 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Learning-Augmented Spanning Tree Algorithms via Metric Forest Completion
Feb 27, 2026We present improved learning-augmented algorithms for finding an approximate minimum spanning tree (MST) for points in an arbitrary metric space. Our work follows a recent framework called metric forest completion (MFC), where the learned input is a forest that must be given additional edges to form a full spanning tree. Veldt et al. (2025) showed that optimally completing the forest takes $Ω(n^2)$ time, but designed a 2.62-approximation for MFC with subquadratic complexity. The same method is a $(2γ+ 1)$-approximation for the original MST problem, where $γ\geq 1$ is a quality parameter for the initial forest. We introduce a generalized method that interpolates between this prior algorithm and an optimal $Ω(n^2)$-time MFC algorithm. Our approach considers only edges incident to a growing number of strategically chosen ``representative'' points. One corollary of our analysis is to improve the approximation factor of the previous algorithm from 2.62 for MFC and $(2γ+1)$ for metric MST to 2 and $2γ$ respectively. We prove this is tight for worst-case instances, but we still obtain better instance-specific approximations using our generalized method. We complement our theoretical results with a thorough experimental evaluation.
Approximate Tree Completion and Learning-Augmented Algorithms for Metric Minimum Spanning Trees
Feb 18, 2025



Finding a minimum spanning tree (MST) for $n$ points in an arbitrary metric space is a fundamental primitive for hierarchical clustering and many other ML tasks, but this takes $\Omega(n^2)$ time to even approximate. We introduce a framework for metric MSTs that first (1) finds a forest of disconnected components using practical heuristics, and then (2) finds a small weight set of edges to connect disjoint components of the forest into a spanning tree. We prove that optimally solving the second step still takes $\Omega(n^2)$ time, but we provide a subquadratic 2.62-approximation algorithm. In the spirit of learning-augmented algorithms, we then show that if the forest found in step (1) overlaps with an optimal MST, we can approximate the original MST problem in subquadratic time, where the approximation factor depends on a measure of overlap. In practice, we find nearly optimal spanning trees for a wide range of metrics, while being orders of magnitude faster than exact algorithms.
`Eyes of a Hawk and Ears of a Fox': Part Prototype Network for Generalized Zero-Shot Learning
Apr 12, 2024



Current approaches in Generalized Zero-Shot Learning (GZSL) are built upon base models which consider only a single class attribute vector representation over the entire image. This is an oversimplification of the process of novel category recognition, where different regions of the image may have properties from different seen classes and thus have different predominant attributes. With this in mind, we take a fundamentally different approach: a pre-trained Vision-Language detector (VINVL) sensitive to attribute information is employed to efficiently obtain region features. A learned function maps the region features to region-specific attribute attention used to construct class part prototypes. We conduct experiments on a popular GZSL benchmark consisting of the CUB, SUN, and AWA2 datasets where our proposed Part Prototype Network (PPN) achieves promising results when compared with other popular base models. Corresponding ablation studies and analysis show that our approach is highly practical and has a distinct advantage over global attribute attention when localized proposals are available.
CREPE: Learnable Prompting With CLIP Improves Visual Relationship Prediction
Jul 19, 2023In this paper, we explore the potential of Vision-Language Models (VLMs), specifically CLIP, in predicting visual object relationships, which involves interpreting visual features from images into language-based relations. Current state-of-the-art methods use complex graphical models that utilize language cues and visual features to address this challenge. We hypothesize that the strong language priors in CLIP embeddings can simplify these graphical models paving for a simpler approach. We adopt the UVTransE relation prediction framework, which learns the relation as a translational embedding with subject, object, and union box embeddings from a scene. We systematically explore the design of CLIP-based subject, object, and union-box representations within the UVTransE framework and propose CREPE (CLIP Representation Enhanced Predicate Estimation). CREPE utilizes text-based representations for all three bounding boxes and introduces a novel contrastive training strategy to automatically infer the text prompt for union-box. Our approach achieves state-of-the-art performance in predicate estimation, mR@5 27.79, and mR@20 31.95 on the Visual Genome benchmark, achieving a 15.3\% gain in performance over recent state-of-the-art at mR@20. This work demonstrates CLIP's effectiveness in object relation prediction and encourages further research on VLMs in this challenging domain.
Transfer Learning in Visual and Relational Reasoning
Nov 27, 2019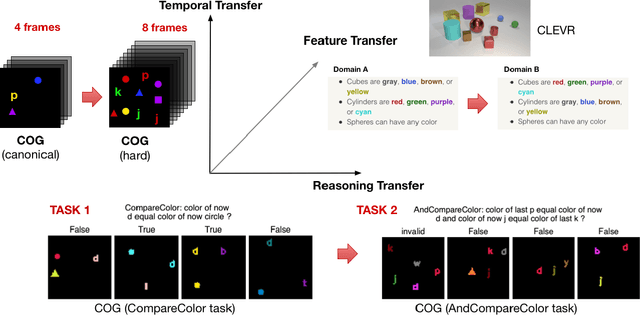
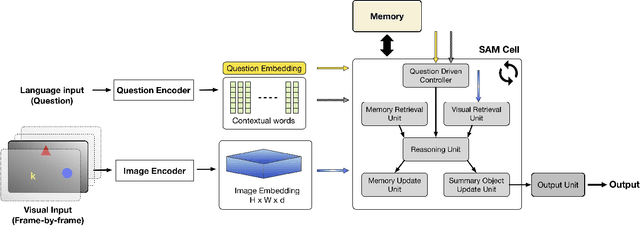

Transfer learning is becoming the de facto solution for vision and text encoders in the front-end processing of machine learning solutions. Utilizing vast amounts of knowledge in pre-trained models and subsequent fine-tuning allows achieving better performance in domains where labeled data is limited. In this paper, we analyze the efficiency of transfer learning in visual reasoning by introducing a new model (SAMNet) and testing it on two datasets: COG and CLEVR. Our new model achieves state-of-the-art accuracy on COG and shows significantly better generalization capabilities compared to the baseline. We also formalize a taxonomy of transfer learning for visual reasoning around three axes: feature, temporal, and reasoning transfer. Based on extensive experimentation of transfer learning on each of the two datasets, we show the performance of the new model along each axis.
On transfer learning using a MAC model variant
Nov 16, 2018

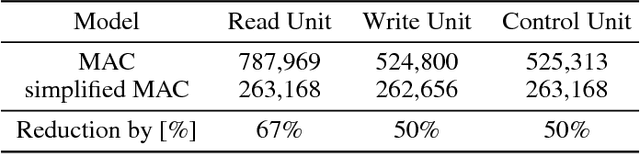

We introduce a variant of the MAC model (Hudson and Manning, ICLR 2018) with a simplified set of equations that achieves comparable accuracy, while training faster. We evaluate both models on CLEVR and CoGenT, and show that, transfer learning with fine-tuning results in a 15 point increase in accuracy, matching the state of the art. Finally, in contrast, we demonstrate that improper fine-tuning can actually reduce a model's accuracy as well.
Learning to Remember, Forget and Ignore using Attention Control in Memory
Sep 28, 2018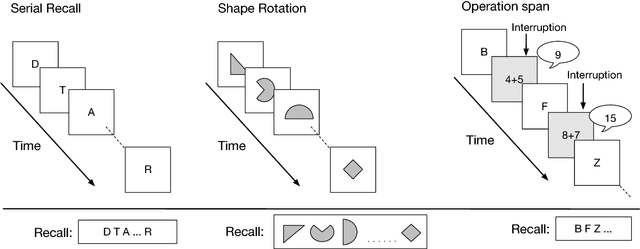


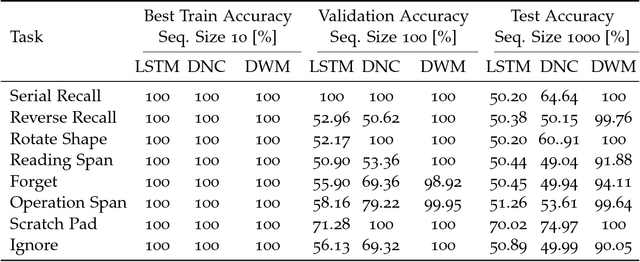
Typical neural networks with external memory do not effectively separate capacity for episodic and working memory as is required for reasoning in humans. Applying knowledge gained from psychological studies, we designed a new model called Differentiable Working Memory (DWM) in order to specifically emulate human working memory. As it shows the same functional characteristics as working memory, it robustly learns psychology inspired tasks and converges faster than comparable state-of-the-art models. Moreover, the DWM model successfully generalizes to sequences two orders of magnitude longer than the ones used in training. Our in-depth analysis shows that the behavior of DWM is interpretable and that it learns to have fine control over memory, allowing it to retain, ignore or forget information based on its relevance.
Using Multi-task and Transfer Learning to Solve Working Memory Tasks
Sep 28, 2018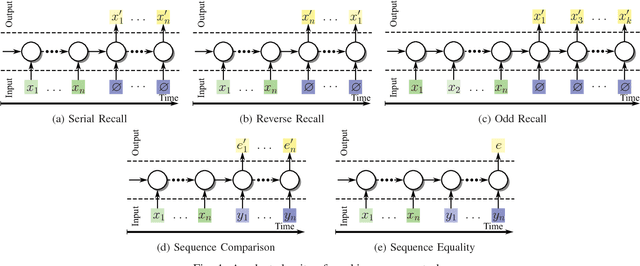
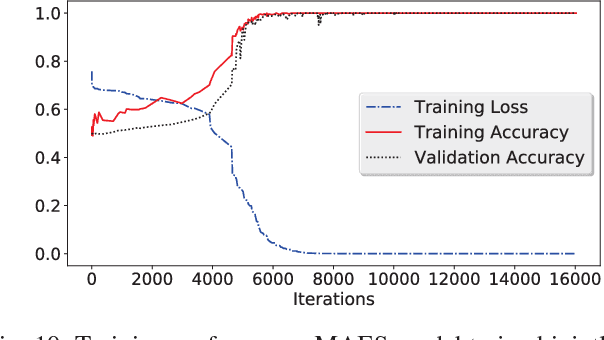

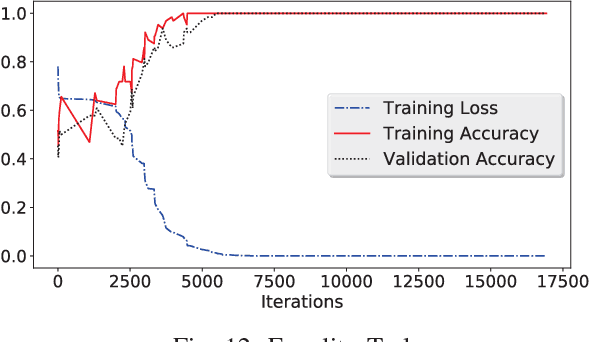
We propose a new architecture called Memory-Augmented Encoder-Solver (MAES) that enables transfer learning to solve complex working memory tasks adapted from cognitive psychology. It uses dual recurrent neural network controllers, inside the encoder and solver, respectively, that interface with a shared memory module and is completely differentiable. We study different types of encoders in a systematic manner and demonstrate a unique advantage of multi-task learning in obtaining the best possible encoder. We show by extensive experimentation that the trained MAES models achieve task-size generalization, i.e., they are capable of handling sequential inputs 50 times longer than seen during training, with appropriately large memory modules. We demonstrate that the performance achieved by MAES far outperforms existing and well-known models such as the LSTM, NTM and DNC on the entire suite of tasks.
Recovery of a Sparse Integer Solution to an Underdetermined System of Linear Equations
Dec 28, 2011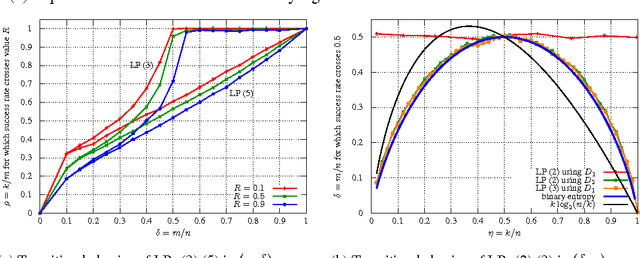
We consider a system of m linear equations in n variables Ax=b where A is a given m x n matrix and b is a given m-vector known to be equal to Ax' for some unknown solution x' that is integer and k-sparse: x' in {0,1}^n and exactly k entries of x' are 1. We give necessary and sufficient conditions for recovering the solution x exactly using an LP relaxation that minimizes l1 norm of x. When A is drawn from a distribution that has exchangeable columns, we show an interesting connection between the recovery probability and a well known problem in geometry, namely the k-set problem. To the best of our knowledge, this connection appears to be new in the compressive sensing literature. We empirically show that for large n if the elements of A are drawn i.i.d. from the normal distribution then the performance of the recovery LP exhibits a phase transition, i.e., for each k there exists a value m' of m such that the recovery always succeeds if m > m' and always fails if m < m'. Using the empirical data we conjecture that m' = nH(k/n)/2 where H(x) = -(x)log_2(x) - (1-x)log_2(1-x) is the binary entropy function.