 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECIDER: Leveraging Foundation Model Priors for Improved Model Failure Detection and Explanation
Aug 01, 2024



Reliably detecting when a deployed machine learning model is likely to fail on a given input is crucial for ensuring safe operation. In this work, we propose DECIDER (Debiasing Classifiers to Identify Errors Reliably), a novel approach that leverages priors from large language models (LLMs) and vision-language models (VLMs) to detect failures in image classification models. DECIDER utilizes LLMs to specify task-relevant core attributes and constructs a ``debiased'' version of the classifier by aligning its visual features to these core attributes using a VLM, and detects potential failure by measuring disagreement between the original and debiased models. In addition to proactively identifying samples on which the model would fail, DECIDER also provides human-interpretable explanations for failure through a novel attribute-ablation strategy. Through extensive experiments across diverse benchmarks spanning subpopulation shifts (spurious correlations, class imbalance) and covariate shifts (synthetic corruptions, domain shifts), DECIDER consistently achieves state-of-the-art failure detection performance, significantly outperforming baselines in terms of the overall Matthews correlation coefficient as well as failure and success recall. Our codes can be accessed at~\url{https://github.com/kowshikthopalli/DECIDER/}
CREPE: Learnable Prompting With CLIP Improves Visual Relationship Prediction
Jul 19, 2023In this paper, we explore the potential of Vision-Language Models (VLMs), specifically CLIP, in predicting visual object relationships, which involves interpreting visual features from images into language-based relations. Current state-of-the-art methods use complex graphical models that utilize language cues and visual features to address this challenge. We hypothesize that the strong language priors in CLIP embeddings can simplify these graphical models paving for a simpler approach. We adopt the UVTransE relation prediction framework, which learns the relation as a translational embedding with subject, object, and union box embeddings from a scene. We systematically explore the design of CLIP-based subject, object, and union-box representations within the UVTransE framework and propose CREPE (CLIP Representation Enhanced Predicate Estimation). CREPE utilizes text-based representations for all three bounding boxes and introduces a novel contrastive training strategy to automatically infer the text prompt for union-box. Our approach achieves state-of-the-art performance in predicate estimation, mR@5 27.79, and mR@20 31.95 on the Visual Genome benchmark, achieving a 15.3\% gain in performance over recent state-of-the-art at mR@20. This work demonstrates CLIP's effectiveness in object relation prediction and encourages further research on VLMs in this challenging domain.
Target-Aware Generative Augmentations for Single-Shot Adaptation
May 22, 2023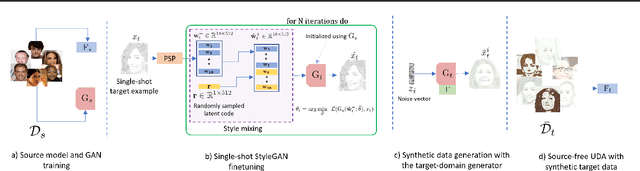
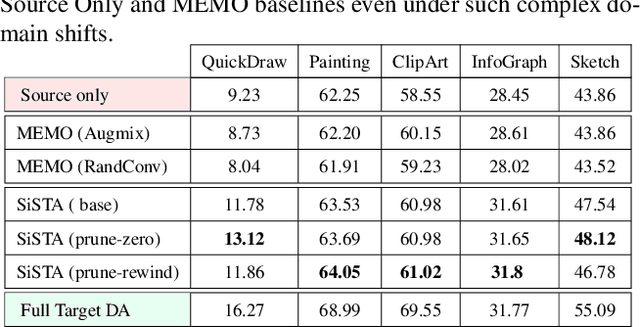
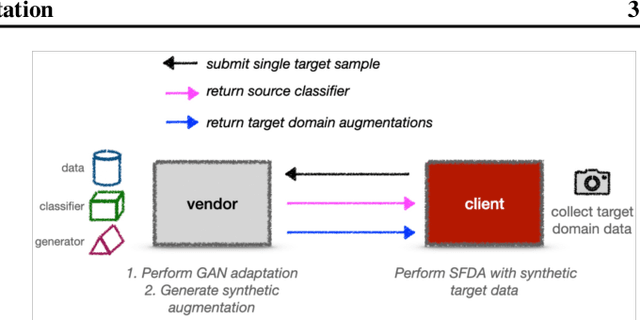
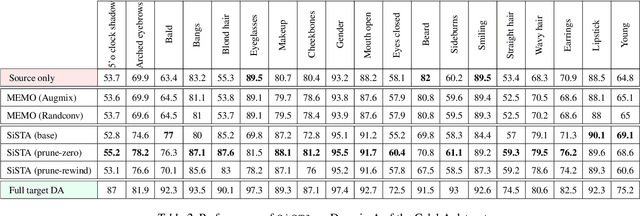
In this paper, we address the problem of adapting models from a source domain to a target domain, a task that has become increasingly important due to the brittle generalization of deep neural networks. While several test-time adaptation techniques have emerged, they typically rely on synthetic toolbox data augmentations in cases of limited target data availability. We consider the challenging setting of single-shot adaptation and explore the design of augmentation strategies. We argue that augmentations utilized by existing methods are insufficient to handle large distribution shifts, and hence propose a new approach SiSTA, which first fine-tunes a generative model from the source domain using a single-shot target, and then employs novel sampling strategies for curating synthetic target data. Using experiments on a variety of benchmarks, distribution shifts and image corruptions, we find that SiSTA produces significantly improved generalization over existing baselines in face attribute detection and multi-class object recognition. Furthermore, SiSTA performs competitively to models obtained by training on larger target datasets. Our codes can be accessed at https://github.com/Rakshith-2905/SiSTA.
Single-Shot Domain Adaptation via Target-Aware Generative Augmentation
Oct 29, 2022The problem of adapting models from a source domain using data from any target domain of interest has gained prominence, thanks to the brittle generalization in deep neural networks. While several test-time adaptation techniques have emerged, they typically rely on synthetic data augmentations in cases of limited target data availability. In this paper, we consider the challenging setting of single-shot adaptation and explore the design of augmentation strategies. We argue that augmentations utilized by existing methods are insufficient to handle large distribution shifts, and hence propose a new approach SiSTA (Single-Shot Target Augmentations), which first fine-tunes a generative model from the source domain using a single-shot target, and then employs novel sampling strategies for curating synthetic target data. Using experiments with a state-of-the-art domain adaptation method, we find that SiSTA produces improvements as high as 20\% over existing baselines under challenging shifts in face attribute detection, and that it performs competitively to oracle models obtained by training on a larger target dataset.
Contrastive Knowledge-Augmented Meta-Learning for Few-Shot Classification
Jul 25, 2022
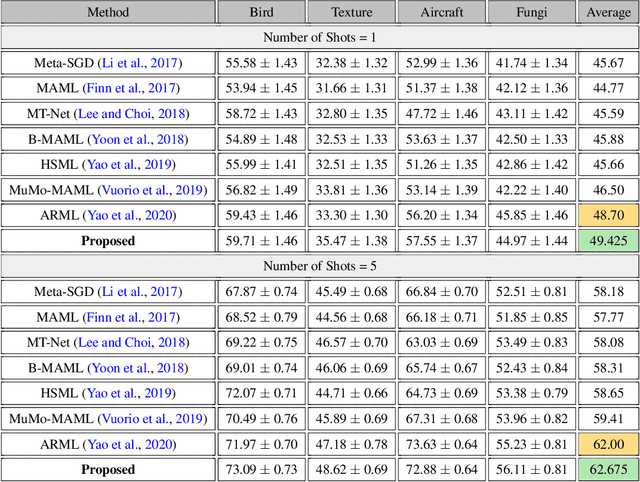
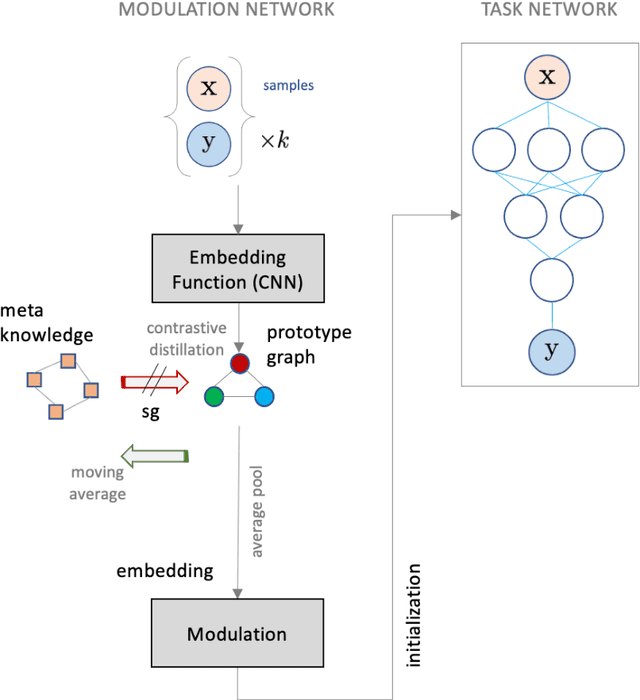
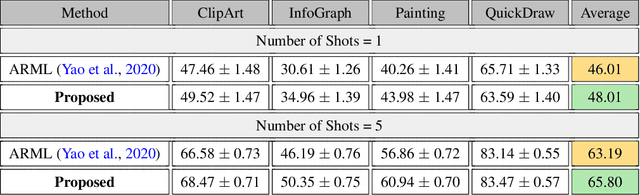
Model agnostic meta-learning algorithms aim to infer priors from several observed tasks that can then be used to adapt to a new task with few examples. Given the inherent diversity of tasks arising in existing benchmarks, recent methods use separate, learnable structure, such as hierarchies or graphs, for enabling task-specific adaptation of the prior. While these approaches have produced significantly better meta learners, our goal is to improve their performance when the heterogeneous task distribution contains challenging distribution shifts and semantic disparities. To this end, we introduce CAML (Contrastive Knowledge-Augmented Meta Learning), a novel approach for knowledge-enhanced few-shot learning that evolves a knowledge graph to effectively encode historical experience, and employs a contrastive distillation strategy to leverage the encoded knowledge for task-aware modulation of the base learner. Using standard benchmarks, we evaluate the performance of CAML in different few-shot learning scenarios. In addition to the standard few-shot task adaptation, we also consider the more challenging multi-domain task adaptation and few-shot dataset generalization settings in our empirical studies. Our results shows that CAML consistently outperforms best known approaches and achieves improved generalization.