 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould I send this notification? Optimizing push notifications decision making by modeling the future
Feb 17, 2022Most recommender systems are myopic, that is they optimize based on the immediate response of the user. This may be misaligned with the true objective, such as creating long term user satisfaction. In this work we focus on mobile push notifications, where the long term effects of recommender system decisions can be particularly strong. For example, sending too many or irrelevant notifications may annoy a user and cause them to disable notifications. However, a myopic system will always choose to send a notification since negative effects occur in the future. This is typically mitigated using heuristics. However, heuristics can be hard to reason about or improve, require retuning each time the system is changed, and may be suboptimal. To counter these drawbacks, there is significant interest in recommender systems that optimize directly for long-term value (LTV). Here, we describe a method for maximising LTV by using model-based reinforcement learning (RL) to make decisions about whether to send push notifications. We model the effects of sending a notification on the user's future behavior. Much of the prior work applying RL to maximise LTV in recommender systems has focused on session-based optimization, while the time horizon for notification decision making in this work extends over several days. We test this approach in an A/B test on a major social network. We show that by optimizing decisions about push notifications we are able to send less notifications and obtain a higher open rate than the baseline system, while generating the same level of user engagement on the platform as the existing, heuristic-based, system.
Learning to Rank For Push Notifications Using Pairwise Expected Regret
Jan 19, 2022

Listwise ranking losses have been widely studied in recommender systems. However, new paradigms of content consumption present new challenges for ranking methods. In this work we contribute an analysis of learning to rank for personalized mobile push notifications and discuss the unique challenges this presents compared to traditional ranking problems. To address these challenges, we introduce a novel ranking loss based on weighting the pairwise loss between candidates by the expected regret incurred for misordering the pair. We demonstrate that the proposed method can outperform prior methods both in a simulated environment and in a production experiment on a major social network.
A simple discriminative training method for machine translation with large-scale features
Sep 15, 2019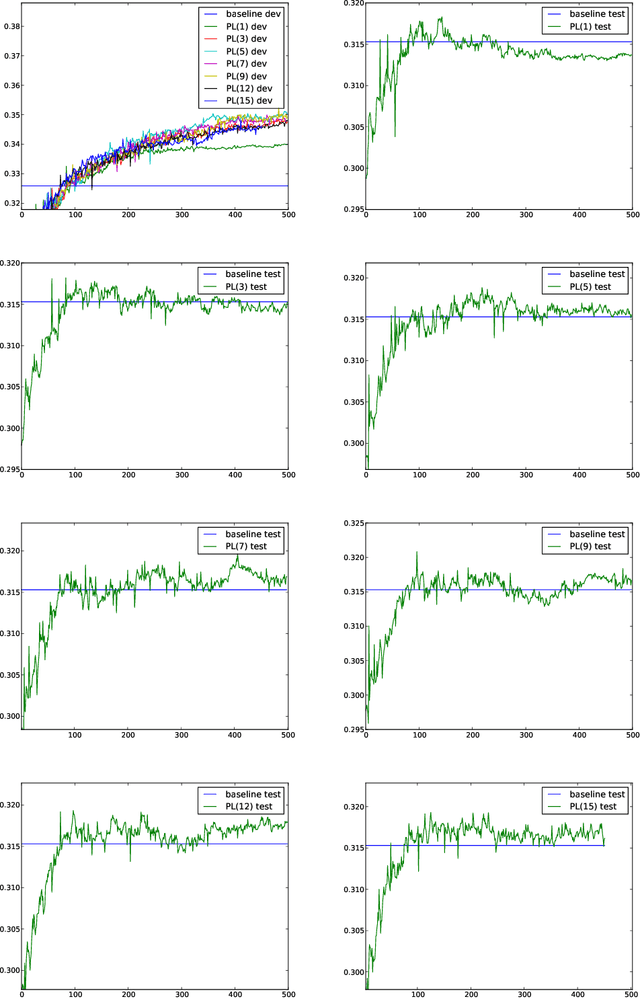
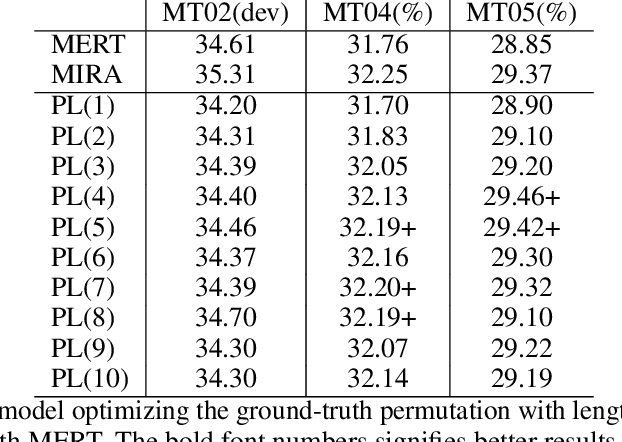
Margin infused relaxed algorithms (MIRAs) dominate model tuning in statistical machine translation in the case of large scale features, but also they are famous for the complexity in implementation. We introduce a new method, which regards an N-best list as a permutation and minimizes the Plackett-Luce loss of ground-truth permutations. Experiments with large-scale features demonstrate that, the new method is more robust than MERT; though it is only matchable with MIRAs, it has a comparatively advantage, easier to implement.
Plackett-Luce model for learning-to-rank task
Sep 15, 2019
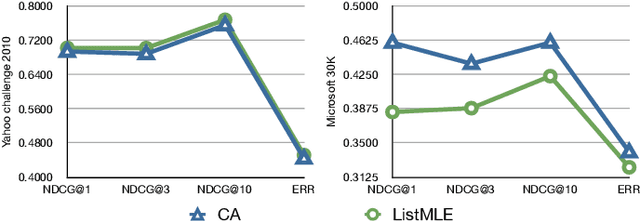

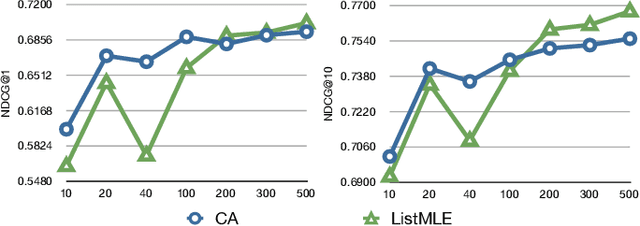
List-wise based learning to rank methods are generally supposed to have better performance than point- and pair-wise based. However, in real-world applications, state-of-the-art systems are not from list-wise based camp. In this paper, we propose a new non-linear algorithm in the list-wise based framework called ListMLE, which uses the Plackett-Luce (PL) loss. Our experiments are conducted on the two largest publicly available real-world datasets, Yahoo challenge 2010 and Microsoft 30K. This is the first time in the single model level for a list-wise based system to match or overpass state-of-the-art systems in real-world datasets.
Analysis of Regression Tree Fitting Algorithms in Learning to Rank
Sep 12, 2019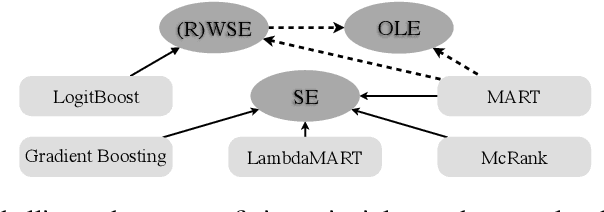
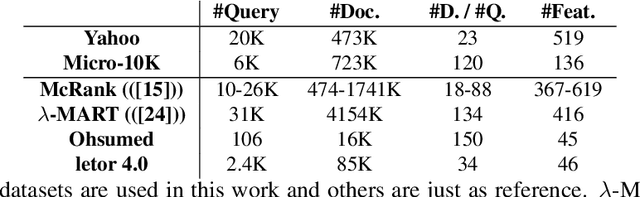
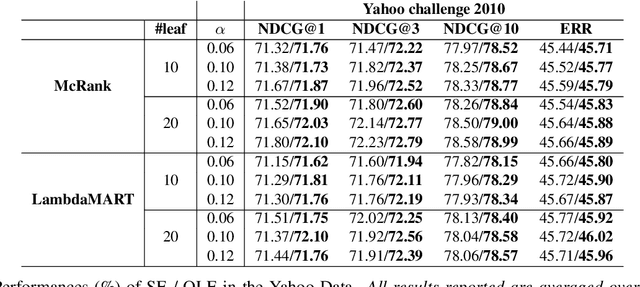
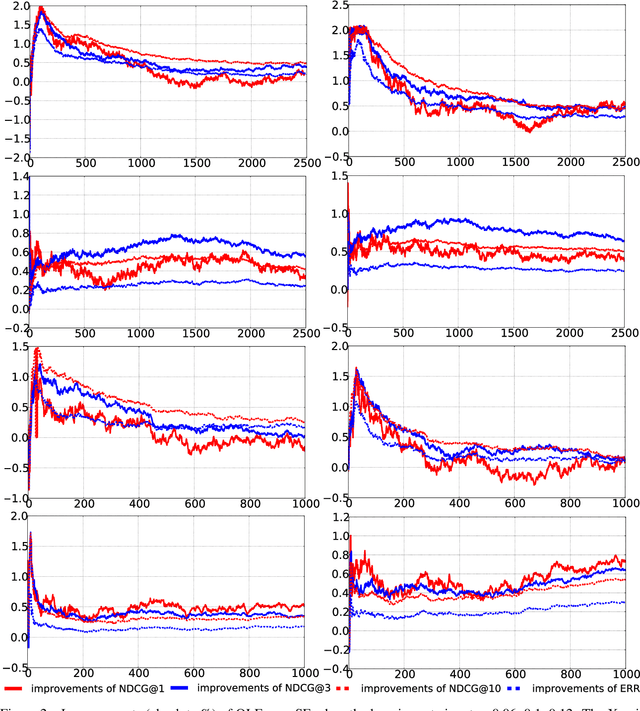
In learning to rank area, industry-level applications have been dominated by gradient boosting framework, which fits a tree using least square error principle. While in classification area, another tree fitting principle, weighted least square error, has been widely used, such as LogitBoost and its variants. However, there is a lack of analysis on the relationship between the two principles in the scenario of learning to rank. We propose a new principle named least objective loss based error that enables us to analyze the issue above as well as several important learning to rank models. We also implement two typical and strong systems and conduct our experiments in two real-world datasets. Experimental results show that our proposed method brings moderate improvements over least square error principle.