 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHEHAB RL: Learning to Optimize Fully Homomorphic Encryption Computations
Jan 27, 2026Fully Homomorphic Encryption (FHE) enables computations directly on encrypted data, but its high computational cost remains a significant barrier. Writing efficient FHE code is a complex task requiring cryptographic expertise, and finding the optimal sequence of program transformations is often intractable. In this paper, we propose CHEHAB RL, a novel framework that leverages deep reinforcement learning (RL) to automate FHE code optimization. Instead of relying on predefined heuristics or combinatorial search, our method trains an RL agent to learn an effective policy for applying a sequence of rewriting rules to automatically vectorize scalar FHE code while reducing instruction latency and noise growth. The proposed approach supports the optimization of both structured and unstructured code. To train the agent, we synthesize a diverse dataset of computations using a large language model (LLM). We integrate our proposed approach into the CHEHAB FHE compiler and evaluate it on a suite of benchmarks, comparing its performance against Coyote, a state-of-the-art vectorizing FHE compiler. The results show that our approach generates code that is $5.3\times$ faster in execution, accumulates $2.54\times$ less noise, while the compilation process itself is $27.9\times$ faster than Coyote (geometric means).
A Deep Learning Model for Predicting Transformation Legality
Nov 08, 2025

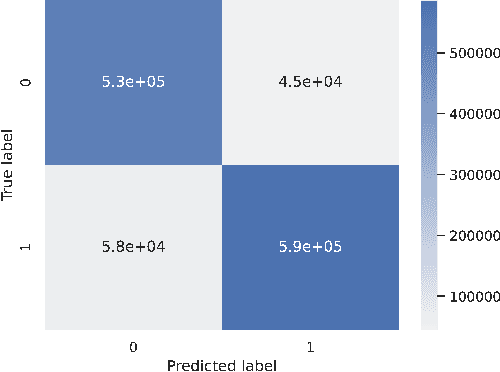
Compilers must check the legality of code transformations to guarantee the correctness of applying a sequence of code transformations to a given code. While such a legality check needs to be precisely computed in general, we can use an approximate legality prediction model in certain cases, such as training a reinforcement learning (RL) agent for schedule prediction. In this paper, we propose an approximate method for legality checks. We propose a novel DL model for predicting the legality of transformations. The model takes the code representation and a list of transformations as input and predicts whether applying those transformations to the code is legal. We implement and evaluate the proposed model, demonstrating its effectiveness. Our evaluation shows an F1 score of 0.91 on a test set of randomly generated programs. To further evaluate the model in a practical scenario, we used the model to replace the legality check used during the training of an RL agent designed for automatic code optimization. We demonstrate that such a replacement enables the agent to train on twice as many steps, resulting in faster training and reducing resource usage by approximately 80\% for CPU and 35\% for RAM. The agent trained using this approach maintains comparable performance, with only a 4\% reduction on benchmarks from the Polybench suite compared to the traditional method.
Neural Architecture Search with Mixed Bio-inspired Learning Rules
Jul 17, 2025Bio-inspired neural networks are attractive for their adversarial robustness, energy frugality, and closer alignment with cortical physiology, yet they often lag behind back-propagation (BP) based models in accuracy and ability to scale. We show that allowing the use of different bio-inspired learning rules in different layers, discovered automatically by a tailored neural-architecture-search (NAS) procedure, bridges this gap. Starting from standard NAS baselines, we enlarge the search space to include bio-inspired learning rules and use NAS to find the best architecture and learning rule to use in each layer. We show that neural networks that use different bio-inspired learning rules for different layers have better accuracy than those that use a single rule across all the layers. The resulting NN that uses a mix of bio-inspired learning rules sets new records for bio-inspired models: 95.16% on CIFAR-10, 76.48% on CIFAR-100, 43.42% on ImageNet16-120, and 60.51% top-1 on ImageNet. In some regimes, they even surpass comparable BP-based networks while retaining their robustness advantages. Our results suggest that layer-wise diversity in learning rules allows better scalability and accuracy, and motivates further research on mixing multiple bio-inspired learning rules in the same network.
Sign-Symmetry Learning Rules are Robust Fine-Tuners
Feb 09, 2025



Backpropagation (BP) has long been the predominant method for training neural networks due to its effectiveness. However, numerous alternative approaches, broadly categorized under feedback alignment, have been proposed, many of which are motivated by the search for biologically plausible learning mechanisms. Despite their theoretical appeal, these methods have consistently underperformed compared to BP, leading to a decline in research interest. In this work, we revisit the role of such methods and explore how they can be integrated into standard neural network training pipelines. Specifically, we propose fine-tuning BP-pre-trained models using Sign-Symmetry learning rules and demonstrate that this approach not only maintains performance parity with BP but also enhances robustness. Through extensive experiments across multiple tasks and benchmarks, we establish the validity of our approach. Our findings introduce a novel perspective on neural network training and open new research directions for leveraging biologically inspired learning rules in deep learning.
Data-efficient Performance Modeling via Pre-training
Jan 24, 2025



Performance models are essential for automatic code optimization, enabling compilers to predict the effects of code transformations on performance and guide search for optimal transformations. Building state-of-the-art performance models with deep learning, however, requires vast labeled datasets of random programs -- an expensive and time-consuming process, stretching over months. This paper introduces a self-supervised pre-training scheme with autoencoders to reduce the need for labeled data. By pre-training on a large dataset of random programs, the autoencoder learns representations of code and transformations, which are then used to embed programs for the performance model. Implemented in the Tiramisu autoscheduler, our approach improves model accuracy with less data. For example, to achieve a MAPE of 20.72%, the original model requires 18 million data points, whereas our method achieves a similar MAPE of 22.44% with only 3.6 million data points, reducing data requirements by 5x.
Exploring the Knowledge Mismatch Hypothesis: Hallucination Propensity in Small Models Fine-tuned on Data from Larger Models
Oct 31, 2024


Recently, there has been an explosion of large language models created through fine-tuning with data from larger models. These small models able to produce outputs that appear qualitatively similar to significantly larger models. However, one of the key limitations that have been observed with these models is their propensity to hallucinate significantly more often than larger models. In particular, they have been observed to generate coherent outputs that involve factually incorrect information and spread misinformation, toxicity, and stereotypes. There are many potential causes of hallucination, of which, one hypothesis is that fine-tuning a model on data produced by a larger model leads to a knowledge mismatch which contributes to hallucination. In particular, it is hypothesized that there is a mismatch between the knowledge that is fed to the model to fine-tune it and the knowledge that is already present in the graph. Fine-tuning the model on data that has such mismatch could contribute to an increased propensity to hallucinate. We show that on an unseen test set, a smaller model fine-tuned on data generated from a larger model produced more wrong answers when compared to models fine-tuned on data created by the small model, which confirms the hypothesis.
Combining Neural Architecture Search and Automatic Code Optimization: A Survey
Aug 07, 2024Deep Learning models have experienced exponential growth in complexity and resource demands in recent years. Accelerating these models for efficient execution on resource-constrained devices has become more crucial than ever. Two notable techniques employed to achieve this goal are Hardware-aware Neural Architecture Search (HW-NAS) and Automatic Code Optimization (ACO). HW-NAS automatically designs accurate yet hardware-friendly neural networks, while ACO involves searching for the best compiler optimizations to apply on neural networks for efficient mapping and inference on the target hardware. This survey explores recent works that combine these two techniques within a single framework. We present the fundamental principles of both domains and demonstrate their sub-optimality when performed independently. We then investigate their integration into a joint optimization process that we call Hardware Aware-Neural Architecture and Compiler Optimizations co-Search (NACOS).
Curriculum Learning for Small Code Language Models
Jul 14, 2024Code language models have emerged as useful tools for various programming tasks, yet they often struggle when it comes to complex ones. In this paper, we explore the potential of curriculum learning in enhancing the performance of these models. While prior research has suggested that curriculum learning does not necessarily help in improving the performance of language models, our results surprisingly show that this may not be the case for code language models. We demonstrate that a well-designed curriculum learning approach significantly improves the accuracy of small decoder-only code language models on the task of code execution, while its effect on code completion is less significant. To explore the potential of curriculum learning, we train multiple GPT models with 1 million parameters each to predict the next token and evaluate them on code completion and execution tasks. Our contributions include proposing a novel code difficulty assessment metric by combining software code measures, investigating the effectiveness of Curriculum Learning for code language models, and introducing a Novel Curriculum Learning schedule that enhances the performance of small decoder-only language models in code execution tasks. The results of this paper open the door for more research on the use of curriculum learning for code language models.
LOOPer: A Learned Automatic Code Optimizer For Polyhedral Compilers
Mar 22, 2024



While polyhedral compilers have shown success in implementing advanced code transformations, they still have challenges in selecting the most profitable transformations that lead to the best speedups. This has motivated the use of machine learning to build cost models to guide the search for polyhedral optimizations. State-of-the-art polyhedral compilers have demonstrated a viable proof-of-concept of this approach. While such a proof-of-concept has shown promise, it still has significant limitations. State-of-the-art polyhedral compilers that use a deep-learning cost model only support a small subset of affine transformations, limiting their ability to apply complex code transformations. They also only support simple programs that have a single loop nest and a rectangular iteration domain, limiting their applicability to many programs. These limitations significantly impact the generality of such compilers and autoschedulers and put into question the whole approach. In this paper, we introduce LOOPer, the first polyhedral autoscheduler that uses a deep-learning based cost model and covers a large set of affine transformations and programs. It supports the exploration of a large set of affine transformations, allowing the application of complex sequences of polyhedral transformations. It also supports the optimization of programs with multiple loop nests and with rectangular and non-rectangular iteration domains, allowing the optimization of an extensive set of programs. We implement and evaluate LOOPer and show that it achieves speedups over the state-of-the-art. On the Polybench benchmark, LOOPer achieves a geometric mean speedup of 1.59x over Tiramisu. LOOPer also achieves competitive speedups with a geometric mean speedup of 1.34x over Pluto, a state-of-the-art polyhedral compiler that does not use a machine-learning based cost model.
Leveraging High-Resolution Features for Improved Deep Hashing-based Image Retrieval
Mar 20, 2024


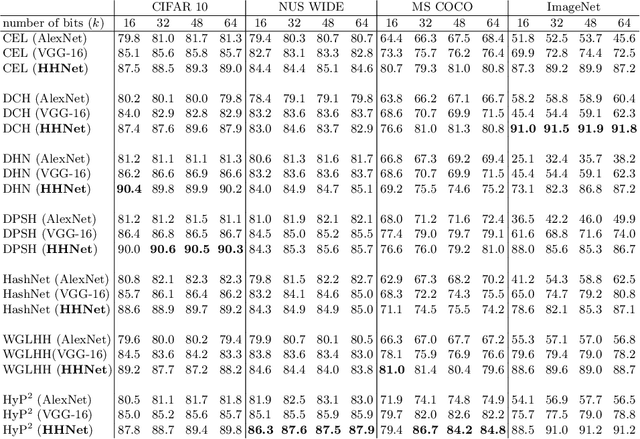
Deep hashing techniques have emerged as the predominant approach for efficient image retrieval. Traditionally, these methods utilize pre-trained convolutional neural networks (CNNs) such as AlexNet and VGG-16 as feature extractors. However, the increasing complexity of datasets poses challenges for these backbone architectures in capturing meaningful features essential for effective image retrieval. In this study, we explore the efficacy of employing high-resolution features learned through state-of-the-art techniques for image retrieval tasks. Specifically, we propose a novel methodology that utilizes High-Resolution Networks (HRNets) as the backbone for the deep hashing task, termed High-Resolution Hashing Network (HHNet). Our approach demonstrates superior performance compared to existing methods across all tested benchmark datasets, including CIFAR-10, NUS-WIDE, MS COCO, and ImageNet. This performance improvement is more pronounced for complex datasets, which highlights the need to learn high-resolution features for intricate image retrieval tasks. Furthermore, we conduct a comprehensive analysis of different HRNet configurations and provide insights into the optimal architecture for the deep hashing task