 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Compression for IMC Arrays
Feb 10, 2025



In this study, we address the challenge of low-rank model compression in the context of in-memory computing (IMC) architectures. Traditional pruning approaches, while effective in model size reduction, necessitate additional peripheral circuitry to manage complex dataflows and mitigate dislocation issues, leading to increased area and energy overheads. To circumvent these drawbacks, we propose leveraging low-rank compression techniques, which, unlike pruning, streamline the dataflow and seamlessly integrate with IMC architectures. However, low-rank compression presents its own set of challenges, namely i) suboptimal IMC array utilization and ii) compromised accuracy. To address these issues, we introduce a novel approach i) employing shift and duplicate kernel (SDK) mapping technique, which exploits idle IMC columns for parallel processing, and ii) group low-rank convolution, which mitigates the information imbalance in the decomposed matrices. Our experimental results demonstrate that our proposed method achieves up to 2.5x speedup or +20.9% accuracy boost over existing pruning techniques.
VW-SDK: Efficient Convolutional Weight Mapping Using Variable Windows for Processing-In-Memory Architectures
Dec 21, 2021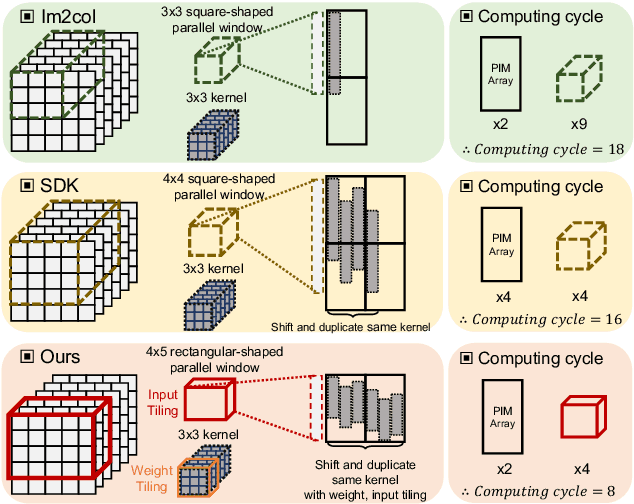
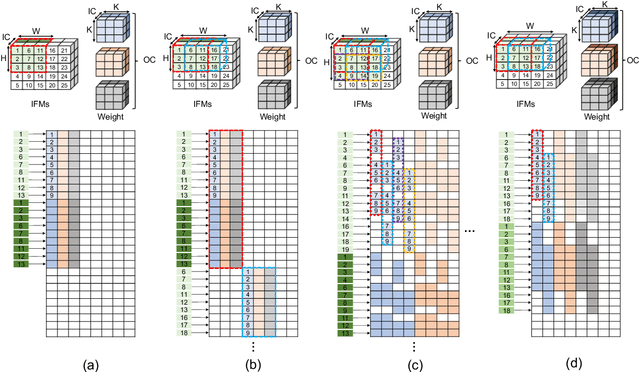
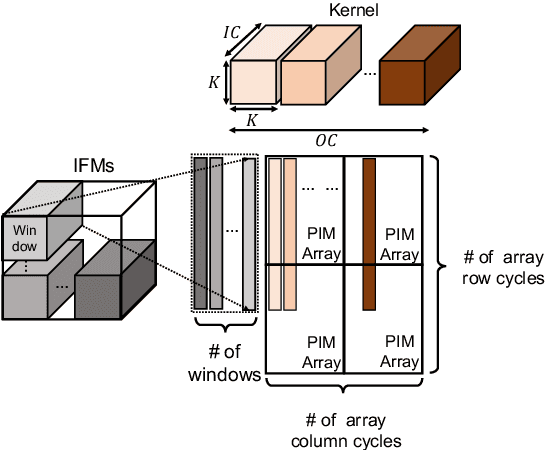
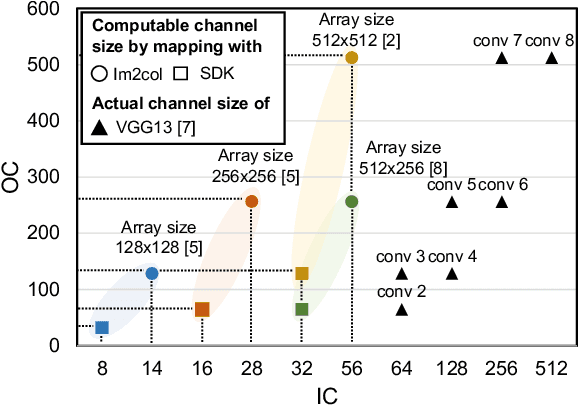
With their high energy efficiency, processing-in-memory (PIM) arrays are increasingly used for convolutional neural network (CNN) inference. In PIM-based CNN inference, the computational latency and energy are dependent on how the CNN weights are mapped to the PIM array. A recent study proposed shifted and duplicated kernel (SDK) mapping that reuses the input feature maps with a unit of a parallel window, which is convolved with duplicated kernels to obtain multiple output elements in parallel. However, the existing SDK-based mapping algorithm does not always result in the minimum computing cycles because it only maps a square-shaped parallel window with the entire channels. In this paper, we introduce a novel mapping algorithm called variable-window SDK (VW-SDK), which adaptively determines the shape of the parallel window that leads to the minimum computing cycles for a given convolutional layer and PIM array. By allowing rectangular-shaped windows with partial channels, VW-SDK utilizes the PIM array more efficiently, thereby further reduces the number of computing cycles. The simulation with a 512x512 PIM array and Resnet-18 shows that VW-SDK improves the inference speed by 1.69x compared to the existing SDK-based algorithm.