 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search with Mixed Bio-inspired Learning Rules
Jul 17, 2025Bio-inspired neural networks are attractive for their adversarial robustness, energy frugality, and closer alignment with cortical physiology, yet they often lag behind back-propagation (BP) based models in accuracy and ability to scale. We show that allowing the use of different bio-inspired learning rules in different layers, discovered automatically by a tailored neural-architecture-search (NAS) procedure, bridges this gap. Starting from standard NAS baselines, we enlarge the search space to include bio-inspired learning rules and use NAS to find the best architecture and learning rule to use in each layer. We show that neural networks that use different bio-inspired learning rules for different layers have better accuracy than those that use a single rule across all the layers. The resulting NN that uses a mix of bio-inspired learning rules sets new records for bio-inspired models: 95.16% on CIFAR-10, 76.48% on CIFAR-100, 43.42% on ImageNet16-120, and 60.51% top-1 on ImageNet. In some regimes, they even surpass comparable BP-based networks while retaining their robustness advantages. Our results suggest that layer-wise diversity in learning rules allows better scalability and accuracy, and motivates further research on mixing multiple bio-inspired learning rules in the same network.
You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
Genetic Algorithm enhanced by Deep Reinforcement Learning in parent selection mechanism and mutation : Minimizing makespan in permutation flow shop scheduling problems
Nov 10, 2023This paper introduces a reinforcement learning (RL) approach to address the challenges associated with configuring and optimizing genetic algorithms (GAs) for solving difficult combinatorial or non-linear problems. The proposed RL+GA method was specifically tested on the flow shop scheduling problem (FSP). The hybrid algorithm incorporates neural networks (NN) and uses the off-policy method Q-learning or the on-policy method Sarsa(0) to control two key genetic algorithm (GA) operators: parent selection mechanism and mutation. At each generation, the RL agent's action is determining the selection method, the probability of the parent selection and the probability of the offspring mutation. This allows the RL agent to dynamically adjust the selection and mutation based on its learned policy. The results of the study highlight the effectiveness of the RL+GA approach in improving the performance of the primitive GA. They also demonstrate its ability to learn and adapt from population diversity and solution improvements over time. This adaptability leads to improved scheduling solutions compared to static parameter configurations while maintaining population diversity throughout the evolutionary process.
Skip Connections in Spiking Neural Networks: An Analysis of Their Effect on Network Training
Mar 23, 2023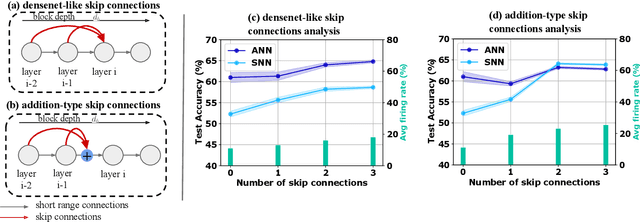

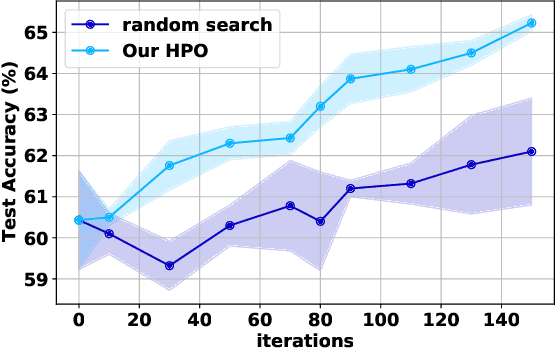
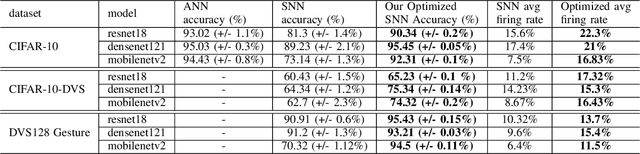
Spiking neural networks (SNNs) have gained attention as a promising alternative to traditional artificial neural networks (ANNs) due to their potential for energy efficiency and their ability to model spiking behavior in biological systems. However, the training of SNNs is still a challenging problem, and new techniques are needed to improve their performance. In this paper, we study the impact of skip connections on SNNs and propose a hyperparameter optimization technique that adapts models from ANN to SNN. We demonstrate that optimizing the position, type, and number of skip connections can significantly improve the accuracy and efficiency of SNNs by enabling faster convergence and increasing information flow through the network. Our results show an average +8% accuracy increase on CIFAR-10-DVS and DVS128 Gesture datasets adaptation of multiple state-of-the-art models.