 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced accent/dialect identification and accentedness assessment with multi-embedding models and automatic speech recognition
Oct 17, 2023Accurately classifying accents and assessing accentedness in non-native speakers are both challenging tasks due to the complexity and diversity of accent and dialect variations. In this study, embeddings from advanced pre-trained language identification (LID) and speaker identification (SID) models are leveraged to improve the accuracy of accent classification and non-native accentedness assessment. Findings demonstrate that employing pre-trained LID and SID models effectively encodes accent/dialect information in speech. Furthermore, the LID and SID encoded accent information complement an end-to-end accent identification (AID) model trained from scratch. By incorporating all three embeddings, the proposed multi-embedding AID system achieves superior accuracy in accent identification. Next, we investigate leveraging automatic speech recognition (ASR) and accent identification models to explore accentedness estimation. The ASR model is an end-to-end connectionist temporal classification (CTC) model trained exclusively with en-US utterances. The ASR error rate and en-US output of the AID model are leveraged as objective accentedness scores. Evaluation results demonstrate a strong correlation between the scores estimated by the two models. Additionally, a robust correlation between the objective accentedness scores and subjective scores based on human perception is demonstrated, providing evidence for the reliability and validity of utilizing AID-based and ASR-based systems for accentedness assessment in non-native speech.
Domain Expansion in DNN-based Acoustic Models for Robust Speech Recognition
Oct 01, 2019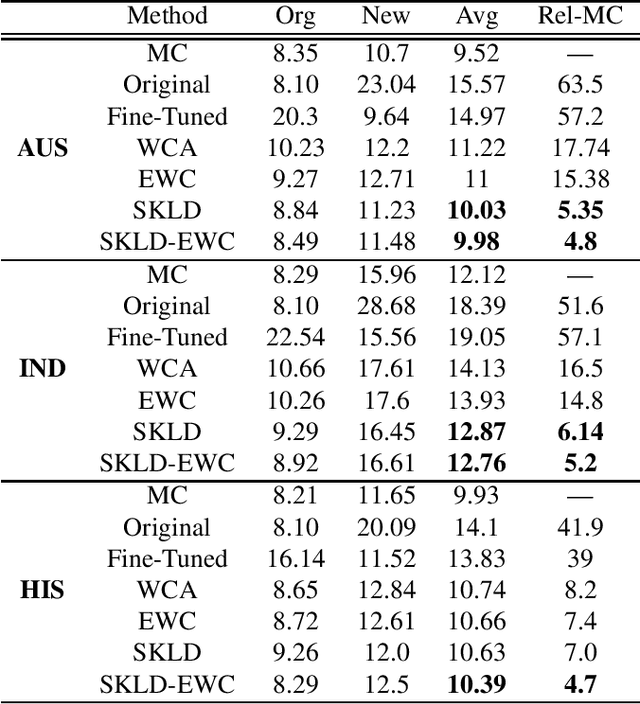

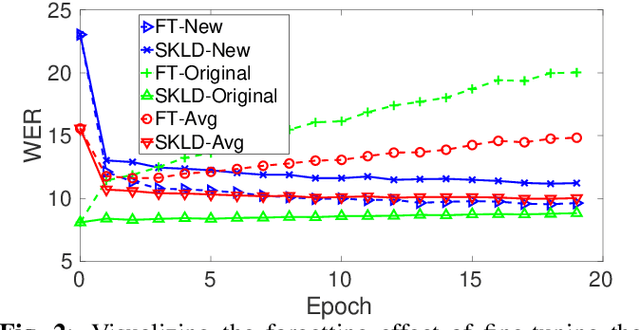
Training acoustic models with sequentially incoming data -- while both leveraging new data and avoiding the forgetting effect-- is an essential obstacle to achieving human intelligence level in speech recognition. An obvious approach to leverage data from a new domain (e.g., new accented speech) is to first generate a comprehensive dataset of all domains, by combining all available data, and then use this dataset to retrain the acoustic models. However, as the amount of training data grows, storing and retraining on such a large-scale dataset becomes practically impossible. To deal with this problem, in this study, we study several domain expansion techniques which exploit only the data of the new domain to build a stronger model for all domains. These techniques are aimed at learning the new domain with a minimal forgetting effect (i.e., they maintain original model performance). These techniques modify the adaptation procedure by imposing new constraints including (1) weight constraint adaptation (WCA): keeping the model parameters close to the original model parameters; (2) elastic weight consolidation (EWC): slowing down training for parameters that are important for previously established domains; (3) soft KL-divergence (SKLD): restricting the KL-divergence between the original and the adapted model output distributions; and (4) hybrid SKLD-EWC: incorporating both SKLD and EWC constraints. We evaluate these techniques in an accent adaptation task in which we adapt a deep neural network (DNN) acoustic model trained with native English to three different English accents: Australian, Hispanic, and Indian. The experimental results show that SKLD significantly outperforms EWC, and EWC works better than WCA. The hybrid SKLD-EWC technique results in the best overall performance.