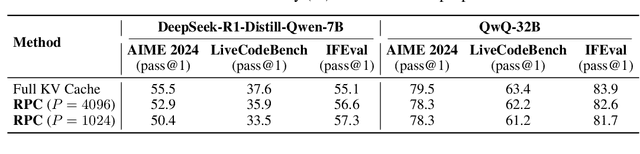
Recent reasoning-focused language models achieve high accuracy by generating lengthy intermediate reasoning paths before producing final answers. While this approach is effective in solving problems that require logical thinking, long reasoning paths significantly increase memory usage and throughput of token generation, limiting the practical deployment of such models. We propose Reasoning Path Compression (RPC), a training-free method that accelerates inference by leveraging the semantic sparsity of reasoning paths. RPC periodically compresses the KV cache by retaining KV cache that receive high importance score, which are computed using a selector window composed of recently generated queries. Experiments show that RPC improves generation throughput of QwQ-32B by up to 1.60$\times$ compared to the inference with full KV cache, with an accuracy drop of 1.2% on the AIME 2024 benchmark. Our findings demonstrate that semantic sparsity in reasoning traces can be effectively exploited for compression, offering a practical path toward efficient deployment of reasoning LLMs. Our code is available at https://github.com/jiwonsong-dev/ReasoningPathCompression.
FastKV: KV Cache Compression for Fast Long-Context Processing with Token-Selective Propagation
Feb 03, 2025While large language models (LLMs) excel at handling long-context sequences, they require substantial key-value (KV) caches to store contextual information, which can heavily burden computational efficiency and memory usage. Previous efforts to compress these KV caches primarily focused on reducing memory demands but were limited in enhancing latency. To address this issue, we introduce FastKV, a KV cache compression method designed to enhance latency for long-context sequences. To enhance processing speeds while maintaining accuracy, FastKV adopts a novel Token-Selective Propagation (TSP) approach that retains the full context information in the initial layers of LLMs and selectively propagates only a portion of this information in deeper layers even in the prefill stage. Additionally, FastKV incorporates grouped-query attention (GQA)-aware KV cache compression to exploit the advantages of GQA in both memory and computational efficiency. Our experimental results show that FastKV achieves 2.00$\times$ and 1.40$\times$ improvements in time-to-first-token (TTFT) and throughput, respectively, compared to HeadKV, the state-of-the-art KV cache compression method. Moreover, FastKV successfully maintains accuracy on long-context benchmarks at levels comparable to the baselines. Our code is available at https://github.com/dongwonjo/FastKV.
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Feb 14, 2024
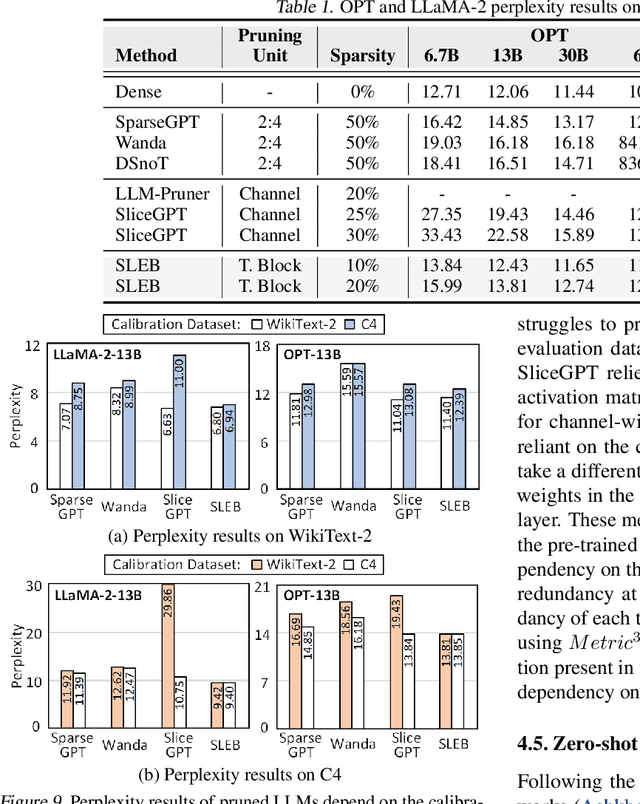
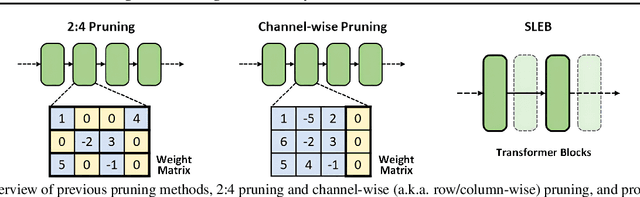
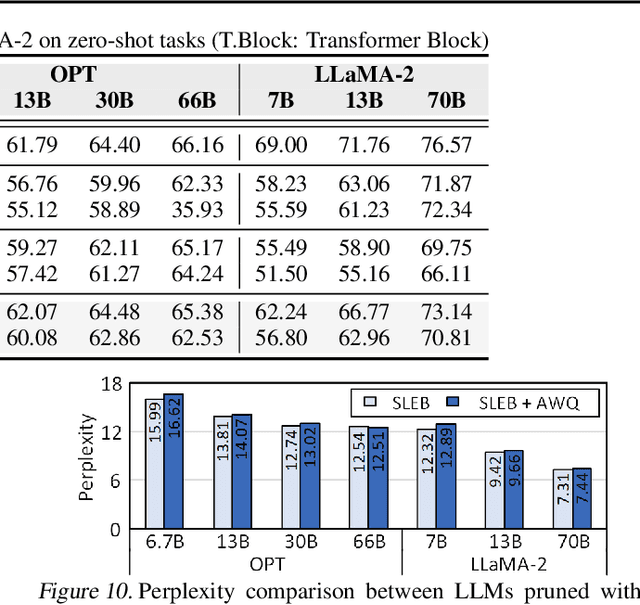
Large language models (LLMs) have proven to be highly effective across various natural language processing tasks. However, their large number of parameters poses significant challenges for practical deployment. Pruning, a technique aimed at reducing the size and complexity of LLMs, offers a potential solution by removing redundant components from the network. Despite the promise of pruning, existing methods often struggle to achieve substantial end-to-end LLM inference speedup. In this paper, we introduce SLEB, a novel approach designed to streamline LLMs by eliminating redundant transformer blocks. We choose the transformer block as the fundamental unit for pruning, because LLMs exhibit block-level redundancy with high similarity between the outputs of neighboring blocks. This choice allows us to effectively enhance the processing speed of LLMs. Our experimental results demonstrate that SLEB successfully accelerates LLM inference without compromising the linguistic capabilities of these models, making it a promising technique for optimizing the efficiency of LLMs. The code is available at: https://github.com/leapingjagg-dev/SLEB