 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
Proceedings of the NeurIPS 2021 Workshop on Machine Learning for the Developing World: Global Challenges
Jan 10, 2023These are the proceedings of the 5th workshop on Machine Learning for the Developing World (ML4D), held as part of the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) on December 14th, 2021.
EduPal leaves no professor behind: Supporting faculty via a peer-powered recommender system
Apr 20, 2021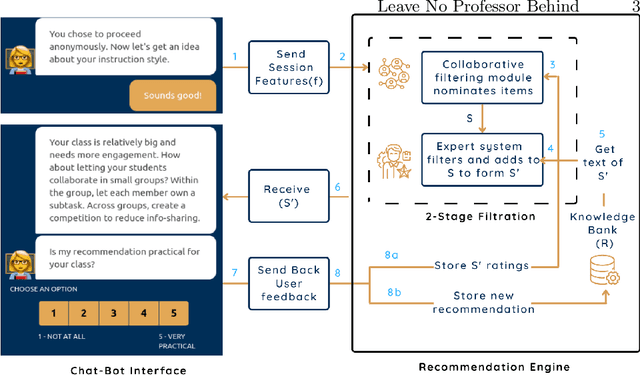
The swift transitions in higher education after the COVID-19 outbreak identified a gap in the pedagogical support available to faculty. We propose a smart, knowledge-based chatbot that addresses issues of knowledge distillation and provides faculty with personalized recommendations. Our collaborative system crowdsources useful pedagogical practices and continuously filters recommendations based on theory and user feedback, thus enhancing the experiences of subsequent peers. We build a prototype for our local STEM faculty as a proof concept and receive favorable feedback that encourages us to extend our development and outreach, especially to underresourced faculty.
Proceedings of the NeurIPS 2020 Workshop on Machine Learning for the Developing World: Improving Resilience
Jan 12, 2021These are the proceedings of the 4th workshop on Machine Learning for the Developing World (ML4D), held as part of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS) on Saturday, December 12th 2020.