 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Assessment of Self-Supervised Speech Models using Rank
Paper and Code



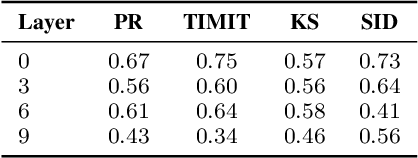
This study explores using embedding rank as an unsupervised evaluation metric for general-purpose speech encoders trained via self-supervised learning (SSL). Traditionally, assessing the performance of these encoders is resource-intensive and requires labeled data from the downstream tasks. Inspired by the vision domain, where embedding rank has shown promise for evaluating image encoders without tuning on labeled downstream data, this work examines its applicability in the speech domain, considering the temporal nature of the signals. The findings indicate rank correlates with downstream performance within encoder layers across various downstream tasks and for in- and out-of-domain scenarios. However, rank does not reliably predict the best-performing layer for specific downstream tasks, as lower-ranked layers can outperform higher-ranked ones. Despite this limitation, the results suggest that embedding rank can be a valuable tool for monitoring training progress in SSL speech models, offering a less resource-demanding alternative to traditional evaluation methods.