 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight curve completion and forecasting using fast and scalable Gaussian processes (MuyGPs)
Aug 31, 2022

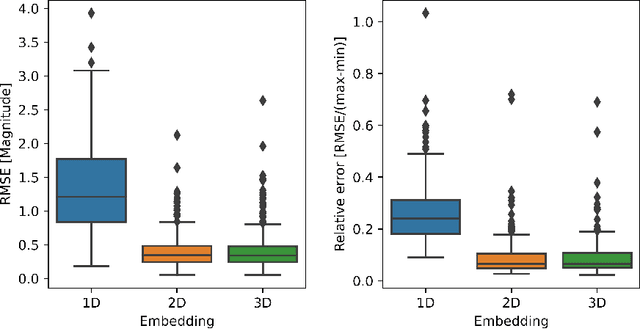
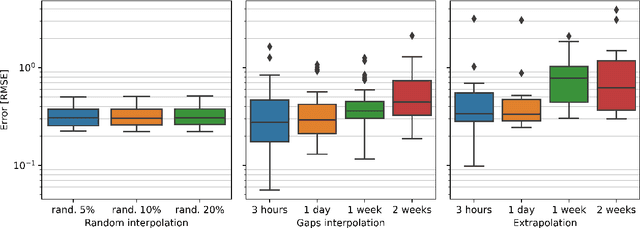
Temporal variations of apparent magnitude, called light curves, are observational statistics of interest captured by telescopes over long periods of time. Light curves afford the exploration of Space Domain Awareness (SDA) objectives such as object identification or pose estimation as latent variable inference problems. Ground-based observations from commercial off the shelf (COTS) cameras remain inexpensive compared to higher precision instruments, however, limited sensor availability combined with noisier observations can produce gappy time-series data that can be difficult to model. These external factors confound the automated exploitation of light curves, which makes light curve prediction and extrapolation a crucial problem for applications. Traditionally, image or time-series completion problems have been approached with diffusion-based or exemplar-based methods. More recently, Deep Neural Networks (DNNs) have become the tool of choice due to their empirical success at learning complex nonlinear embeddings. However, DNNs often require large training data that are not necessarily available when looking at unique features of a light curve of a single satellite. In this paper, we present a novel approach to predicting missing and future data points of light curves using Gaussian Processes (GPs). GPs are non-linear probabilistic models that infer posterior distributions over functions and naturally quantify uncertainty. However, the cubic scaling of GP inference and training is a major barrier to their adoption in applications. In particular, a single light curve can feature hundreds of thousands of observations, which is well beyond the practical realization limits of a conventional GP on a single machine. Consequently, we employ MuyGPs, a scalable framework for hyperparameter estimation of GP models that uses nearest neighbors sparsification and local cross-validation. MuyGPs...
Reinforcement Learning via Gaussian Processes with Neural Network Dual Kernels
Apr 10, 2020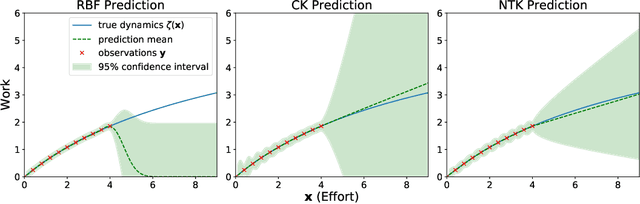
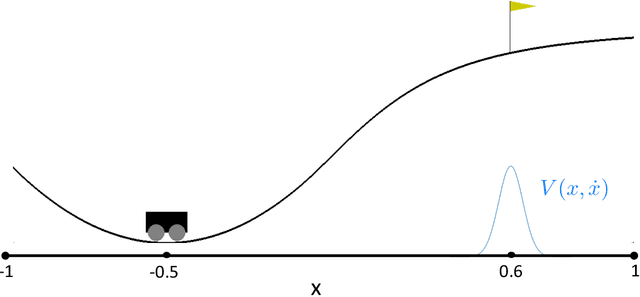
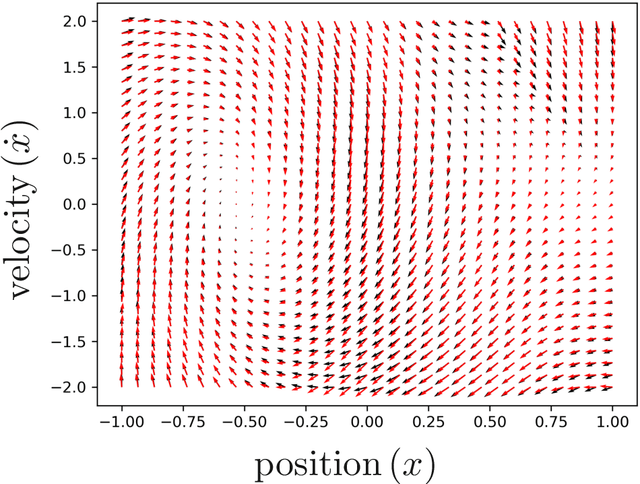
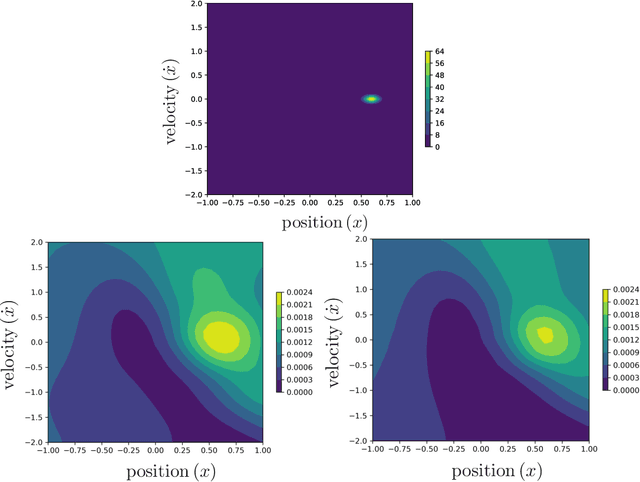
While deep neural networks (DNNs) and Gaussian Processes (GPs) are both popularly utilized to solve problems in reinforcement learning, both approaches feature undesirable drawbacks for challenging problems. DNNs learn complex nonlinear embeddings, but do not naturally quantify uncertainty and are often data-inefficient to train. GPs infer posterior distributions over functions, but popular kernels exhibit limited expressivity on complex and high-dimensional data. Fortunately, recently discovered conjugate and neural tangent kernel functions encode the behavior of overparameterized neural networks in the kernel domain. We demonstrate that these kernels can be efficiently applied to regression and reinforcement learning problems by analyzing a baseline case study. We apply GPs with neural network dual kernels to solve reinforcement learning tasks for the first time. We demonstrate, using the well-understood mountain-car problem, that GPs empowered with dual kernels perform at least as well as those using the conventional radial basis function kernel. We conjecture that by inheriting the probabilistic rigor of GPs and the powerful embedding properties of DNNs, GPs using NN dual kernels will empower future reinforcement learning models on difficult domains.