 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAskIt: Unified Programming Interface for Programming with Large Language Models
Aug 29, 2023



In the evolving landscape of software development, Large Language Models (LLMs) exhibit a unique phenomenon known as emergent abilities, demonstrating adeptness across numerous tasks, from text summarization to code generation. While these abilities open up novel avenues in software design and crafting, their incorporation presents substantial challenges. Developers grapple with decisions surrounding the direct embedding of LLMs within applications versus employing them for code generation. Moreover, effective prompt design becomes a critical concern, given the necessity of data extraction from natural language outputs. To address these intricacies, this paper introduces AskIt, a domain-specific language (DSL) specifically designed for LLMs. AskIt simplifies LLM integration, offering type-guided output control, template-based function definitions, and a unified interface that diminishes the distinction between LLM-based code generation and application integration. Furthermore, through Programming by Example (PBE), AskIt harnesses the power of few-shot learning at the programming language level. Our evaluations underscore AskIt's potency. Across 50 tasks, AskIt generated concise prompts for the given tasks, achieving a 16.14% reduction in prompt length relative to benchmarks. Additionally, by enabling the transition from direct LLM application usage to function generation, AskIt achieved significant speedups, as observed in our GSM8K benchmark experiments. Through these advancements, AskIt streamlines the integration of LLMs in software development, offering a more efficient, versatile approach for leveraging emergent abilities. The implementations of AskIt in TypeScript and Python are available at https://github.com/katsumiok/ts-askit and https://github.com/katsumiok/pyaskit, respectively.
A Deep Learning Based Cost Model for Automatic Code Optimization
Apr 11, 2021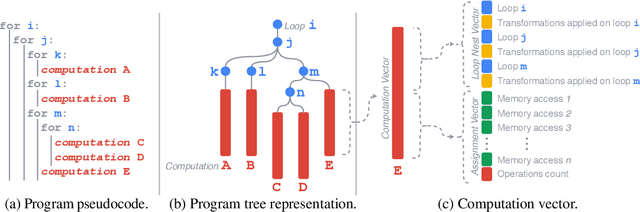
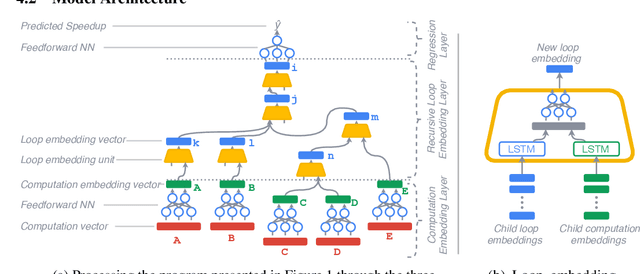
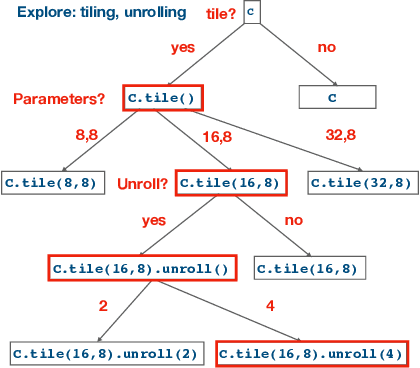
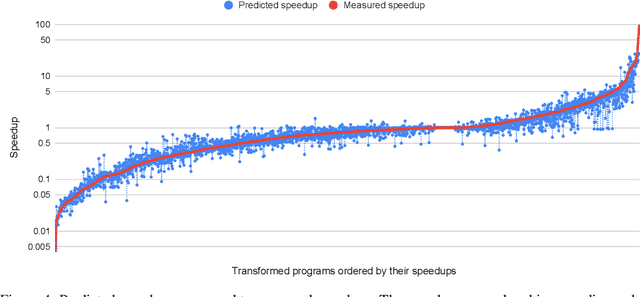
Enabling compilers to automatically optimize code has been a longstanding goal for the compiler community. Efficiently solving this problem requires using precise cost models. These models predict whether applying a sequence of code transformations reduces the execution time of the program. Building an analytical cost model to do so is hard in modern x86 architectures due to the complexity of the microarchitecture. In this paper, we present a novel deep learning based cost model for automatic code optimization. This model was integrated in a search method and implemented in the Tiramisu compiler to select the best code transformations. The input of the proposed model is a set of simple features representing the unoptimized code and a sequence of code transformations. The model predicts the speedup expected when the code transformations are applied. Unlike previous models, the proposed one works on full programs and does not rely on any heavy feature engineering. The proposed model has only 16% of mean absolute percentage error in predicting speedups on full programs. The proposed model enables Tiramisu to automatically find code transformations that match or are better than state-of-the-art compilers without requiring the same level of heavy feature engineering required by those compilers.
TIRAMISU: A Polyhedral Compiler for Dense and Sparse Deep Learning
May 07, 2020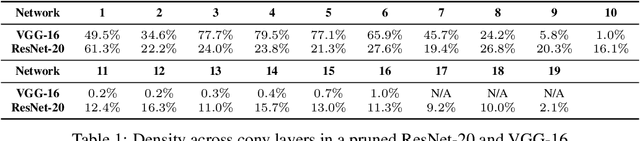
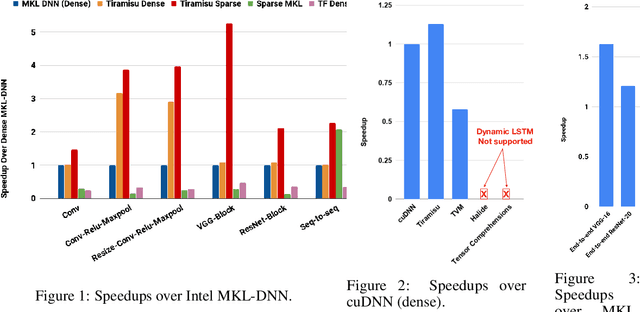
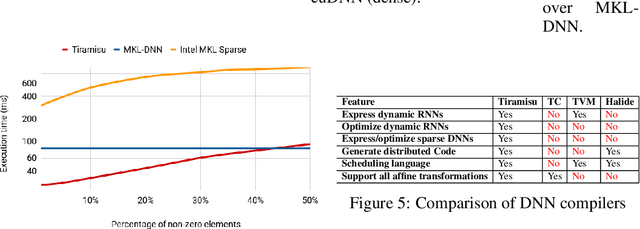
In this paper, we demonstrate a compiler that can optimize sparse and recurrent neural networks, both of which are currently outside of the scope of existing neural network compilers (sparse neural networks here stand for networks that can be accelerated with sparse tensor algebra techniques). Our demonstration includes a mapping of sparse and recurrent neural networks to the polyhedral model along with an implementation of our approach in TIRAMISU, our state-of-the-art polyhedral compiler. We evaluate our approach on a set of deep learning benchmarks and compare our results with hand-optimized industrial libraries. Our results show that our approach at least matches Intel MKL-DNN and in some cases outperforms it by 5x (on multicore-CPUs).
Tiramisu: A Code Optimization Framework for High Performance Systems
Sep 26, 2018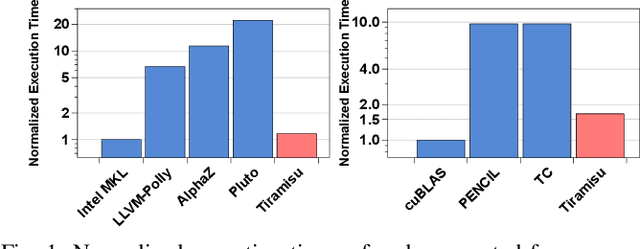


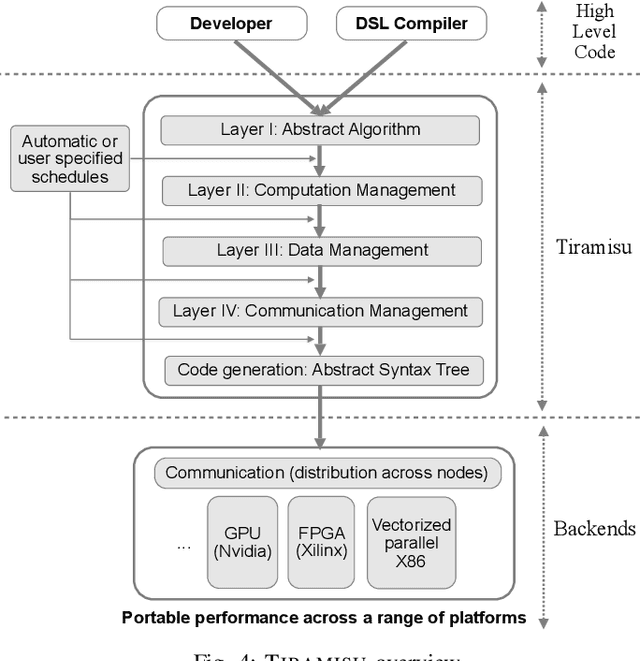
This paper introduces Tiramisu, a polyhedral framework designed to generate high performance code for multiple platforms including multicores, GPUs, and distributed machines. Tiramisu introduces a scheduling language with novel extensions to explicitly manage the complexities that arise when targeting these systems. The extensions include explicit communication, synchronization, and mapping buffers to different memory hierarchies. Tiramisu relies on a flexible representation based on the polyhedral model and explicitly uses a well-defined four-level IR that allows full separation between the algorithms, loop transformations, data-layouts, and communication. This separation simplifies targeting multiple hardware architectures with the same algorithm. We evaluate Tiramisu by writing a set of image processing and stencil benchmarks and compare it with state-of-the-art compilers. We show that Tiramisu matches or outperforms existing compilers on different hardware architectures, including multicore CPUs, GPUs, and distributed machines.
Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks
Aug 21, 2018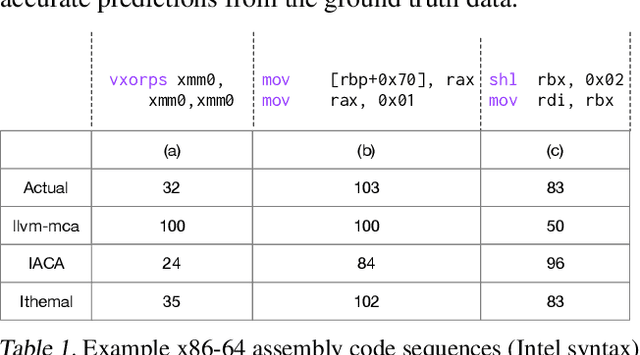
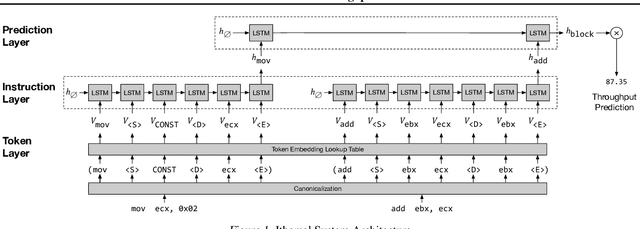


Statically estimating the number of processor clock cycles it takes to execute a basic block of assembly instructions in steady state (throughput) is important for compiler backend optimizations such as register allocation, instruction selection and instruction scheduling. This is complicated specially in modern x86-64 Complex Instruction Set Computer (CISC) machines with sophisticated processor microarchitectures. Traditionally, compiler writers invest time experimenting and referring to processor manuals to analytically model modern processors with incomplete specifications. This is tedious, error prone and should be done for each processor generation. We present Ithemal, the first automatically learnt estimator to statically predict throughput of a set of basic block instructions using machine learning. Ithemal uses a novel Directed Acyclic Graph-Recurrent Neural Network (DAG-RNN) based data-driven approach for throughput estimation. We show that Ithemal is accurate than state-of-the-art hand written tools used in compiler backends and static machine code analyzers. In particular, our model has a worst case average error of 10.53% on actual throughput values when compared to best case average errors of 19.57% for the LLVM scheduler (llvm-mca) and 22.51% for IACA, Intel's machine code analyzer when compared on three different microarchitectures, while predicting throughput values at a faster rate than aforementioned tools. We also show that Ithemal is portable, learning throughput estimation for Intel Nehalem, Haswell and Skylake microarchitectures without requiring changes to its structure.
The Three Pillars of Machine Programming
May 08, 2018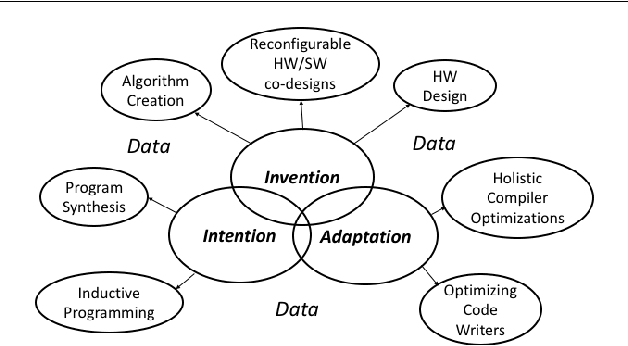
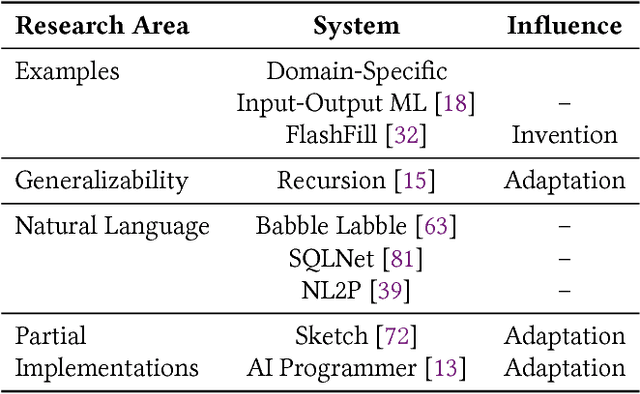
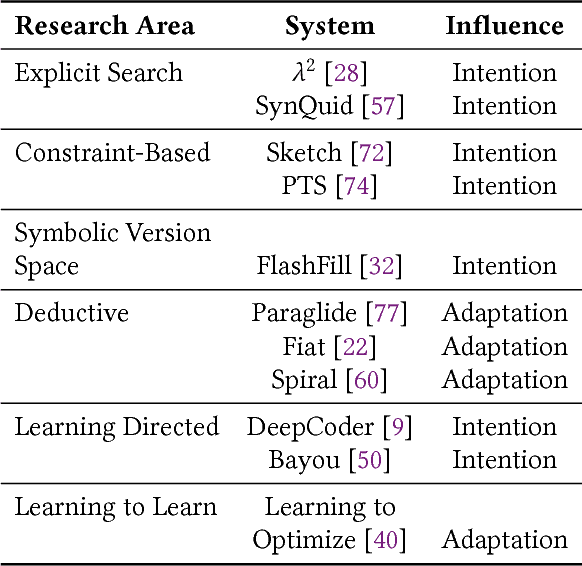
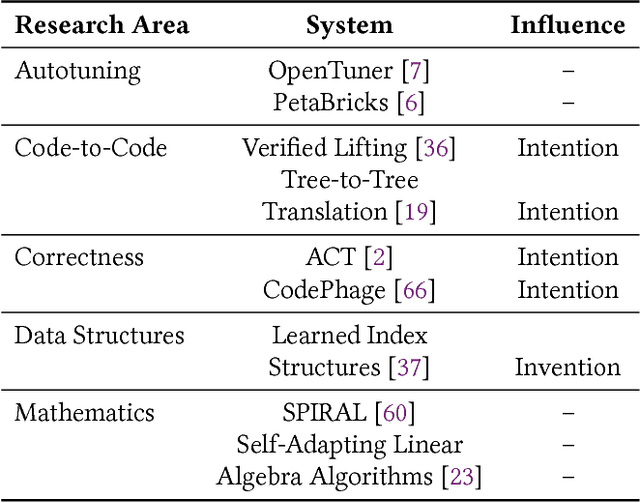
In this position paper, we describe our vision of the future of machine programming through a categorical examination of three pillars of research. Those pillars are: (i) intention, (ii) invention, and(iii) adaptation. Intention emphasizes advancements in the human-to-computer and computer-to-machine-learning interfaces. Invention emphasizes the creation or refinement of algorithms or core hardware and software building blocks through machine learning (ML). Adaptation emphasizes advances in the use of ML-based constructs to autonomously evolve software.