 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel Voice Trigger Detection Based on Transform-average-concatenate
Sep 27, 2023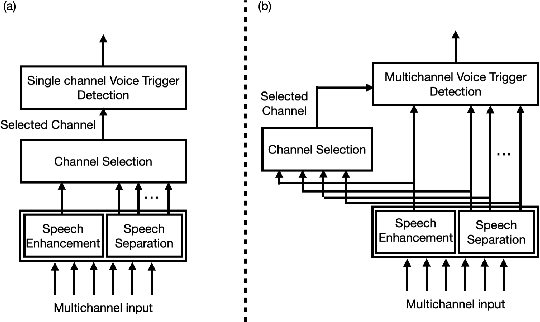
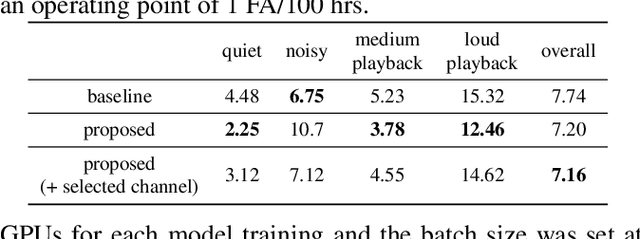
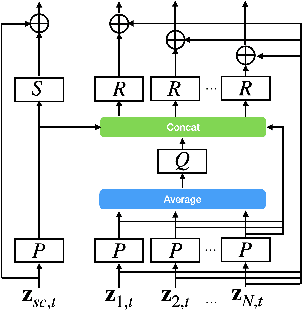
Voice triggering (VT) enables users to activate their devices by just speaking a trigger phrase. A front-end system is typically used to perform speech enhancement and/or separation, and produces multiple enhanced and/or separated signals. Since conventional VT systems take only single-channel audio as input, channel selection is performed. A drawback of this approach is that unselected channels are discarded, even if the discarded channels could contain useful information for VT. In this work, we propose multichannel acoustic models for VT, where the multichannel output from the frond-end is fed directly into a VT model. We adopt a transform-average-concatenate (TAC) block and modify the TAC block by incorporating the channel from the conventional channel selection so that the model can attend to a target speaker when multiple speakers are present. The proposed approach achieves up to 30% reduction in the false rejection rate compared to the baseline channel selection approach.
Does Single-channel Speech Enhancement Improve Keyword Spotting Accuracy? A Case Study
Sep 27, 2023


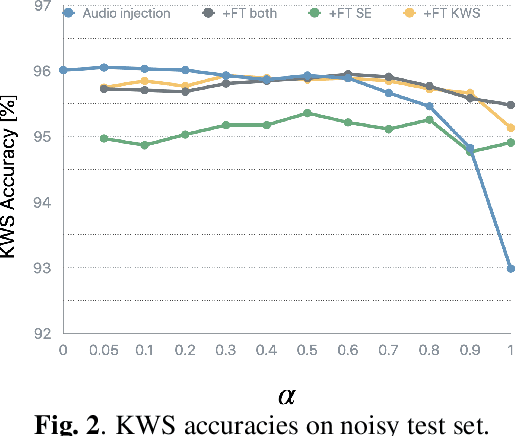
Noise robustness is a key aspect of successful speech applications. Speech enhancement (SE) has been investigated to improve automatic speech recognition accuracy; however, its effectiveness for keyword spotting (KWS) is still under-investigated. In this paper, we conduct a comprehensive study on single-channel speech enhancement for keyword spotting on the Google Speech Command (GSC) dataset. To investigate robustness to noise, the GSC dataset is augmented with noise signals from the WSJ0 Hipster Ambient Mixtures (WHAM!) noise dataset. Our investigation includes not only applying SE before KWS but also performing joint training of the SE frontend and KWS backend models. Moreover, we explore audio injection, a common approach to reduce distortions by using a weighted average of the enhanced and original signals. Audio injection is then further optimized by using another model that predicts the weight for each utterance. Our investigation reveals that SE can improve KWS accuracy on noisy speech when the backend model is trained on clean speech; however, despite our extensive exploration, it is difficult to improve the KWS accuracy with SE when the backend is trained on noisy speech.