 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Estimation for Binary Latent Variables via Gradient Variance Clipping
Aug 12, 2022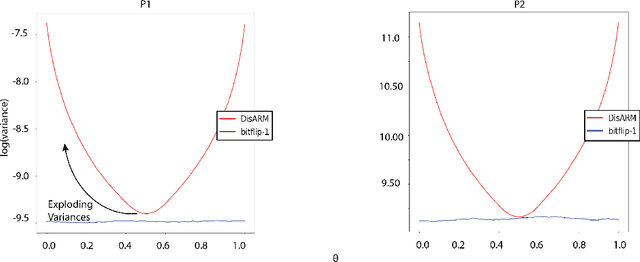
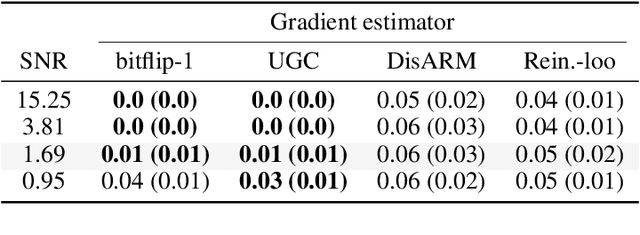
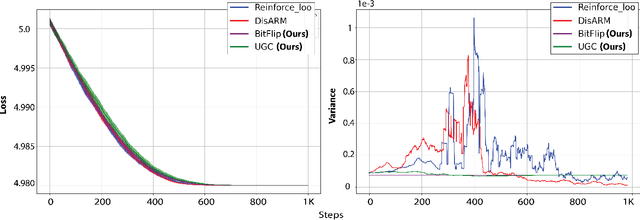
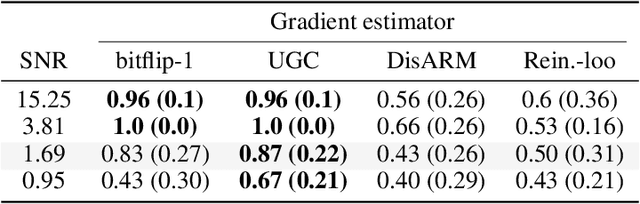
Gradient estimation is often necessary for fitting generative models with discrete latent variables, in contexts such as reinforcement learning and variational autoencoder (VAE) training. The DisARM estimator (Yin et al. 2020; Dong, Mnih, and Tucker 2020) achieves state of the art gradient variance for Bernoulli latent variable models in many contexts. However, DisARM and other estimators have potentially exploding variance near the boundary of the parameter space, where solutions tend to lie. To ameliorate this issue, we propose a new gradient estimator \textit{bitflip}-1 that has lower variance at the boundaries of the parameter space. As bitflip-1 has complementary properties to existing estimators, we introduce an aggregated estimator, \textit{unbiased gradient variance clipping} (UGC) that uses either a bitflip-1 or a DisARM gradient update for each coordinate. We theoretically prove that UGC has uniformly lower variance than DisARM. Empirically, we observe that UGC achieves the optimal value of the optimization objectives in toy experiments, discrete VAE training, and in a best subset selection problem.
Sparse Partitioning: Nonlinear regression with binary or tertiary predictors, with application to association studies
Aug 30, 2011
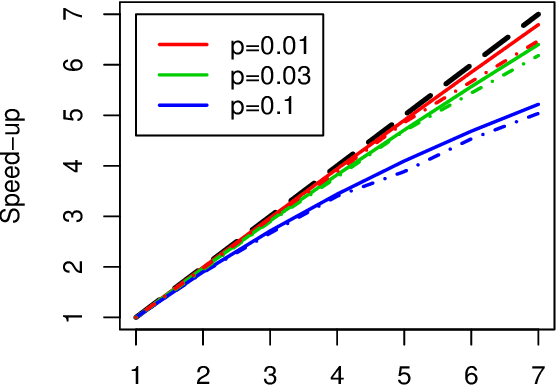
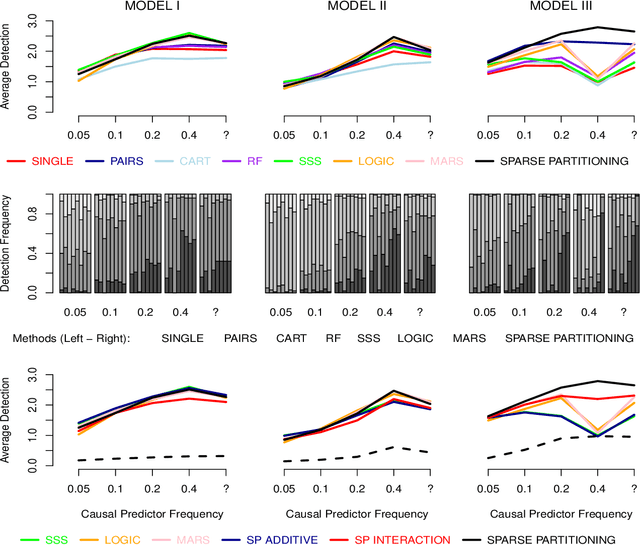
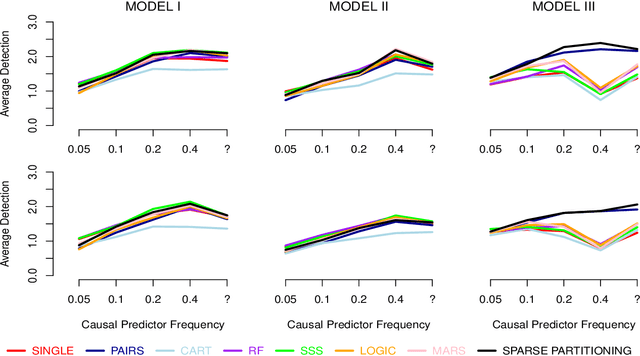
This paper presents Sparse Partitioning, a Bayesian method for identifying predictors that either individually or in combination with others affect a response variable. The method is designed for regression problems involving binary or tertiary predictors and allows the number of predictors to exceed the size of the sample, two properties which make it well suited for association studies. Sparse Partitioning differs from other regression methods by placing no restrictions on how the predictors may influence the response. To compensate for this generality, Sparse Partitioning implements a novel way of exploring the model space. It searches for high posterior probability partitions of the predictor set, where each partition defines groups of predictors that jointly influence the response. The result is a robust method that requires no prior knowledge of the true predictor--response relationship. Testing on simulated data suggests Sparse Partitioning will typically match the performance of an existing method on a data set which obeys the existing method's model assumptions. When these assumptions are violated, Sparse Partitioning will generally offer superior performance.
* Published in at http://dx.doi.org/10.1214/10-AOAS411 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)