 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncQuant: Truncation-Ready Quantization for DNNs with Flexible Weight Bit Precision
Jun 13, 2025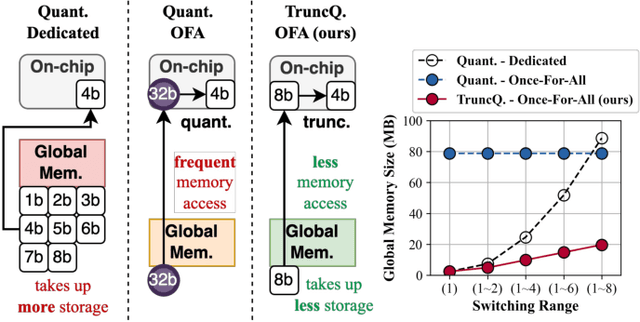
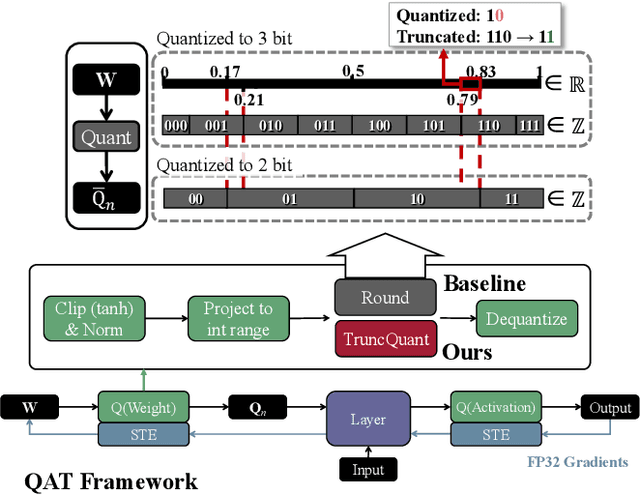
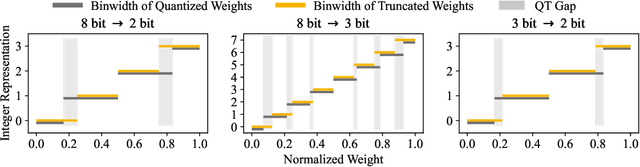
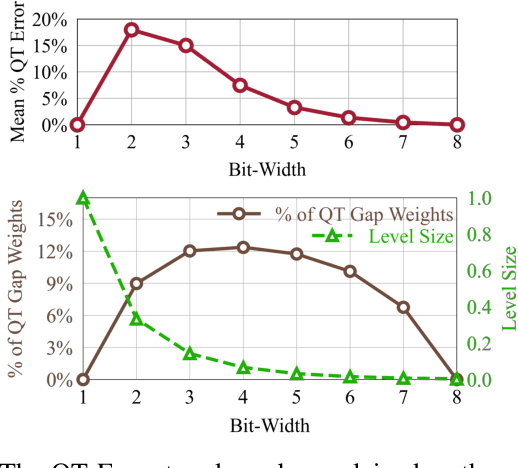
The deployment of deep neural networks on edge devices is a challenging task due to the increasing complexity of state-of-the-art models, requiring efforts to reduce model size and inference latency. Recent studies explore models operating at diverse quantization settings to find the optimal point that balances computational efficiency and accuracy. Truncation, an effective approach for achieving lower bit precision mapping, enables a single model to adapt to various hardware platforms with little to no cost. However, formulating a training scheme for deep neural networks to withstand the associated errors introduced by truncation remains a challenge, as the current quantization-aware training schemes are not designed for the truncation process. We propose TruncQuant, a novel truncation-ready training scheme allowing flexible bit precision through bit-shifting in runtime. We achieve this by aligning TruncQuant with the output of the truncation process, demonstrating strong robustness across bit-width settings, and offering an easily implementable training scheme within existing quantization-aware frameworks. Our code is released at https://github.com/a2jinhee/TruncQuant.
Deep Q-Learning with Gradient Target Tracking
Mar 20, 2025This paper introduces Q-learning with gradient target tracking, a novel reinforcement learning framework that provides a learned continuous target update mechanism as an alternative to the conventional hard update paradigm. In the standard deep Q-network (DQN), the target network is a copy of the online network's weights, held fixed for a number of iterations before being periodically replaced via a hard update. While this stabilizes training by providing consistent targets, it introduces a new challenge: the hard update period must be carefully tuned to achieve optimal performance. To address this issue, we propose two gradient-based target update methods: DQN with asymmetric gradient target tracking (AGT2-DQN) and DQN with symmetric gradient target tracking (SGT2-DQN). These methods replace the conventional hard target updates with continuous and structured updates using gradient descent, which effectively eliminates the need for manual tuning. We provide a theoretical analysis proving the convergence of these methods in tabular settings. Additionally, empirical evaluations demonstrate their advantages over standard DQN baselines, which suggest that gradient-based target updates can serve as an effective alternative to conventional target update mechanisms in Q-learning.
Robust Deterministic Policy Gradient for Disturbance Attenuation and Its Application to Quadrotor Control
Feb 28, 2025



Practical control systems pose significant challenges in identifying optimal control policies due to uncertainties in the system model and external disturbances. While $H_\infty$ control techniques are commonly used to design robust controllers that mitigate the effects of disturbances, these methods often require complex and computationally intensive calculations. To address this issue, this paper proposes a reinforcement learning algorithm called Robust Deterministic Policy Gradient (RDPG), which formulates the $H_\infty$ control problem as a two-player zero-sum dynamic game. In this formulation, one player (the user) aims to minimize the cost, while the other player (the adversary) seeks to maximize it. We then employ deterministic policy gradient (DPG) and its deep reinforcement learning counterpart to train a robust control policy with effective disturbance attenuation. In particular, for practical implementation, we introduce an algorithm called robust deep deterministic policy gradient (RDDPG), which employs a deep neural network architecture and integrates techniques from the twin-delayed deep deterministic policy gradient (TD3) to enhance stability and learning efficiency. To evaluate the proposed algorithm, we implement it on an unmanned aerial vehicle (UAV) tasked with following a predefined path in a disturbance-prone environment. The experimental results demonstrate that the proposed method outperforms other control approaches in terms of robustness against disturbances, enabling precise real-time tracking of moving targets even under severe disturbance conditions.