 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Breath Phase and Continuous Adventitious Sound Detection in Lung and Tracheal Sound Using Mixed Set Training and Domain Adaptation
Jul 09, 2021
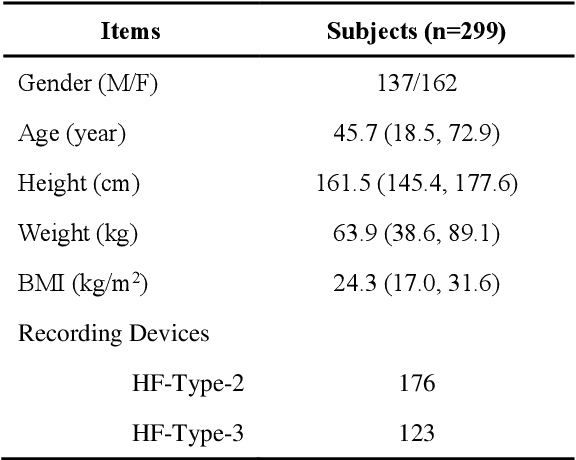

Previously, we established a lung sound database, HF_Lung_V2 and proposed convolutional bidirectional gated recurrent unit (CNN-BiGRU) models with adequate ability for inhalation, exhalation, continuous adventitious sound (CAS), and discontinuous adventitious sound detection in the lung sound. In this study, we proceeded to build a tracheal sound database, HF_Tracheal_V1, containing 11107 of 15-second tracheal sound recordings, 23087 inhalation labels, 16728 exhalation labels, and 6874 CAS labels. The tracheal sound in HF_Tracheal_V1 and the lung sound in HF_Lung_V2 were either combined or used alone to train the CNN-BiGRU models for respective lung and tracheal sound analysis. Different training strategies were investigated and compared: (1) using full training (training from scratch) to train the lung sound models using lung sound alone and train the tracheal sound models using tracheal sound alone, (2) using a mixed set that contains both the lung and tracheal sound to train the models, and (3) using domain adaptation that finetuned the pre-trained lung sound models with the tracheal sound data and vice versa. Results showed that the models trained only by lung sound performed poorly in the tracheal sound analysis and vice versa. However, the mixed set training and domain adaptation can improve the performance of exhalation and CAS detection in the lung sound, and inhalation, exhalation, and CAS detection in the tracheal sound compared to positive controls (lung models trained only by lung sound and vice versa). Especially, a model derived from the mixed set training prevails in the situation of killing two birds with one stone.
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Mar 03, 2021


A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.