 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Gradient Descent: A Powerful and Principled Evasion Attack Against Neural Networks
Paper and Code
Dec 28, 2021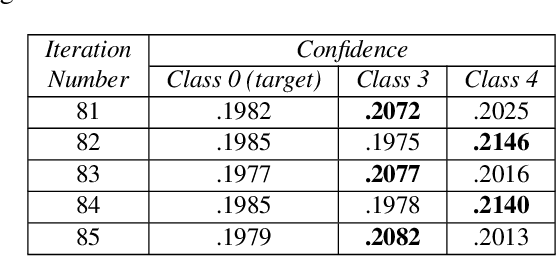
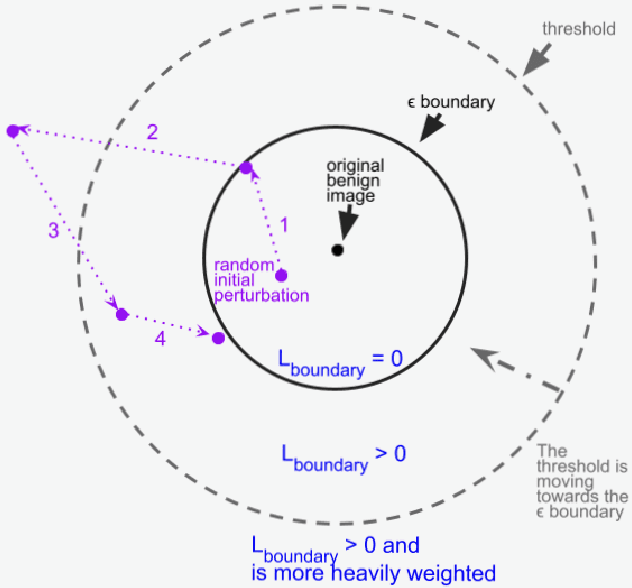
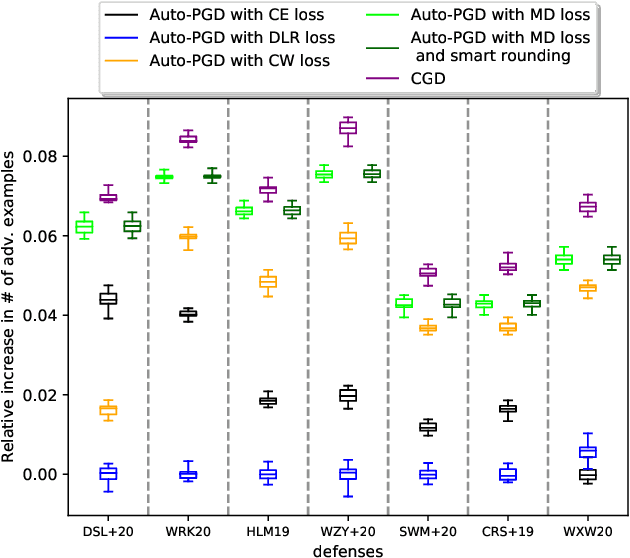
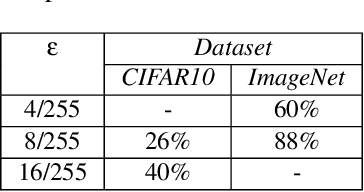
Minimal adversarial perturbations added to inputs have been shown to be effective at fooling deep neural networks. In this paper, we introduce several innovations that make white-box targeted attacks follow the intuition of the attacker's goal: to trick the model to assign a higher probability to the target class than to any other, while staying within a specified distance from the original input. First, we propose a new loss function that explicitly captures the goal of targeted attacks, in particular, by using the logits of all classes instead of just a subset, as is common. We show that Auto-PGD with this loss function finds more adversarial examples than it does with other commonly used loss functions. Second, we propose a new attack method that uses a further developed version of our loss function capturing both the misclassification objective and the $L_{\infty}$ distance limit $\epsilon$. This new attack method is relatively 1.5--4.2% more successful on the CIFAR10 dataset and relatively 8.2--14.9% more successful on the ImageNet dataset, than the next best state-of-the-art attack. We confirm using statistical tests that our attack outperforms state-of-the-art attacks on different datasets and values of $\epsilon$ and against different defenses.