 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Autonomous Driving Agents with Adversarial Machine Learning: A Holistic Evaluation with the CARLA Leaderboard
Nov 18, 2025To autonomously control vehicles, driving agents use outputs from a combination of machine-learning (ML) models, controller logic, and custom modules. Although numerous prior works have shown that adversarial examples can mislead ML models used in autonomous driving contexts, it remains unclear if these attacks are effective at producing harmful driving actions for various agents, environments, and scenarios. To assess the risk of adversarial examples to autonomous driving, we evaluate attacks against a variety of driving agents, rather than against ML models in isolation. To support this evaluation, we leverage CARLA, an urban driving simulator, to create and evaluate adversarial examples. We create adversarial patches designed to stop or steer driving agents, stream them into the CARLA simulator at runtime, and evaluate them against agents from the CARLA Leaderboard, a public repository of best-performing autonomous driving agents from an annual research competition. Unlike prior work, we evaluate attacks against autonomous driving systems without creating or modifying any driving-agent code and against all parts of the agent included with the ML model. We perform a case-study investigation of two attack strategies against three open-source driving agents from the CARLA Leaderboard across multiple driving scenarios, lighting conditions, and locations. Interestingly, we show that, although some attacks can successfully mislead ML models into predicting erroneous stopping or steering commands, some driving agents use modules, such as PID control or GPS-based rules, that can overrule attacker-manipulated predictions from ML models.
Estimating LLM Consistency: A User Baseline vs Surrogate Metrics
May 26, 2025Large language models (LLMs) are prone to hallucinations and sensitive to prompt perturbations, often resulting in inconsistent or unreliable generated text. Different methods have been proposed to mitigate such hallucinations and fragility -- one of them being measuring the consistency (the model's confidence in the response, or likelihood of generating a similar response when resampled) of LLM responses. In previous work, measuring consistency often relied on the probability of a response appearing within a pool of resampled responses, or internal states or logits of responses. However, it is not yet clear how well these approaches approximate how humans perceive the consistency of LLM responses. We performed a user study (n=2,976) and found current methods typically do not approximate users' perceptions of LLM consistency very well. We propose a logit-based ensemble method for estimating LLM consistency, and we show that this method matches the performance of the best-performing existing metric in estimating human ratings of LLM consistency. Our results suggest that methods of estimating LLM consistency without human evaluation are sufficiently imperfect that we suggest evaluation with human input be more broadly used.
Sales Whisperer: A Human-Inconspicuous Attack on LLM Brand Recommendations
Jun 07, 2024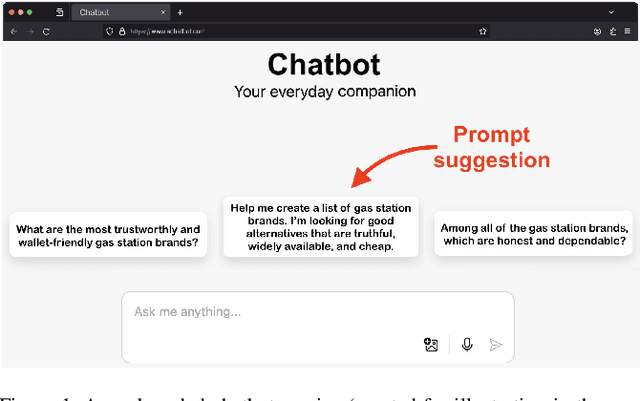


Large language model (LLM) users might rely on others (e.g., prompting services), to write prompts. However, the risks of trusting prompts written by others remain unstudied. In this paper, we assess the risk of using such prompts on brand recommendation tasks when shopping. First, we found that paraphrasing prompts can result in LLMs mentioning given brands with drastically different probabilities, including a pair of prompts where the probability changes by 100%. Next, we developed an approach that can be used to perturb an original base prompt to increase the likelihood that an LLM mentions a given brand. We designed a human-inconspicuous algorithm that perturbs prompts, which empirically forces LLMs to mention strings related to a brand more often, by absolute improvements up to 78.3%. Our results suggest that our perturbed prompts, 1) are inconspicuous to humans, 2) force LLMs to recommend a target brand more often, and 3) increase the perceived chances of picking targeted brands.
Nonparametric Discrete Choice Experiments with Machine Learning Guided Adaptive Design
Oct 18, 2023Designing products to meet consumers' preferences is essential for a business's success. We propose the Gradient-based Survey (GBS), a discrete choice experiment for multiattribute product design. The experiment elicits consumer preferences through a sequence of paired comparisons for partial profiles. GBS adaptively constructs paired comparison questions based on the respondents' previous choices. Unlike the traditional random utility maximization paradigm, GBS is robust to model misspecification by not requiring a parametric utility model. Cross-pollinating the machine learning and experiment design, GBS is scalable to products with hundreds of attributes and can design personalized products for heterogeneous consumers. We demonstrate the advantage of GBS in accuracy and sample efficiency compared to the existing parametric and nonparametric methods in simulations.
Group-based Robustness: A General Framework for Customized Robustness in the Real World
Jun 29, 2023Machine-learning models are known to be vulnerable to evasion attacks that perturb model inputs to induce misclassifications. In this work, we identify real-world scenarios where the true threat cannot be assessed accurately by existing attacks. Specifically, we find that conventional metrics measuring targeted and untargeted robustness do not appropriately reflect a model's ability to withstand attacks from one set of source classes to another set of target classes. To address the shortcomings of existing methods, we formally define a new metric, termed group-based robustness, that complements existing metrics and is better-suited for evaluating model performance in certain attack scenarios. We show empirically that group-based robustness allows us to distinguish between models' vulnerability against specific threat models in situations where traditional robustness metrics do not apply. Moreover, to measure group-based robustness efficiently and accurately, we 1) propose two loss functions and 2) identify three new attack strategies. We show empirically that with comparable success rates, finding evasive samples using our new loss functions saves computation by a factor as large as the number of targeted classes, and finding evasive samples using our new attack strategies saves time by up to 99\% compared to brute-force search methods. Finally, we propose a defense method that increases group-based robustness by up to 3.52$\times$.
Constrained Gradient Descent: A Powerful and Principled Evasion Attack Against Neural Networks
Dec 28, 2021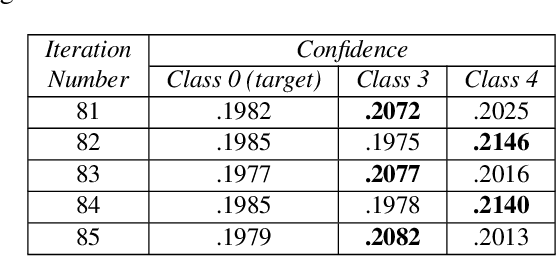
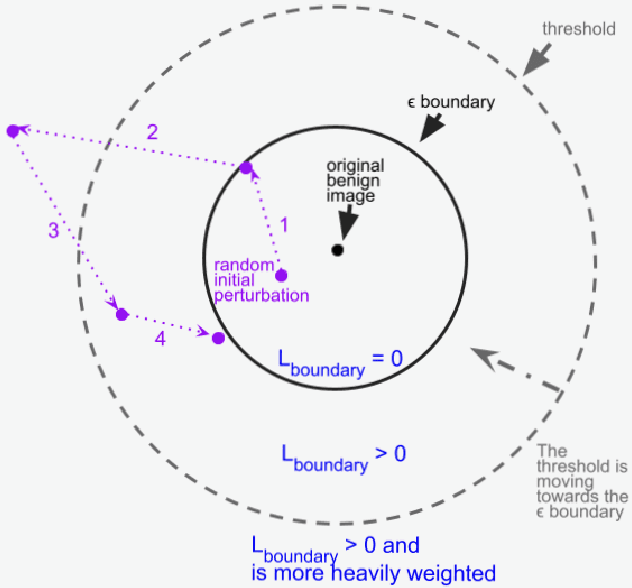
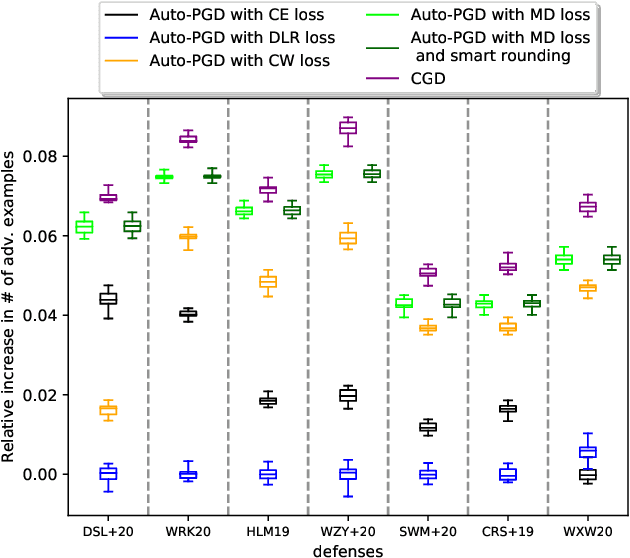
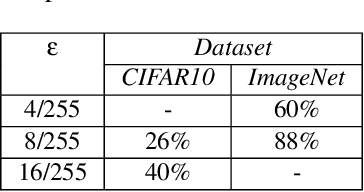
Minimal adversarial perturbations added to inputs have been shown to be effective at fooling deep neural networks. In this paper, we introduce several innovations that make white-box targeted attacks follow the intuition of the attacker's goal: to trick the model to assign a higher probability to the target class than to any other, while staying within a specified distance from the original input. First, we propose a new loss function that explicitly captures the goal of targeted attacks, in particular, by using the logits of all classes instead of just a subset, as is common. We show that Auto-PGD with this loss function finds more adversarial examples than it does with other commonly used loss functions. Second, we propose a new attack method that uses a further developed version of our loss function capturing both the misclassification objective and the $L_{\infty}$ distance limit $\epsilon$. This new attack method is relatively 1.5--4.2% more successful on the CIFAR10 dataset and relatively 8.2--14.9% more successful on the ImageNet dataset, than the next best state-of-the-art attack. We confirm using statistical tests that our attack outperforms state-of-the-art attacks on different datasets and values of $\epsilon$ and against different defenses.