 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTROPE: TRaining-Free Object-Part Enhancement for Seamlessly Improving Fine-Grained Zero-Shot Image Captioning
Sep 30, 2024



Zero-shot inference, where pre-trained models perform tasks without specific training data, is an exciting emergent ability of large models like CLIP. Although there has been considerable exploration into enhancing zero-shot abilities in image captioning (IC) for popular datasets such as MSCOCO and Flickr8k, these approaches fall short with fine-grained datasets like CUB, FLO, UCM-Captions, and Sydney-Captions. These datasets require captions to discern between visually and semantically similar classes, focusing on detailed object parts and their attributes. To overcome this challenge, we introduce TRaining-Free Object-Part Enhancement (TROPE). TROPE enriches a base caption with additional object-part details using object detector proposals and Natural Language Processing techniques. It complements rather than alters the base caption, allowing seamless integration with other captioning methods and offering users enhanced flexibility. Our evaluations show that TROPE consistently boosts performance across all tested zero-shot IC approaches and achieves state-of-the-art results on fine-grained IC datasets.
Grounding Stylistic Domain Generalization with Quantitative Domain Shift Measures and Synthetic Scene Images
May 24, 2024



Domain Generalization (DG) is a challenging task in machine learning that requires a coherent ability to comprehend shifts across various domains through extraction of domain-invariant features. DG performance is typically evaluated by performing image classification in domains of various image styles. However, current methodology lacks quantitative understanding about shifts in stylistic domain, and relies on a vast amount of pre-training data, such as ImageNet1K, which are predominantly in photo-realistic style with weakly supervised class labels. Such a data-driven practice could potentially result in spurious correlation and inflated performance on DG benchmarks. In this paper, we introduce a new DG paradigm to address these risks. We first introduce two new quantitative measures ICV and IDD to describe domain shifts in terms of consistency of classes within one domain and similarity between two stylistic domains. We then present SuperMarioDomains (SMD), a novel synthetic multi-domain dataset sampled from video game scenes with more consistent classes and sufficient dissimilarity compared to ImageNet1K. We demonstrate our DG method SMOS. SMOS first uses SMD to train a precursor model, which is then used to ground the training on a DG benchmark. We observe that SMOS contributes to state-of-the-art performance across five DG benchmarks, gaining large improvements to performances on abstract domains along with on-par or slight improvements to those on photo-realistic domains. Our qualitative analysis suggests that these improvements can be attributed to reduced distributional divergence between originally distant domains. Our data are available at https://github.com/fpsluozi/SMD-SMOS .
`Eyes of a Hawk and Ears of a Fox': Part Prototype Network for Generalized Zero-Shot Learning
Apr 12, 2024



Current approaches in Generalized Zero-Shot Learning (GZSL) are built upon base models which consider only a single class attribute vector representation over the entire image. This is an oversimplification of the process of novel category recognition, where different regions of the image may have properties from different seen classes and thus have different predominant attributes. With this in mind, we take a fundamentally different approach: a pre-trained Vision-Language detector (VINVL) sensitive to attribute information is employed to efficiently obtain region features. A learned function maps the region features to region-specific attribute attention used to construct class part prototypes. We conduct experiments on a popular GZSL benchmark consisting of the CUB, SUN, and AWA2 datasets where our proposed Part Prototype Network (PPN) achieves promising results when compared with other popular base models. Corresponding ablation studies and analysis show that our approach is highly practical and has a distinct advantage over global attribute attention when localized proposals are available.
Towards Addressing the Misalignment of Object Proposal Evaluation for Vision-Language Tasks via Semantic Grounding
Sep 01, 2023Object proposal generation serves as a standard pre-processing step in Vision-Language (VL) tasks (image captioning, visual question answering, etc.). The performance of object proposals generated for VL tasks is currently evaluated across all available annotations, a protocol that we show is misaligned - higher scores do not necessarily correspond to improved performance on downstream VL tasks. Our work serves as a study of this phenomenon and explores the effectiveness of semantic grounding to mitigate its effects. To this end, we propose evaluating object proposals against only a subset of available annotations, selected by thresholding an annotation importance score. Importance of object annotations to VL tasks is quantified by extracting relevant semantic information from text describing the image. We show that our method is consistent and demonstrates greatly improved alignment with annotations selected by image captioning metrics and human annotation when compared against existing techniques. Lastly, we compare current detectors used in the Scene Graph Generation (SGG) benchmark as a use case, which serves as an example of when traditional object proposal evaluation techniques are misaligned.
SMURF: SeMantic and linguistic UndeRstanding Fusion for Caption Evaluation via Typicality Analysis
Jun 02, 2021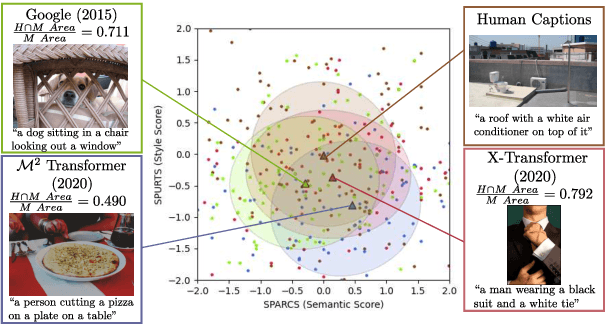



The open-ended nature of visual captioning makes it a challenging area for evaluation. The majority of proposed models rely on specialized training to improve human-correlation, resulting in limited adoption, generalizability, and explainabilty. We introduce "typicality", a new formulation of evaluation rooted in information theory, which is uniquely suited for problems lacking a definite ground truth. Typicality serves as our framework to develop a novel semantic comparison, SPARCS, as well as referenceless fluency evaluation metrics. Over the course of our analysis, two separate dimensions of fluency naturally emerge: style, captured by metric SPURTS, and grammar, captured in the form of grammatical outlier penalties. Through extensive experiments and ablation studies on benchmark datasets, we show how these decomposed dimensions of semantics and fluency provide greater system-level insight into captioner differences. Our proposed metrics along with their combination, SMURF, achieve state-of-the-art correlation with human judgment when compared with other rule-based evaluation metrics.