 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Learning-Augmented Spanning Tree Algorithms via Metric Forest Completion
Feb 27, 2026We present improved learning-augmented algorithms for finding an approximate minimum spanning tree (MST) for points in an arbitrary metric space. Our work follows a recent framework called metric forest completion (MFC), where the learned input is a forest that must be given additional edges to form a full spanning tree. Veldt et al. (2025) showed that optimally completing the forest takes $Ω(n^2)$ time, but designed a 2.62-approximation for MFC with subquadratic complexity. The same method is a $(2γ+ 1)$-approximation for the original MST problem, where $γ\geq 1$ is a quality parameter for the initial forest. We introduce a generalized method that interpolates between this prior algorithm and an optimal $Ω(n^2)$-time MFC algorithm. Our approach considers only edges incident to a growing number of strategically chosen ``representative'' points. One corollary of our analysis is to improve the approximation factor of the previous algorithm from 2.62 for MFC and $(2γ+1)$ for metric MST to 2 and $2γ$ respectively. We prove this is tight for worst-case instances, but we still obtain better instance-specific approximations using our generalized method. We complement our theoretical results with a thorough experimental evaluation.
Approximate Tree Completion and Learning-Augmented Algorithms for Metric Minimum Spanning Trees
Feb 18, 2025



Finding a minimum spanning tree (MST) for $n$ points in an arbitrary metric space is a fundamental primitive for hierarchical clustering and many other ML tasks, but this takes $\Omega(n^2)$ time to even approximate. We introduce a framework for metric MSTs that first (1) finds a forest of disconnected components using practical heuristics, and then (2) finds a small weight set of edges to connect disjoint components of the forest into a spanning tree. We prove that optimally solving the second step still takes $\Omega(n^2)$ time, but we provide a subquadratic 2.62-approximation algorithm. In the spirit of learning-augmented algorithms, we then show that if the forest found in step (1) overlaps with an optimal MST, we can approximate the original MST problem in subquadratic time, where the approximation factor depends on a measure of overlap. In practice, we find nearly optimal spanning trees for a wide range of metrics, while being orders of magnitude faster than exact algorithms.
Correspondence of NNGP Kernel and the Matern Kernel
Oct 10, 2024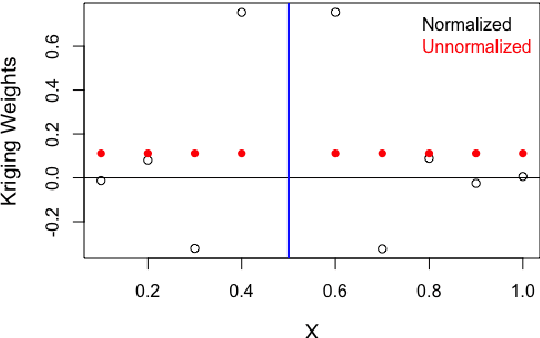
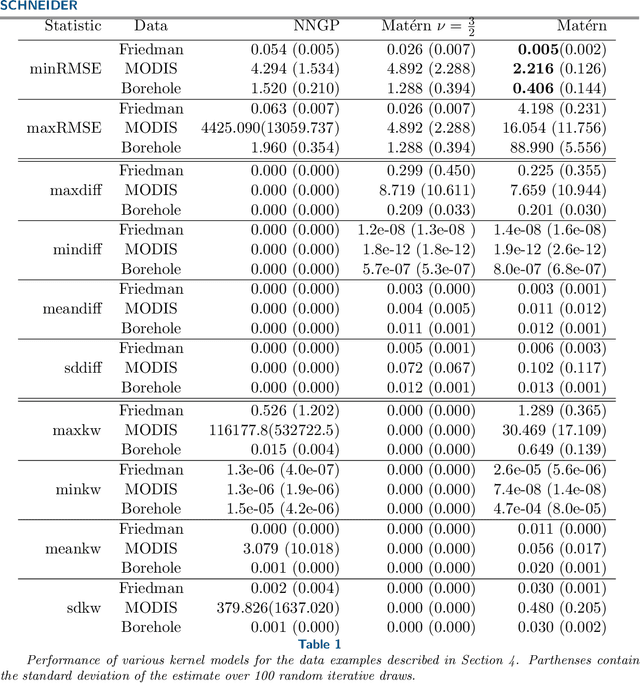
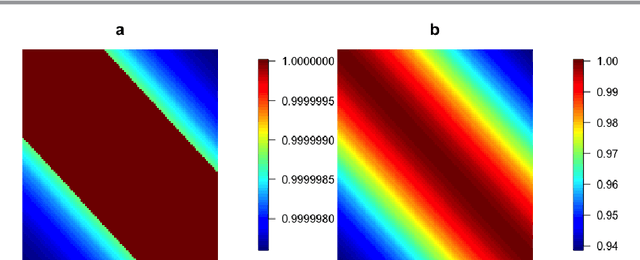
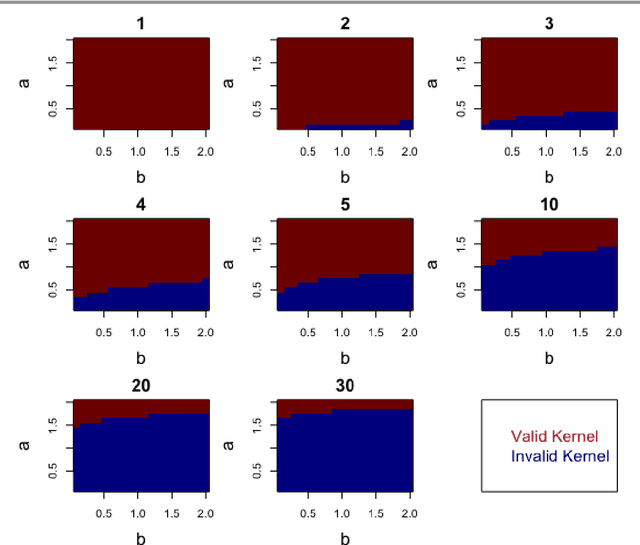
Kernels representing limiting cases of neural network architectures have recently gained popularity. However, the application and performance of these new kernels compared to existing options, such as the Matern kernel, is not well studied. We take a practical approach to explore the neural network Gaussian process (NNGP) kernel and its application to data in Gaussian process regression. We first demonstrate the necessity of normalization to produce valid NNGP kernels and explore related numerical challenges. We further demonstrate that the predictions from this model are quite inflexible, and therefore do not vary much over the valid hyperparameter sets. We then demonstrate a surprising result that the predictions given from the NNGP kernel correspond closely to those given by the Matern kernel under specific circumstances, which suggests a deep similarity between overparameterized deep neural networks and the Matern kernel. Finally, we demonstrate the performance of the NNGP kernel as compared to the Matern kernel on three benchmark data cases, and we conclude that for its flexibility and practical performance, the Matern kernel is preferred to the novel NNGP in practical applications.
Scalable Gaussian Process Hyperparameter Optimization via Coverage Regularization
Sep 22, 2022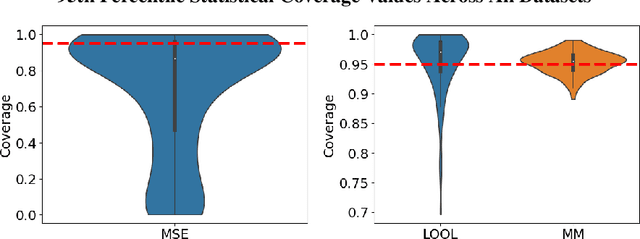
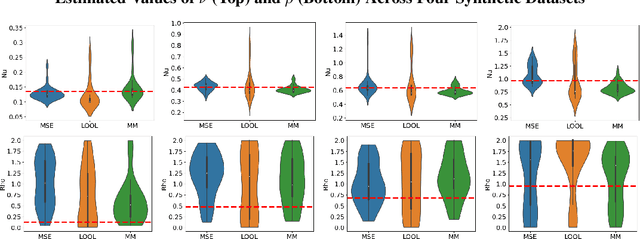

Gaussian processes (GPs) are Bayesian non-parametric models popular in a variety of applications due to their accuracy and native uncertainty quantification (UQ). Tuning GP hyperparameters is critical to ensure the validity of prediction accuracy and uncertainty; uniquely estimating multiple hyperparameters in, e.g. the Matern kernel can also be a significant challenge. Moreover, training GPs on large-scale datasets is a highly active area of research: traditional maximum likelihood hyperparameter training requires quadratic memory to form the covariance matrix and has cubic training complexity. To address the scalable hyperparameter tuning problem, we present a novel algorithm which estimates the smoothness and length-scale parameters in the Matern kernel in order to improve robustness of the resulting prediction uncertainties. Using novel loss functions similar to those in conformal prediction algorithms in the computational framework provided by the hyperparameter estimation algorithm MuyGPs, we achieve improved UQ over leave-one-out likelihood maximization while maintaining a high degree of scalability as demonstrated in numerical experiments.
Light curve completion and forecasting using fast and scalable Gaussian processes (MuyGPs)
Aug 31, 2022

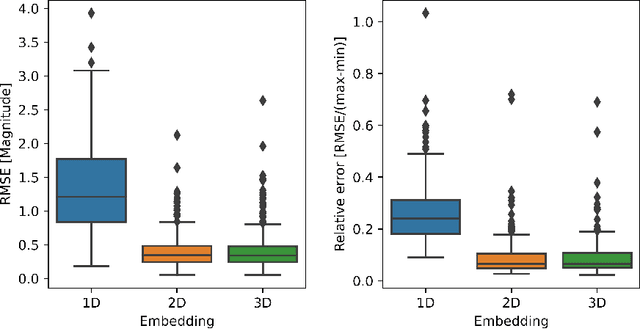
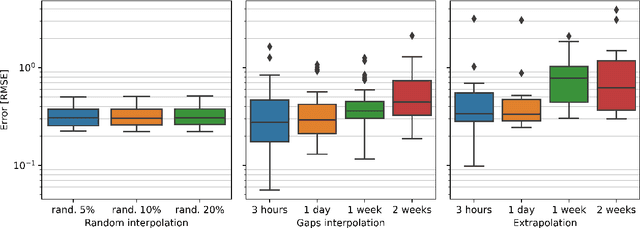
Temporal variations of apparent magnitude, called light curves, are observational statistics of interest captured by telescopes over long periods of time. Light curves afford the exploration of Space Domain Awareness (SDA) objectives such as object identification or pose estimation as latent variable inference problems. Ground-based observations from commercial off the shelf (COTS) cameras remain inexpensive compared to higher precision instruments, however, limited sensor availability combined with noisier observations can produce gappy time-series data that can be difficult to model. These external factors confound the automated exploitation of light curves, which makes light curve prediction and extrapolation a crucial problem for applications. Traditionally, image or time-series completion problems have been approached with diffusion-based or exemplar-based methods. More recently, Deep Neural Networks (DNNs) have become the tool of choice due to their empirical success at learning complex nonlinear embeddings. However, DNNs often require large training data that are not necessarily available when looking at unique features of a light curve of a single satellite. In this paper, we present a novel approach to predicting missing and future data points of light curves using Gaussian Processes (GPs). GPs are non-linear probabilistic models that infer posterior distributions over functions and naturally quantify uncertainty. However, the cubic scaling of GP inference and training is a major barrier to their adoption in applications. In particular, a single light curve can feature hundreds of thousands of observations, which is well beyond the practical realization limits of a conventional GP on a single machine. Consequently, we employ MuyGPs, a scalable framework for hyperparameter estimation of GP models that uses nearest neighbors sparsification and local cross-validation. MuyGPs...
Fast Gaussian Process Posterior Mean Prediction via Local Cross Validation and Precomputation
May 22, 2022

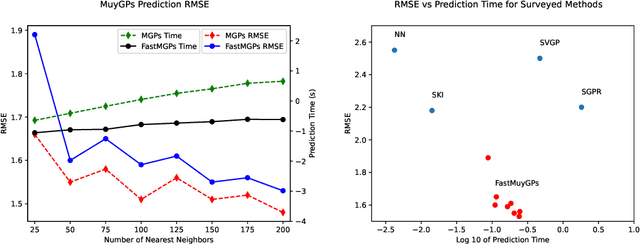

Gaussian processes (GPs) are Bayesian non-parametric models useful in a myriad of applications. Despite their popularity, the cost of GP predictions (quadratic storage and cubic complexity with respect to the number of training points) remains a hurdle in applying GPs to large data. We present a fast posterior mean prediction algorithm called FastMuyGPs to address this shortcoming. FastMuyGPs is based upon the MuyGPs hyperparameter estimation algorithm and utilizes a combination of leave-one-out cross-validation, batching, nearest neighbors sparsification, and precomputation to provide scalable, fast GP prediction. We demonstrate several benchmarks wherein FastMuyGPs prediction attains superior accuracy and competitive or superior runtime to both deep neural networks and state-of-the-art scalable GP algorithms.
Scaling Graph Clustering with Distributed Sketches
Jul 24, 2020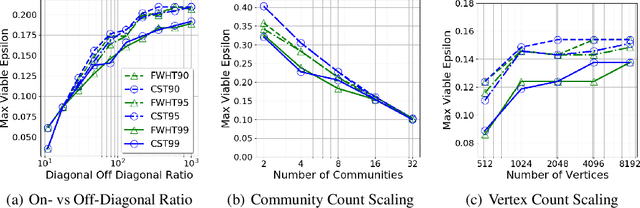
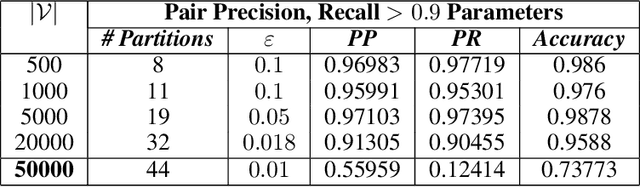
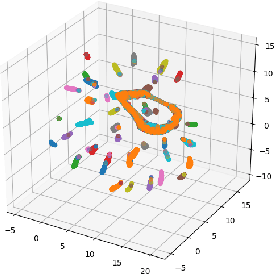
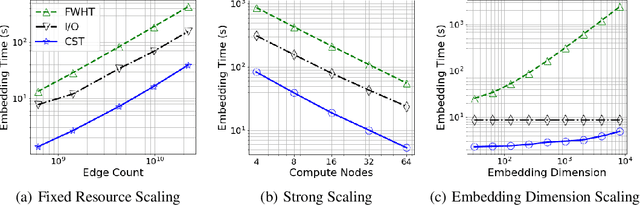
The unsupervised learning of community structure, in particular the partitioning vertices into clusters or communities, is a canonical and well-studied problem in exploratory graph analysis. However, like most graph analyses the introduction of immense scale presents challenges to traditional methods. Spectral clustering in distributed memory, for example, requires hundreds of expensive bulk-synchronous communication rounds to compute an embedding of vertices to a few eigenvectors of a graph associated matrix. Furthermore, the whole computation may need to be repeated if the underlying graph changes some low percentage of edge updates. We present a method inspired by spectral clustering where we instead use matrix sketches derived from random dimension-reducing projections. We show that our method produces embeddings that yield performant clustering results given a fully-dynamic stochastic block model stream using both the fast Johnson-Lindenstrauss and CountSketch transforms. We also discuss the effects of stochastic block model parameters upon the required dimensionality of the subsequent embeddings, and show how random projections could significantly improve the performance of graph clustering in distributed memory.
Reinforcement Learning via Gaussian Processes with Neural Network Dual Kernels
Apr 10, 2020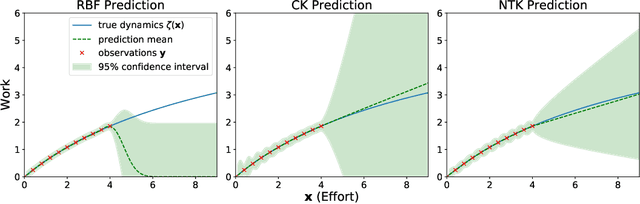
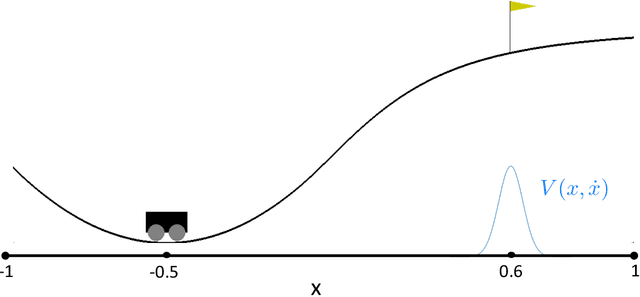
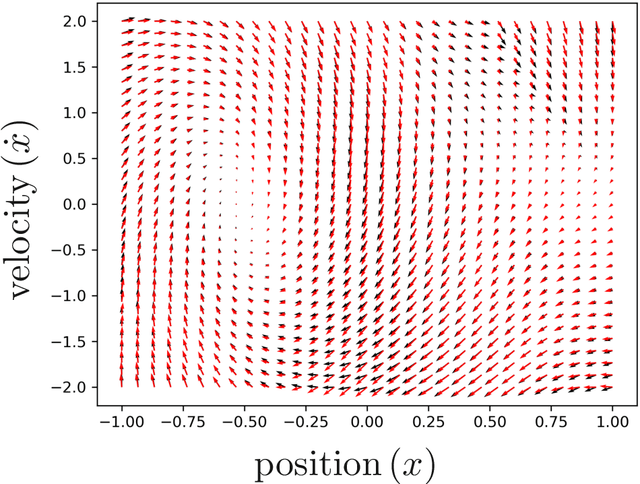
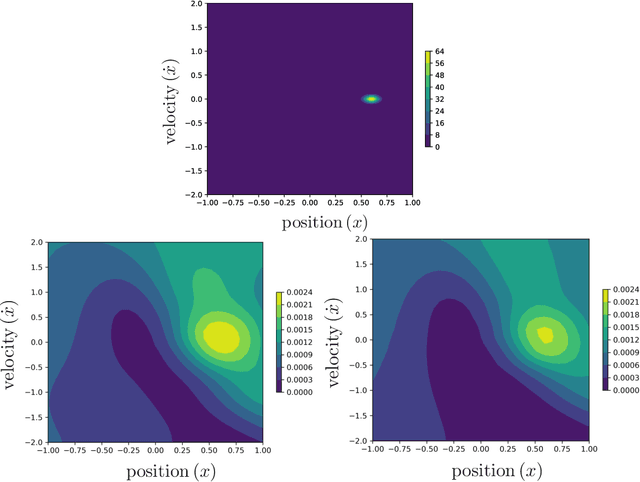
While deep neural networks (DNNs) and Gaussian Processes (GPs) are both popularly utilized to solve problems in reinforcement learning, both approaches feature undesirable drawbacks for challenging problems. DNNs learn complex nonlinear embeddings, but do not naturally quantify uncertainty and are often data-inefficient to train. GPs infer posterior distributions over functions, but popular kernels exhibit limited expressivity on complex and high-dimensional data. Fortunately, recently discovered conjugate and neural tangent kernel functions encode the behavior of overparameterized neural networks in the kernel domain. We demonstrate that these kernels can be efficiently applied to regression and reinforcement learning problems by analyzing a baseline case study. We apply GPs with neural network dual kernels to solve reinforcement learning tasks for the first time. We demonstrate, using the well-understood mountain-car problem, that GPs empowered with dual kernels perform at least as well as those using the conventional radial basis function kernel. We conjecture that by inheriting the probabilistic rigor of GPs and the powerful embedding properties of DNNs, GPs using NN dual kernels will empower future reinforcement learning models on difficult domains.