 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Need Variations in Speech Synthesis: Sub-center Modelling for Speaker Embeddings
Paper and Code
Jul 05, 2024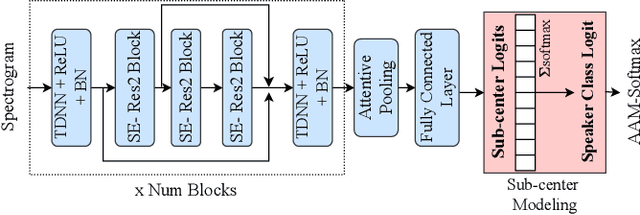
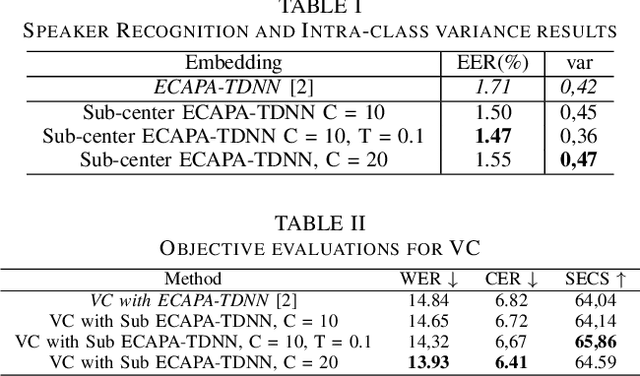
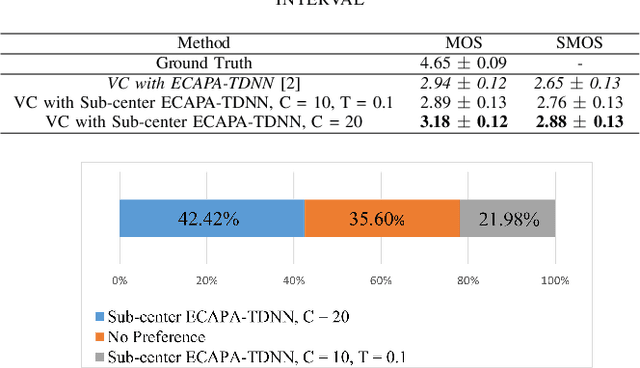
In speech synthesis, modeling of rich emotions and prosodic variations present in human voice are crucial to synthesize natural speech. Although speaker embeddings have been widely used in personalized speech synthesis as conditioning inputs, they are designed to lose variation to optimize speaker recognition accuracy. Thus, they are suboptimal for speech synthesis in terms of modeling the rich variations at the output speech distribution. In this work, we propose a novel speaker embedding network which utilizes multiple class centers in the speaker classification training rather than a single class center as traditional embeddings. The proposed approach introduces variations in the speaker embedding while retaining the speaker recognition performance since model does not have to map all of the utterances of a speaker into a single class center. We apply our proposed embedding in voice conversion task and show that our method provides better naturalness and prosody in synthesized speech.