 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Spatial Accelerator Architectures with Tiled Matrix-Matrix Multiplication
Paper and Code
Jun 19, 2021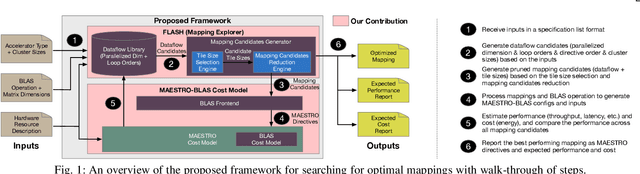
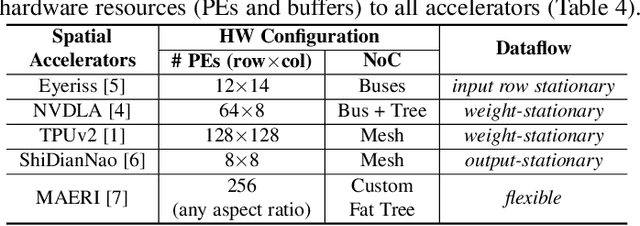
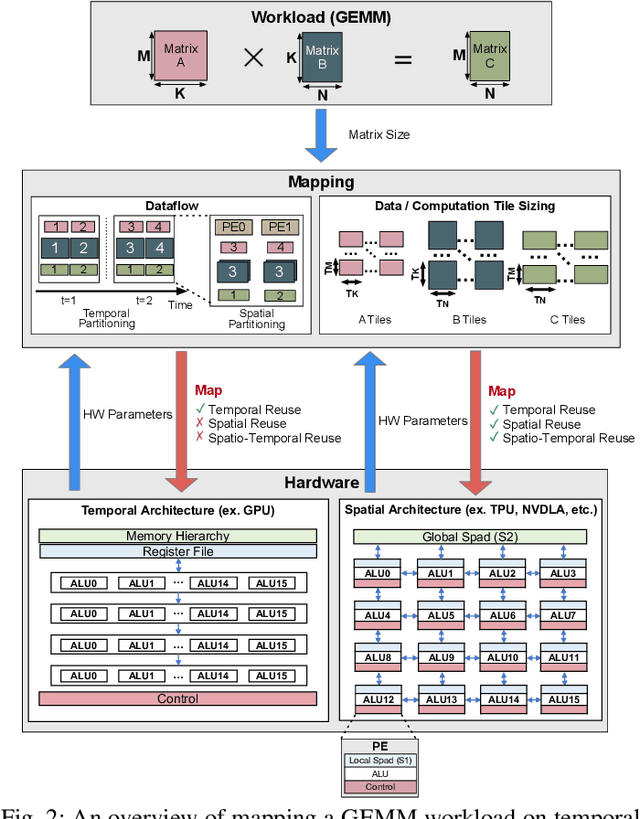

There is a growing interest in custom spatial accelerators for machine learning applications. These accelerators employ a spatial array of processing elements (PEs) interacting via custom buffer hierarchies and networks-on-chip. The efficiency of these accelerators comes from employing optimized dataflow (i.e., spatial/temporal partitioning of data across the PEs and fine-grained scheduling) strategies to optimize data reuse. The focus of this work is to evaluate these accelerator architectures using a tiled general matrix-matrix multiplication (GEMM) kernel. To do so, we develop a framework that finds optimized mappings (dataflow and tile sizes) for a tiled GEMM for a given spatial accelerator and workload combination, leveraging an analytical cost model for runtime and energy. Our evaluations over five spatial accelerators demonstrate that the tiled GEMM mappings systematically generated by our framework achieve high performance on various GEMM workloads and accelerators.