Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIRAMISU: A Polyhedral Compiler for Dense and Sparse Deep Learning
Paper and Code
May 07, 2020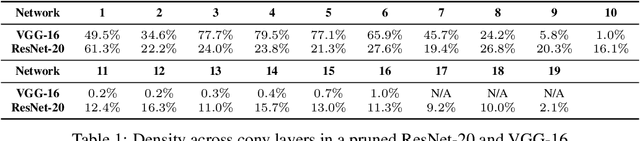
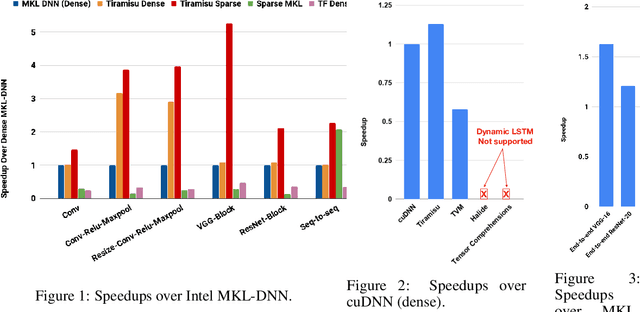
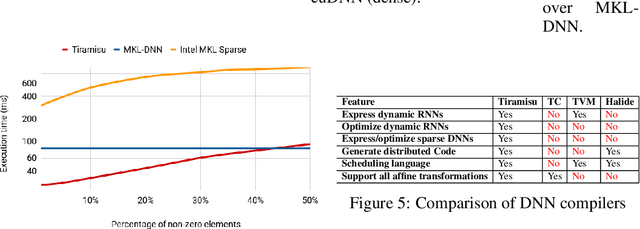
In this paper, we demonstrate a compiler that can optimize sparse and recurrent neural networks, both of which are currently outside of the scope of existing neural network compilers (sparse neural networks here stand for networks that can be accelerated with sparse tensor algebra techniques). Our demonstration includes a mapping of sparse and recurrent neural networks to the polyhedral model along with an implementation of our approach in TIRAMISU, our state-of-the-art polyhedral compiler. We evaluate our approach on a set of deep learning benchmarks and compare our results with hand-optimized industrial libraries. Our results show that our approach at least matches Intel MKL-DNN and in some cases outperforms it by 5x (on multicore-CPUs).
View paper on