 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMURF: SeMantic and linguistic UndeRstanding Fusion for Caption Evaluation via Typicality Analysis
Paper and Code
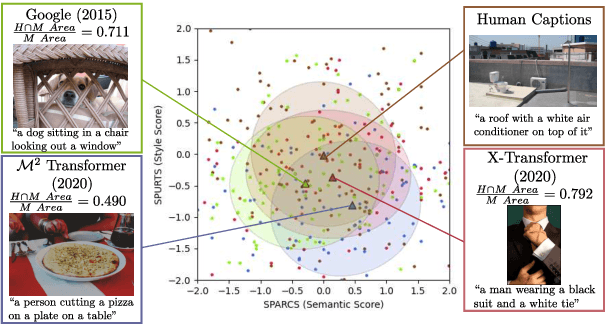



The open-ended nature of visual captioning makes it a challenging area for evaluation. The majority of proposed models rely on specialized training to improve human-correlation, resulting in limited adoption, generalizability, and explainabilty. We introduce "typicality", a new formulation of evaluation rooted in information theory, which is uniquely suited for problems lacking a definite ground truth. Typicality serves as our framework to develop a novel semantic comparison, SPARCS, as well as referenceless fluency evaluation metrics. Over the course of our analysis, two separate dimensions of fluency naturally emerge: style, captured by metric SPURTS, and grammar, captured in the form of grammatical outlier penalties. Through extensive experiments and ablation studies on benchmark datasets, we show how these decomposed dimensions of semantics and fluency provide greater system-level insight into captioner differences. Our proposed metrics along with their combination, SMURF, achieve state-of-the-art correlation with human judgment when compared with other rule-based evaluation metrics.