 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Neuroevolution on Distributed FPGAs for Reinforcement Learning Problems
May 10, 2020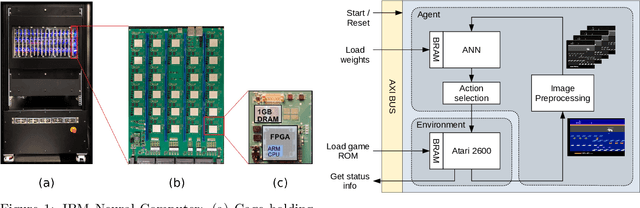
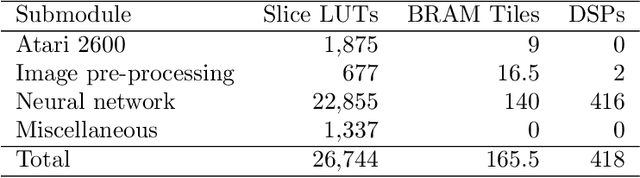

Reinforcement learning augmented by the representational power of deep neural networks, has shown promising results on high-dimensional problems, such as game playing and robotic control. However, the sequential nature of these problems poses a fundamental challenge for computational efficiency. Recently, alternative approaches such as evolutionary strategies and deep neuroevolution demonstrated competitive results with faster training time on distributed CPU cores. Here, we report record training times (running at about 1 million frames per second) for Atari 2600 games using deep neuroevolution implemented on distributed FPGAs. Combined hardware implementation of the game console, image pre-processing and the neural network in an optimized pipeline, multiplied with the system level parallelism enabled the acceleration. These results are the first application demonstration on the IBM Neural Computer, which is a custom designed system that consists of 432 Xilinx FPGAs interconnected in a 3D mesh network topology. In addition to high performance, experiments also showed improvement in accuracy for all games compared to the CPU-implementation of the same algorithm.
Simulation of neural function in an artificial Hebbian network
Dec 02, 2019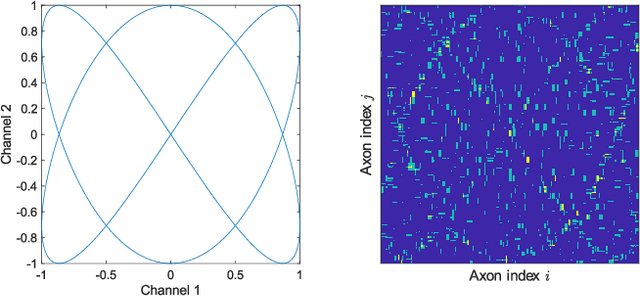
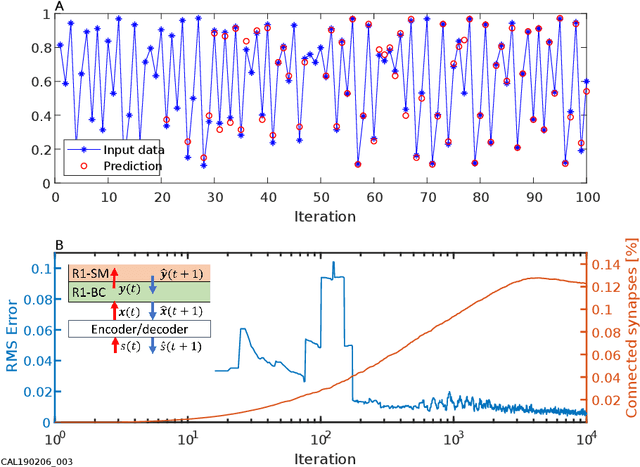
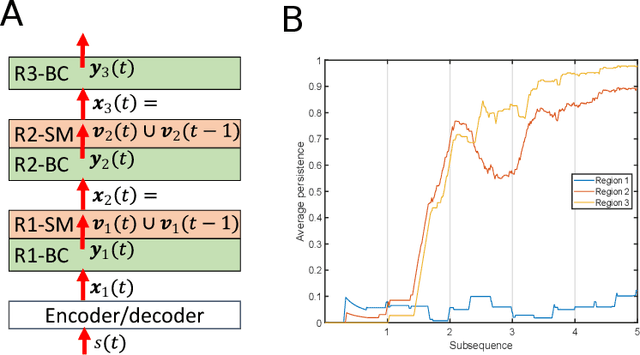
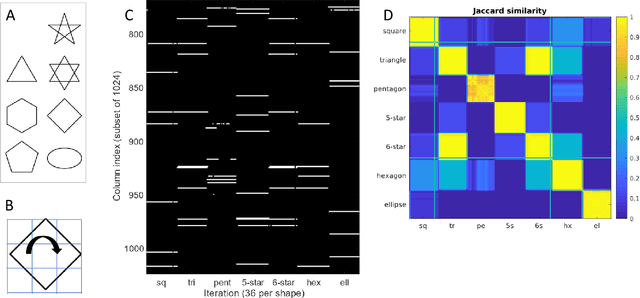
Artificial neural networks have diverged far from their early inspiration in neurology. In spite of their technological and commercial success, they have several shortcomings, most notably the need for a large number of training examples and the resulting computation resources required for iterative learning. Here we describe an approach to neurological network simulation, both architectural and algorithmic, that adheres more closely to established biological principles and overcomes some of the shortcomings of conventional networks.
Transfer Learning in Visual and Relational Reasoning
Nov 27, 2019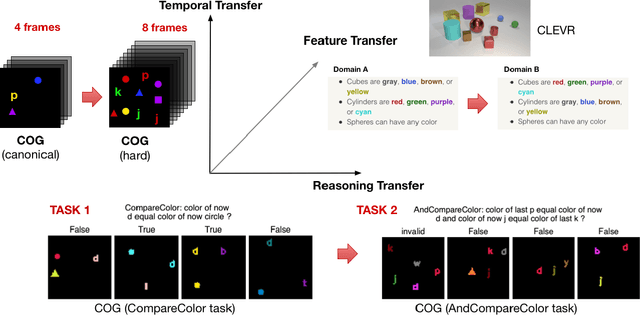
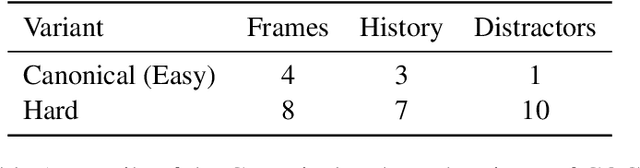

Transfer learning is becoming the de facto solution for vision and text encoders in the front-end processing of machine learning solutions. Utilizing vast amounts of knowledge in pre-trained models and subsequent fine-tuning allows achieving better performance in domains where labeled data is limited. In this paper, we analyze the efficiency of transfer learning in visual reasoning by introducing a new model (SAMNet) and testing it on two datasets: COG and CLEVR. Our new model achieves state-of-the-art accuracy on COG and shows significantly better generalization capabilities compared to the baseline. We also formalize a taxonomy of transfer learning for visual reasoning around three axes: feature, temporal, and reasoning transfer. Based on extensive experimentation of transfer learning on each of the two datasets, we show the performance of the new model along each axis.
Leveraging Medical Visual Question Answering with Supporting Facts
May 28, 2019
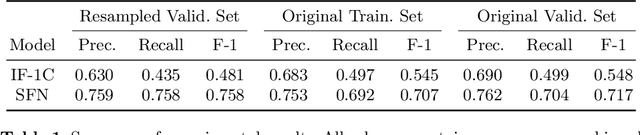
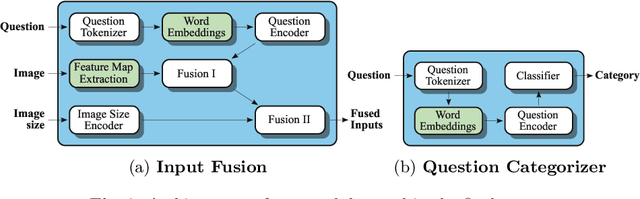
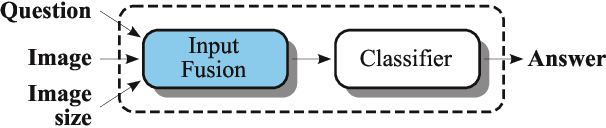
In this working notes paper, we describe IBM Research AI (Almaden) team's participation in the ImageCLEF 2019 VQA-Med competition. The challenge consists of four question-answering tasks based on radiology images. The diversity of imaging modalities, organs and disease types combined with a small imbalanced training set made this a highly complex problem. To overcome these difficulties, we implemented a modular pipeline architecture that utilized transfer learning and multi-task learning. Our findings led to the development of a novel model called Supporting Facts Network (SFN). The main idea behind SFN is to cross-utilize information from upstream tasks to improve the accuracy on harder downstream ones. This approach significantly improved the scores achieved in the validation set (18 point improvement in F-1 score). Finally, we submitted four runs to the competition and were ranked seventh.
On transfer learning using a MAC model variant
Nov 16, 2018

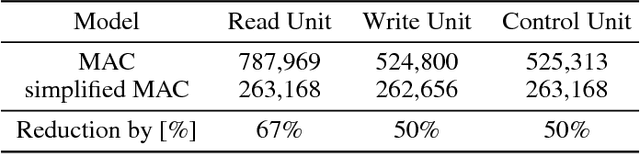

We introduce a variant of the MAC model (Hudson and Manning, ICLR 2018) with a simplified set of equations that achieves comparable accuracy, while training faster. We evaluate both models on CLEVR and CoGenT, and show that, transfer learning with fine-tuning results in a 15 point increase in accuracy, matching the state of the art. Finally, in contrast, we demonstrate that improper fine-tuning can actually reduce a model's accuracy as well.
Learning to Remember, Forget and Ignore using Attention Control in Memory
Sep 28, 2018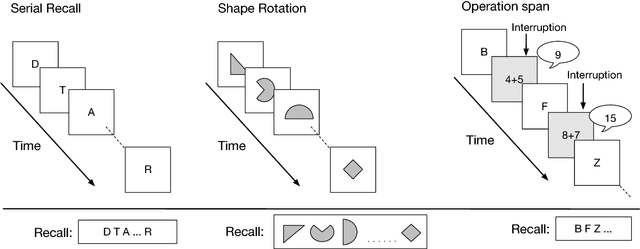


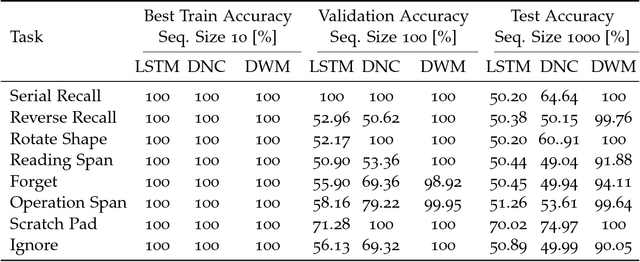
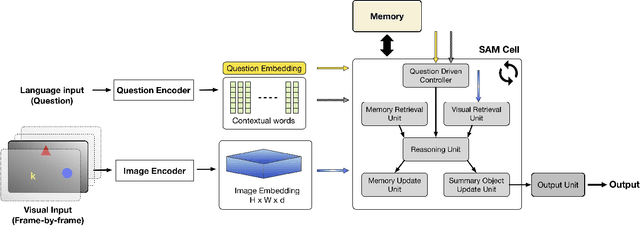
Typical neural networks with external memory do not effectively separate capacity for episodic and working memory as is required for reasoning in humans. Applying knowledge gained from psychological studies, we designed a new model called Differentiable Working Memory (DWM) in order to specifically emulate human working memory. As it shows the same functional characteristics as working memory, it robustly learns psychology inspired tasks and converges faster than comparable state-of-the-art models. Moreover, the DWM model successfully generalizes to sequences two orders of magnitude longer than the ones used in training. Our in-depth analysis shows that the behavior of DWM is interpretable and that it learns to have fine control over memory, allowing it to retain, ignore or forget information based on its relevance.
Using Multi-task and Transfer Learning to Solve Working Memory Tasks
Sep 28, 2018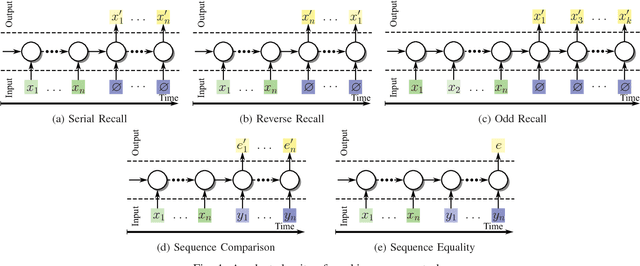
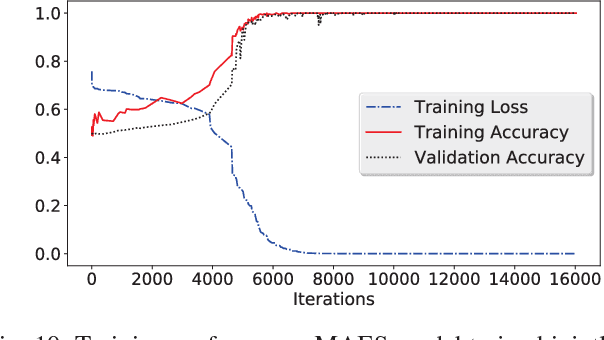

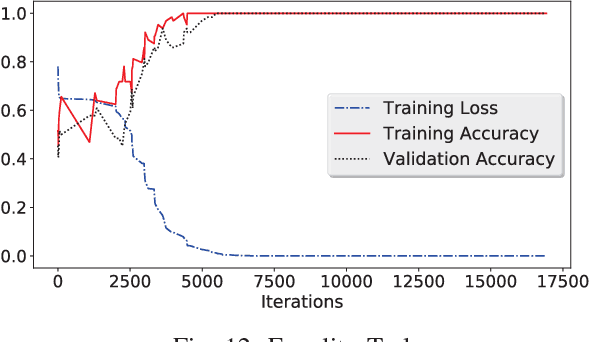
We propose a new architecture called Memory-Augmented Encoder-Solver (MAES) that enables transfer learning to solve complex working memory tasks adapted from cognitive psychology. It uses dual recurrent neural network controllers, inside the encoder and solver, respectively, that interface with a shared memory module and is completely differentiable. We study different types of encoders in a systematic manner and demonstrate a unique advantage of multi-task learning in obtaining the best possible encoder. We show by extensive experimentation that the trained MAES models achieve task-size generalization, i.e., they are capable of handling sequential inputs 50 times longer than seen during training, with appropriately large memory modules. We demonstrate that the performance achieved by MAES far outperforms existing and well-known models such as the LSTM, NTM and DNC on the entire suite of tasks.